 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedundant Sudoku Rules
Jul 25, 2012

The rules of Sudoku are often specified using twenty seven \texttt{all\_different} constraints, referred to as the {\em big} \mrules. Using graphical proofs and exploratory logic programming, the following main and new result is obtained: many subsets of six of these big \mrules are redundant (i.e., they are entailed by the remaining twenty one \mrules), and six is maximal (i.e., removing more than six \mrules is not possible while maintaining equivalence). The corresponding result for binary inequality constraints, referred to as the {\em small} \mrules, is stated as a conjecture.
On the Implementation of the Probabilistic Logic Programming Language ProbLog
Jun 23, 2010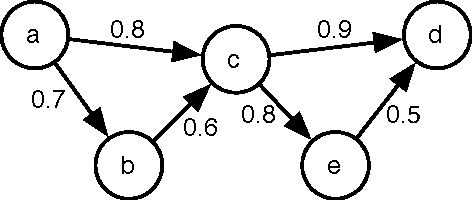
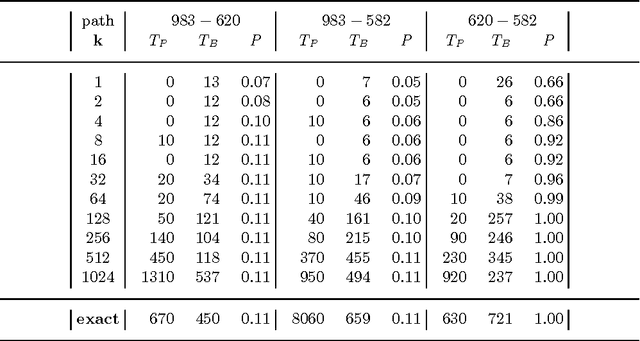


The past few years have seen a surge of interest in the field of probabilistic logic learning and statistical relational learning. In this endeavor, many probabilistic logics have been developed. ProbLog is a recent probabilistic extension of Prolog motivated by the mining of large biological networks. In ProbLog, facts can be labeled with probabilities. These facts are treated as mutually independent random variables that indicate whether these facts belong to a randomly sampled program. Different kinds of queries can be posed to ProbLog programs. We introduce algorithms that allow the efficient execution of these queries, discuss their implementation on top of the YAP-Prolog system, and evaluate their performance in the context of large networks of biological entities.
* 28 pages; To appear in Theory and Practice of Logic Programming (TPLP)
Fast Frequent Querying with Lazy Control Flow Compilation
Jan 16, 2006
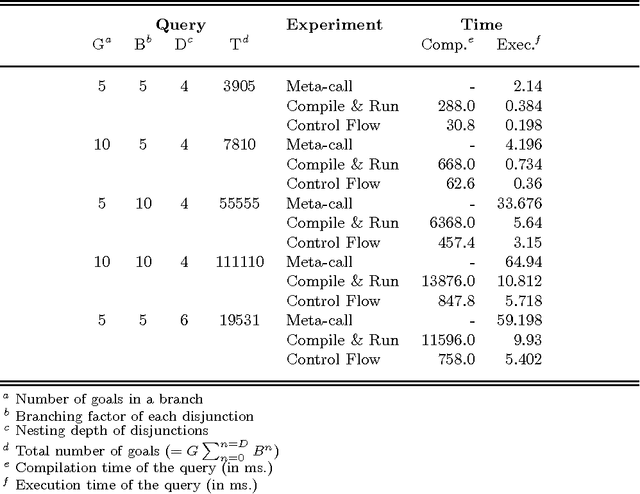

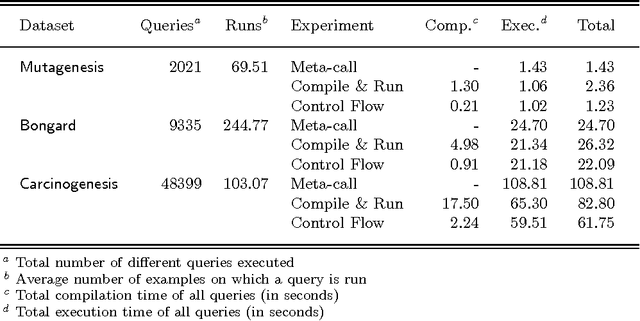
Control flow compilation is a hybrid between classical WAM compilation and meta-call, limited to the compilation of non-recursive clause bodies. This approach is used successfully for the execution of dynamically generated queries in an inductive logic programming setting (ILP). Control flow compilation reduces compilation times up to an order of magnitude, without slowing down execution. A lazy variant of control flow compilation is also presented. By compiling code by need, it removes the overhead of compiling unreached code (a frequent phenomenon in practical ILP settings), and thus reduces the size of the compiled code. Both dynamic compilation approaches have been implemented and were combined with query packs, an efficient ILP execution mechanism. It turns out that locality of data and code is important for performance. The experiments reported in the paper show that lazy control flow compilation is superior in both artificial and real life settings.
Scaling Up Inductive Logic Programming by Learning from Interpretations
Nov 29, 2000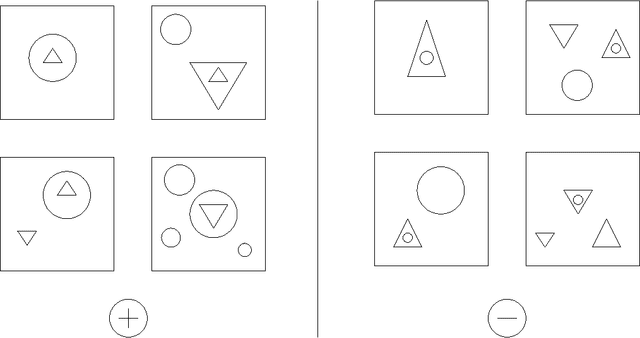



When comparing inductive logic programming (ILP) and attribute-value learning techniques, there is a trade-off between expressive power and efficiency. Inductive logic programming techniques are typically more expressive but also less efficient. Therefore, the data sets handled by current inductive logic programming systems are small according to general standards within the data mining community. The main source of inefficiency lies in the assumption that several examples may be related to each other, so they cannot be handled independently. Within the learning from interpretations framework for inductive logic programming this assumption is unnecessary, which allows to scale up existing ILP algorithms. In this paper we explain this learning setting in the context of relational databases. We relate the setting to propositional data mining and to the classical ILP setting, and show that learning from interpretations corresponds to learning from multiple relations and thus extends the expressiveness of propositional learning, while maintaining its efficiency to a large extent (which is not the case in the classical ILP setting). As a case study, we present two alternative implementations of the ILP system Tilde (Top-down Induction of Logical DEcision trees): Tilde-classic, which loads all data in main memory, and Tilde-LDS, which loads the examples one by one. We experimentally compare the implementations, showing Tilde-LDS can handle large data sets (in the order of 100,000 examples or 100 MB) and indeed scales up linearly in the number of examples.
* 37 pages