 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-wise Uncertainty for Class Imbalance in Semantic Segmentation
Jul 17, 2024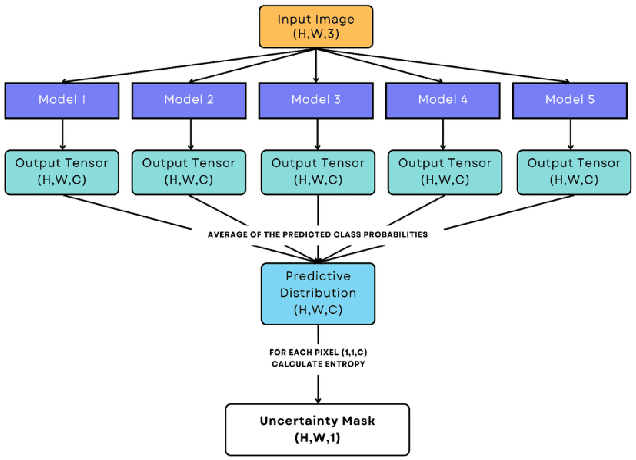



Semantic segmentation is a fundamental computer vision task with a vast number of applications. State of the art methods increasingly rely on deep learning models, known to incorrectly estimate uncertainty and being overconfident in predictions, especially in data not seen during training. This is particularly problematic in semantic segmentation due to inherent class imbalance. Popular uncertainty quantification approaches are task-agnostic and fail to leverage spatial pixel correlations in uncertainty estimates, crucial in this task. In this work, a novel training methodology specifically designed for semantic segmentation is presented. Training samples are weighted by instance-wise uncertainty masks computed by an ensemble. This is shown to increase performance on minority classes, boost model generalization and robustness to domain-shift when compared to using the inverse of class proportions or no class weights at all. This method addresses the challenges of class imbalance and uncertainty estimation in semantic segmentation, potentially enhancing model performance and reliability across various applications.
Program Synthesis using Inductive Logic Programming for the Abstraction and Reasoning Corpus
May 10, 2024The Abstraction and Reasoning Corpus (ARC) is a general artificial intelligence benchmark that is currently unsolvable by any Machine Learning method, including Large Language Models (LLMs). It demands strong generalization and reasoning capabilities which are known to be weaknesses of Neural Network based systems. In this work, we propose a Program Synthesis system that uses Inductive Logic Programming (ILP), a branch of Symbolic AI, to solve ARC. We have manually defined a simple Domain Specific Language (DSL) that corresponds to a small set of object-centric abstractions relevant to ARC. This is the Background Knowledge used by ILP to create Logic Programs that provide reasoning capabilities to our system. The full system is capable of generalize to unseen tasks, since ILP can create Logic Program(s) from few examples, in the case of ARC: pairs of Input-Output grids examples for each task. These Logic Programs are able to generate Objects present in the Output grid and the combination of these can form a complete program that transforms an Input grid into an Output grid. We randomly chose some tasks from ARC that dont require more than the small number of the Object primitives we implemented and show that given only these, our system can solve tasks that require each, such different reasoning.
HAL 9000: Skynet's Risk Manager
Nov 15, 2023



Intrusion Tolerant Systems (ITSs) are a necessary component for cyber-services/infrastructures. Additionally, as cyberattacks follow a multi-domain attack surface, a similar defensive approach should be applied, namely, the use of an evolving multi-disciplinary solution that combines ITS, cybersecurity and Artificial Intelligence (AI). With the increased popularity of AI solutions, due to Big Data use-case scenarios and decision support and automation scenarios, new opportunities to apply Machine Learning (ML) algorithms have emerged, namely ITS empowerment. Using ML algorithms, an ITS can augment its intrusion tolerance capability, by learning from previous attacks and from known vulnerabilities. As such, this work's contribution is twofold: (1) an ITS architecture (Skynet) based on the state-of-the-art and incorporates new components to increase its intrusion tolerance capability and its adaptability to new adversaries; (2) an improved Risk Manager design that leverages AI to improve ITSs by automatically assessing OS risks to intrusions, and advise with safer configurations. One of the reasons that intrusions are successful is due to bad configurations or slow adaptability to new threats. This can be caused by the dependency that systems have for human intervention. One of the characteristics in Skynet and HAL 9000 design is the removal of human intervention. Being fully automatized lowers the chance of successful intrusions caused by human error. Our experiments using Skynet, shows that HAL is able to choose 15% safer configurations than the state-of-the-art risk manager.
Data and Knowledge for Overtaking Scenarios in Autonomous Driving
May 30, 2023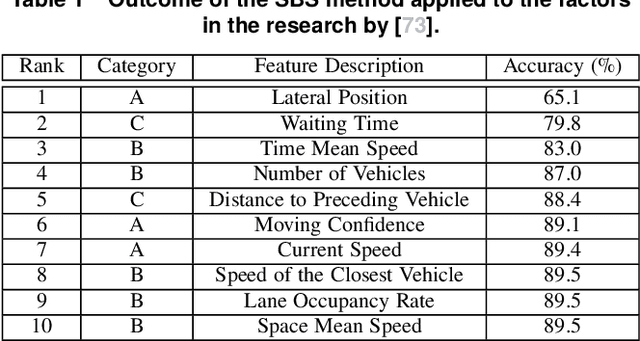

