 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Hierarchical Reinforcement Learning via Variational Quantum Circuits
May 05, 2026Reinforcement learning is one of the most challenging learning paradigms where efficacy and efficiency gains are extremely valuable. Hierarchical reinforcement learning is a variant that leverages temporal abstraction to structure decision-making. While parametrized quantum computations have shown success in non-hierarchical reinforcement learning, whether these advantages adapt to hierarchical decision-making remains a critical open question. In this work, we develop a hybrid hierarchical agent based on the option-critic architecture. This hybrid agent substitutes classical components with variational quantum circuits for feature extractors, option-value functions, termination functions, and intra-option policies. Evaluated on standard benchmarking environments, results show that a hybrid agent utilizing a quantum feature extractor can outperform classical baselines while saving up to 66\% trainable parameters. We also identify an architectural bottleneck that quantum option-value estimation severely degrades performance. Further ablation studies reveal how architectural choices of the quantum circuits affect performance. Our work establishes design principles for parameter-efficient hybrid hierarchical agents.
Unveiling the Latent Directions of Reflection in Large Language Models
Aug 23, 2025Reflection, the ability of large language models (LLMs) to evaluate and revise their own reasoning, has been widely used to improve performance on complex reasoning tasks. Yet, most prior work emphasizes designing reflective prompting strategies or reinforcement learning objectives, leaving the inner mechanisms of reflection underexplored. In this paper, we investigate reflection through the lens of latent directions in model activations. We propose a methodology based on activation steering to characterize how instructions with different reflective intentions: no reflection, intrinsic reflection, and triggered reflection. By constructing steering vectors between these reflection levels, we demonstrate that (1) new reflection-inducing instructions can be systematically identified, (2) reflective behavior can be directly enhanced or suppressed through activation interventions, and (3) suppressing reflection is considerably easier than stimulating it. Experiments on GSM8k-adv with Qwen2.5-3B and Gemma3-4B reveal clear stratification across reflection levels, and steering interventions confirm the controllability of reflection. Our findings highlight both opportunities (e.g., reflection-enhancing defenses) and risks (e.g., adversarial inhibition of reflection in jailbreak attacks). This work opens a path toward mechanistic understanding of reflective reasoning in LLMs.
An Explanation of Intrinsic Self-Correction via Linear Representations and Latent Concepts
May 17, 2025

