 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Logic Programming: A Sequel
Nov 22, 2021
Multi-core and highly-connected architectures have become ubiquitous, and this has brought renewed interest in language-based approaches to the exploitation of parallelism. Since its inception, logic programming has been recognized as a programming paradigm with great potential for automated exploitation of parallelism. The comprehensive survey of the first twenty years of research in parallel logic programming, published in 2001, has served since as a fundamental reference to researchers and developers. The contents are quite valid today, but at the same time the field has continued evolving at a fast pace in the years that have followed. Many of these achievements and ongoing research have been driven by the rapid pace of technological innovation, that has led to advances such as very large clusters, the wide diffusion of multi-core processors, the game-changing role of general-purpose graphic processing units, and the ubiquitous adoption of cloud computing. This has been paralleled by significant advances within logic programming, such as tabling, more powerful static analysis and verification, the rapid growth of Answer Set Programming, and in general, more mature implementations and systems. This survey provides a review of the research in parallel logic programming covering the period since 2001, thus providing a natural continuation of the previous survey. The goal of the survey is to serve not only as a reference for researchers and developers of logic programming systems, but also as engaging reading for anyone interested in logic and as a useful source for researchers in parallel systems outside logic programming. Under consideration in Theory and Practice of Logic Programming (TPLP).
Accelerating GAN training using highly parallel hardware on public cloud
Nov 08, 2021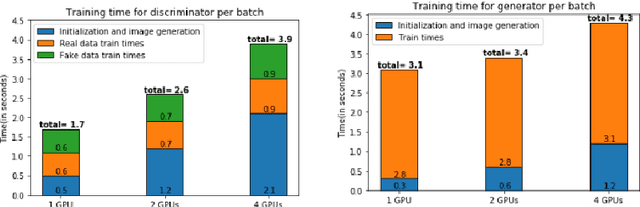
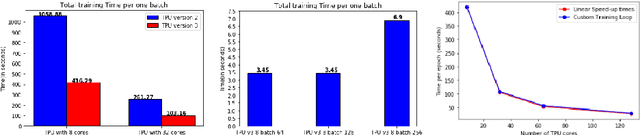
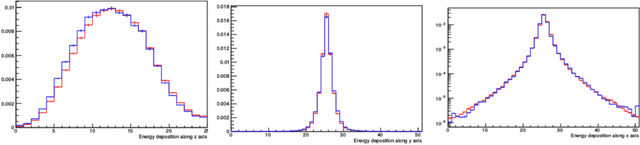
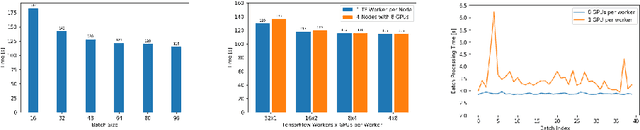
With the increasing number of Machine and Deep Learning applications in High Energy Physics, easy access to dedicated infrastructure represents a requirement for fast and efficient R&D. This work explores different types of cloud services to train a Generative Adversarial Network (GAN) in a parallel environment, using Tensorflow data parallel strategy. More specifically, we parallelize the training process on multiple GPUs and Google Tensor Processing Units (TPU) and we compare two algorithms: the TensorFlow built-in logic and a custom loop, optimised to have higher control of the elements assigned to each GPU worker or TPU core. The quality of the generated data is compared to Monte Carlo simulation. Linear speed-up of the training process is obtained, while retaining most of the performance in terms of physics results. Additionally, we benchmark the aforementioned approaches, at scale, over multiple GPU nodes, deploying the training process on different public cloud providers, seeking for overall efficiency and cost-effectiveness. The combination of data science, cloud deployment options and associated economics allows to burst out heterogeneously, exploring the full potential of cloud-based services.
SkILL - a Stochastic Inductive Logic Learner
Jun 02, 2015



Probabilistic Inductive Logic Programming (PILP) is a rel- atively unexplored area of Statistical Relational Learning which extends classic Inductive Logic Programming (ILP). This work introduces SkILL, a Stochastic Inductive Logic Learner, which takes probabilistic annotated data and produces First Order Logic theories. Data in several domains such as medicine and bioinformatics have an inherent degree of uncer- tainty, that can be used to produce models closer to reality. SkILL can not only use this type of probabilistic data to extract non-trivial knowl- edge from databases, but it also addresses efficiency issues by introducing a novel, efficient and effective search strategy to guide the search in PILP environments. The capabilities of SkILL are demonstrated in three dif- ferent datasets: (i) a synthetic toy example used to validate the system, (ii) a probabilistic adaptation of a well-known biological metabolism ap- plication, and (iii) a real world medical dataset in the breast cancer domain. Results show that SkILL can perform as well as a deterministic ILP learner, while also being able to incorporate probabilistic knowledge that would otherwise not be considered.
On the Implementation of the Probabilistic Logic Programming Language ProbLog
Jun 23, 2010
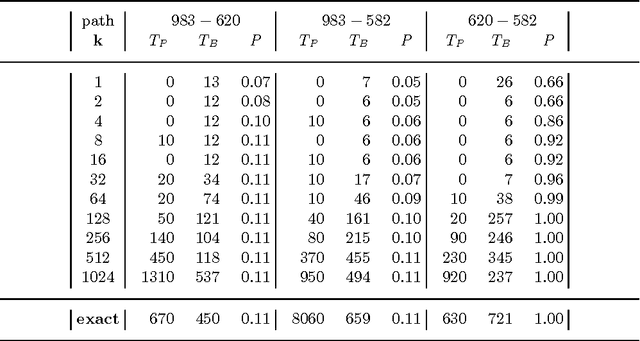


The past few years have seen a surge of interest in the field of probabilistic logic learning and statistical relational learning. In this endeavor, many probabilistic logics have been developed. ProbLog is a recent probabilistic extension of Prolog motivated by the mining of large biological networks. In ProbLog, facts can be labeled with probabilities. These facts are treated as mutually independent random variables that indicate whether these facts belong to a randomly sampled program. Different kinds of queries can be posed to ProbLog programs. We introduce algorithms that allow the efficient execution of these queries, discuss their implementation on top of the YAP-Prolog system, and evaluate their performance in the context of large networks of biological entities.
* 28 pages; To appear in Theory and Practice of Logic Programming (TPLP)