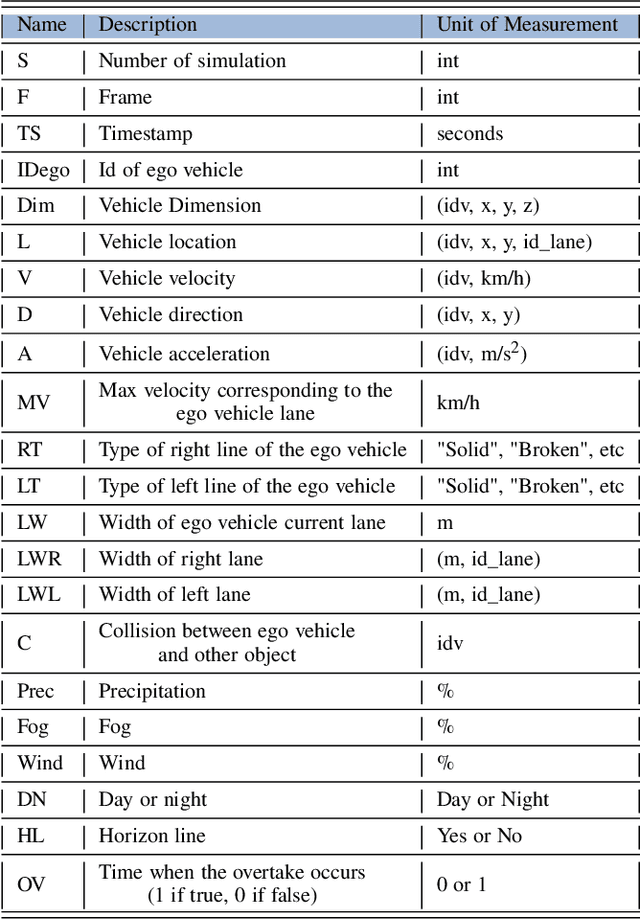
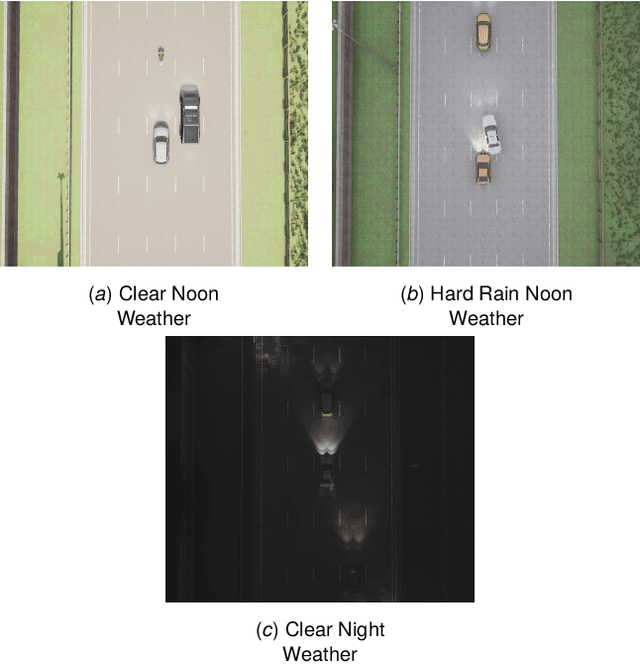
Autonomous driving has become one of the most popular research topics within Artificial Intelligence. An autonomous vehicle is understood as a system that combines perception, decision-making, planning, and control. All of those tasks require that the vehicle collects surrounding data in order to make a good decision and action. In particular, the overtaking maneuver is one of the most critical actions of driving. The process involves lane changes, acceleration and deceleration actions, and estimation of the speed and distance of the vehicle in front or in the lane in which it is moving. Despite the amount of work available in the literature, just a few handle overtaking maneuvers and, because overtaking can be risky, no real-world dataset is available. This work contributes in this area by presenting a new synthetic dataset whose focus is the overtaking maneuver. We start by performing a thorough review of the state of the art in autonomous driving and then explore the main datasets found in the literature (public and private, synthetic and real), highlighting their limitations, and suggesting a new set of features whose focus is the overtaking maneuver.
SkILL - a Stochastic Inductive Logic Learner
Jun 02, 2015