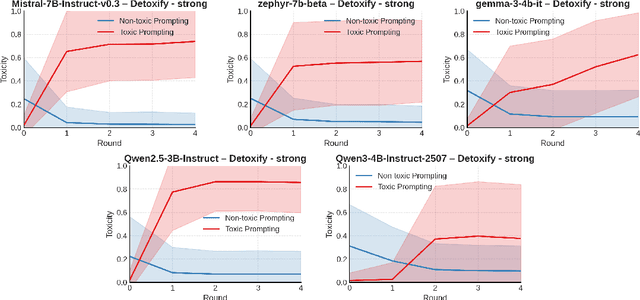

We provide an explanation for the performance gains of intrinsic self-correction, a process where a language model iteratively refines its outputs without external feedback. More precisely, we investigate how prompting induces interpretable changes in hidden states and thus affects the output distributions. We hypothesize that each prompt-induced shift lies in a linear span of some linear representation vectors, naturally separating tokens based on individual concept alignment. Building around this idea, we give a mathematical formulation of self-correction and derive a concentration result for output tokens based on alignment magnitudes. Our experiments on text detoxification with zephyr-7b-sft reveal a substantial gap in the inner products of the prompt-induced shifts and the unembeddings of the top-100 most toxic tokens vs. those of the unembeddings of the bottom-100 least toxic tokens, under toxic instructions. This suggests that self-correction prompts enhance a language model's capability of latent concept recognition. Our analysis offers insights into the underlying mechanism of self-correction by characterizing how prompting works explainably. For reproducibility, our code is available.
Chain-of-Thought Prompting for Out-of-Distribution Samples: A Latent-Variable Study
Apr 17, 2025Chain-of-Thought (CoT) prompting has emerged as a powerful technique to improve in-context learning (ICL) in large language models (LLMs) by breaking complex reasoning into intermediate steps. However, the ability of CoT to generalize under distribution shift remains poorly understood. In this work, we extend a latent-variable framework for CoT prompting and study its behavior on two prototypical out-of-distribution (OOD) scenarios: (i) the latent variables for CoT steps are permuted into novel combinations, and (ii) the latent variables uniformly scaled by a factor. Our experiments demonstrate that CoT inference generalizes effectively to OOD samples whose latent variables closely resemble those seen during training, but its performance degrades as this similarity decreases. These findings provide foundational insights into the strengths and limitations of CoT prompting under OOD conditions and suggest directions for developing more resilient reasoning strategies in future LLMs.
Unraveling Arithmetic in Large Language Models: The Role of Algebraic Structures
Nov 25, 2024Large language models (LLMs) have demonstrated remarkable mathematical capabilities, largely driven by chain-of-thought (CoT) prompting, which decomposes complex reasoning into step-by-step solutions. This approach has enabled significant advancements, as evidenced by performance on benchmarks like GSM8K and MATH. However, the mechanisms underlying LLMs' ability to perform arithmetic in a single step of CoT remain poorly understood. Existing studies debate whether LLMs encode numerical values or rely on symbolic reasoning, while others explore attention and multi-layered processing in arithmetic tasks. In this work, we propose that LLMs learn arithmetic by capturing algebraic structures, such as \emph{Commutativity} and \emph{Identity} properties. Since these structures are observable through input-output relationships, they can generalize to unseen data. We empirically demonstrate that LLMs can learn algebraic structures using a custom dataset of arithmetic problems. Our findings indicate that leveraging algebraic structures can enhance the LLMs' arithmetic capabilities, offering insights into improving their arithmetic performance.
RL-STaR: Theoretical Analysis of Reinforcement Learning Frameworks for Self-Taught Reasoner
Oct 31, 2024The reasoning abilities of large language models (LLMs) have improved with chain-of-thought (CoT) prompting, allowing models to solve complex tasks in a stepwise manner. However, training CoT capabilities requires detailed reasoning data, which is often scarce. The self-taught reasoner (STaR) framework addresses this by using reinforcement learning to automatically generate reasoning steps, reducing reliance on human-labeled data. Although STaR and its variants have demonstrated empirical success, a theoretical foundation explaining these improvements is lacking. This work provides a theoretical framework for understanding the effectiveness of reinforcement learning on CoT reasoning and STaR. Our contributions are: (1) an analysis of policy improvement, showing why LLM reasoning improves iteratively with STaR; (2) conditions for convergence to an optimal reasoning policy; (3) an examination of STaR's robustness, explaining how it can improve reasoning even when incorporating occasional incorrect steps; and (4) criteria for the quality of pre-trained models necessary to initiate effective reasoning improvement. This framework aims to bridge empirical findings with theoretical insights, advancing reinforcement learning approaches for reasoning in LLMs.
Leveraging Unlabeled Data Sharing through Kernel Function Approximation in Offline Reinforcement Learning
Aug 22, 2024
Offline reinforcement learning (RL) learns policies from a fixed dataset, but often requires large amounts of data. The challenge arises when labeled datasets are expensive, especially when rewards have to be provided by human labelers for large datasets. In contrast, unlabelled data tends to be less expensive. This situation highlights the importance of finding effective ways to use unlabelled data in offline RL, especially when labelled data is limited or expensive to obtain. In this paper, we present the algorithm to utilize the unlabeled data in the offline RL method with kernel function approximation and give the theoretical guarantee. We present various eigenvalue decay conditions of $\mathcal{H}_k$ which determine the complexity of the algorithm. In summary, our work provides a promising approach for exploiting the advantages offered by unlabeled data in offline RL, whilst maintaining theoretical assurances.
Sample Complexity of Kernel-Based Q-Learning
Feb 01, 2023Modern reinforcement learning (RL) often faces an enormous state-action space. Existing analytical results are typically for settings with a small number of state-actions, or simple models such as linearly modeled Q-functions. To derive statistically efficient RL policies handling large state-action spaces, with more general Q-functions, some recent works have considered nonlinear function approximation using kernel ridge regression. In this work, we derive sample complexities for kernel based Q-learning when a generative model exists. We propose a nonparametric Q-learning algorithm which finds an $\epsilon$-optimal policy in an arbitrarily large scale discounted MDP. The sample complexity of the proposed algorithm is order optimal with respect to $\epsilon$ and the complexity of the kernel (in terms of its information gain). To the best of our knowledge, this is the first result showing a finite sample complexity under such a general model.
Flexible Multiple-Objective Reinforcement Learning for Chip Placement
Apr 13, 2022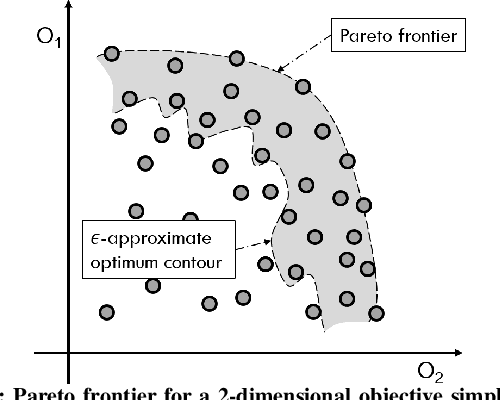
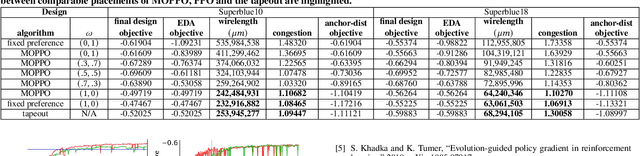
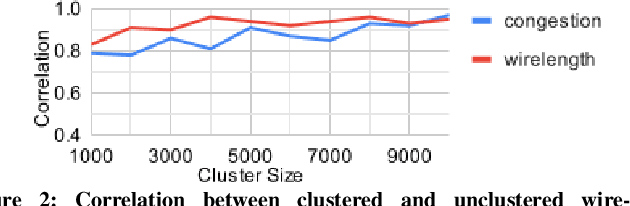

Recently, successful applications of reinforcement learning to chip placement have emerged. Pretrained models are necessary to improve efficiency and effectiveness. Currently, the weights of objective metrics (e.g., wirelength, congestion, and timing) are fixed during pretraining. However, fixed-weighed models cannot generate the diversity of placements required for engineers to accommodate changing requirements as they arise. This paper proposes flexible multiple-objective reinforcement learning (MORL) to support objective functions with inference-time variable weights using just a single pretrained model. Our macro placement results show that MORL can generate the Pareto frontier of multiple objectives effectively.
G2R Bound: A Generalization Bound for Supervised Learning from GAN-Synthetic Data
May 29, 2019
Performing supervised learning from the data synthesized by using Generative Adversarial Networks (GANs), dubbed GAN-synthetic data, has two important applications. First, GANs may generate more labeled training data, which may help improve classification accuracy. Second, in scenarios where real data cannot be released outside certain premises for privacy and/or security reasons, using GAN- synthetic data to conduct training is a plausible alternative. This paper proposes a generalization bound to guarantee the generalization capability of a classifier learning from GAN-synthetic data. This generalization bound helps developers gauge the generalization gap between learning from synthetic data and testing on real data, and can therefore provide the clues to improve the generalization capability.