Probabilistic Inductive Logic Programming (PILP) is a rel- atively unexplored area of Statistical Relational Learning which extends classic Inductive Logic Programming (ILP). This work introduces SkILL, a Stochastic Inductive Logic Learner, which takes probabilistic annotated data and produces First Order Logic theories. Data in several domains such as medicine and bioinformatics have an inherent degree of uncer- tainty, that can be used to produce models closer to reality. SkILL can not only use this type of probabilistic data to extract non-trivial knowl- edge from databases, but it also addresses efficiency issues by introducing a novel, efficient and effective search strategy to guide the search in PILP environments. The capabilities of SkILL are demonstrated in three dif- ferent datasets: (i) a synthetic toy example used to validate the system, (ii) a probabilistic adaptation of a well-known biological metabolism ap- plication, and (iii) a real world medical dataset in the breast cancer domain. Results show that SkILL can perform as well as a deterministic ILP learner, while also being able to incorporate probabilistic knowledge that would otherwise not be considered.
ExpertBayes: Automatically refining manually built Bayesian networks
Jun 10, 2014Bayesian network structures are usually built using only the data and starting from an empty network or from a naive Bayes structure. Very often, in some domains, like medicine, a prior structure knowledge is already known. This structure can be automatically or manually refined in search for better performance models. In this work, we take Bayesian networks built by specialists and show that minor perturbations to this original network can yield better classifiers with a very small computational cost, while maintaining most of the intended meaning of the original model.
SPPAM - Statistical PreProcessing AlgorithM
Mar 11, 2011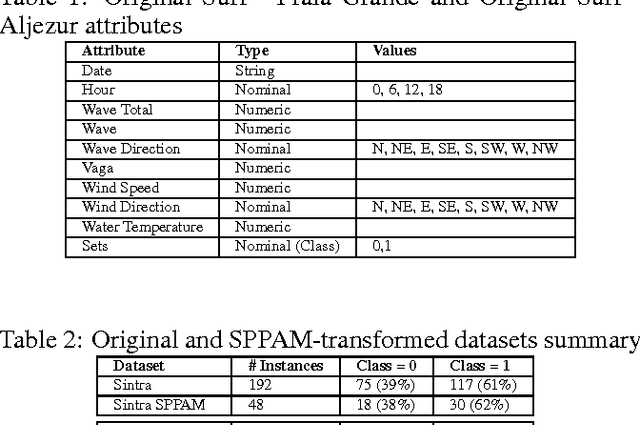

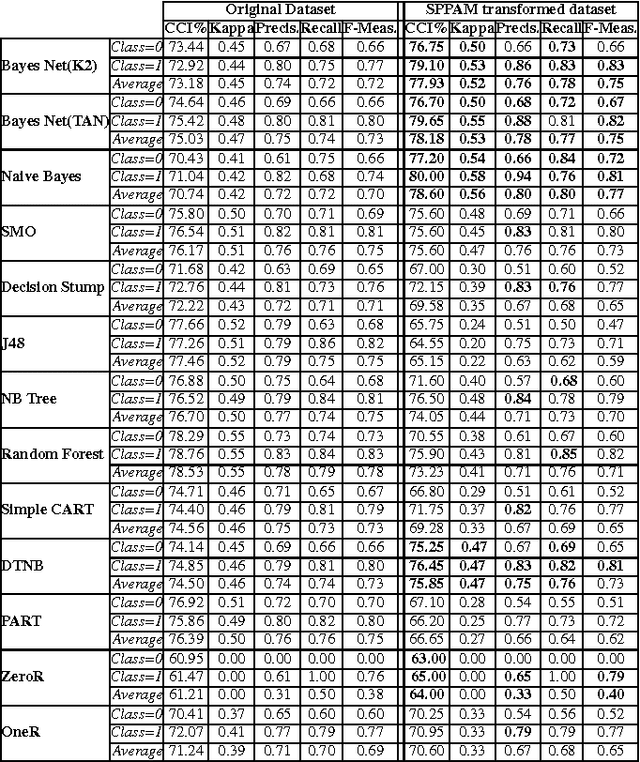
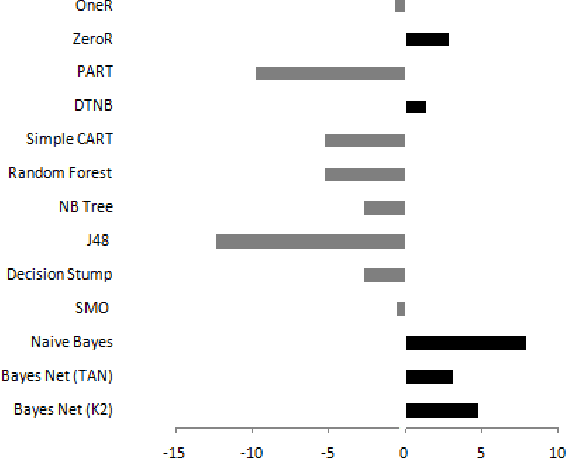
Most machine learning tools work with a single table where each row is an instance and each column is an attribute. Each cell of the table contains an attribute value for an instance. This representation prevents one important form of learning, which is, classification based on groups of correlated records, such as multiple exams of a single patient, internet customer preferences, weather forecast or prediction of sea conditions for a given day. To some extent, relational learning methods, such as inductive logic programming, can capture this correlation through the use of intensional predicates added to the background knowledge. In this work, we propose SPPAM, an algorithm that aggregates past observations in one single record. We show that applying SPPAM to the original correlated data, before the learning task, can produce classifiers that are better than the ones trained using all records.