 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Learn Latent Mixture Models In-Context via Mirror Descent
Apr 12, 2026Sequence modelling requires determining which past tokens are causally relevant from the context and their importance: a process inherent to the attention layers in transformers, yet whose underlying learned mechanisms remain poorly understood. In this work, we formalize the task of estimating token importance as an in-context learning problem by introducing a framework based on Mixture of Transition Distributions, where a latent variable determines the influence of past tokens on the next. The distribution over this latent variable is parameterized by unobserved mixture weights that transformers must learn in-context. We demonstrate that transformers can implement Mirror Descent to learn these weights from the context. Specifically, we give an explicit construction of a three-layer transformer that exactly implements one step of Mirror Descent and prove that the resulting estimator is a first-order approximation of the Bayes-optimal predictor. Corroborating our construction and its learnability via gradient descent, we empirically show that transformers trained from scratch learn solutions consistent with our theory: their predictive distributions, attention patterns, and learned transition matrix closely match the construction, while deeper models achieve performance comparable to multi-step Mirror Descent.
Selective Induction Heads: How Transformers Select Causal Structures In Context
Sep 09, 2025Transformers have exhibited exceptional capabilities in sequence modeling tasks, leveraging self-attention and in-context learning. Critical to this success are induction heads, attention circuits that enable copying tokens based on their previous occurrences. In this work, we introduce a novel framework that showcases transformers' ability to dynamically handle causal structures. Existing works rely on Markov Chains to study the formation of induction heads, revealing how transformers capture causal dependencies and learn transition probabilities in-context. However, they rely on a fixed causal structure that fails to capture the complexity of natural languages, where the relationship between tokens dynamically changes with context. To this end, our framework varies the causal structure through interleaved Markov chains with different lags while keeping the transition probabilities fixed. This setting unveils the formation of Selective Induction Heads, a new circuit that endows transformers with the ability to select the correct causal structure in-context. We empirically demonstrate that transformers learn this mechanism to predict the next token by identifying the correct lag and copying the corresponding token from the past. We provide a detailed construction of a 3-layer transformer to implement the selective induction head, and a theoretical analysis proving that this mechanism asymptotically converges to the maximum likelihood solution. Our findings advance the understanding of how transformers select causal structures, providing new insights into their functioning and interpretability.
Why Do We Need Weight Decay in Modern Deep Learning?
Oct 06, 2023Weight decay is a broadly used technique for training state-of-the-art deep networks, including large language models. Despite its widespread usage, its role remains poorly understood. In this work, we highlight that the role of weight decay in modern deep learning is different from its regularization effect studied in classical learning theory. For overparameterized deep networks, we show how weight decay modifies the optimization dynamics enhancing the ever-present implicit regularization of SGD via the loss stabilization mechanism. In contrast, for underparameterized large language models trained with nearly online SGD, we describe how weight decay balances the bias-variance tradeoff in stochastic optimization leading to lower training loss. Moreover, we show that weight decay also prevents sudden loss divergences for bfloat16 mixed-precision training which is a crucial tool for LLM training. Overall, we present a unifying perspective from ResNets on vision tasks to LLMs: weight decay is never useful as an explicit regularizer but instead changes the training dynamics in a desirable way. Our code is available at https://github.com/tml-epfl/why-weight-decay.
Uncertainty estimation under model misspecification in neural network regression
Nov 23, 2021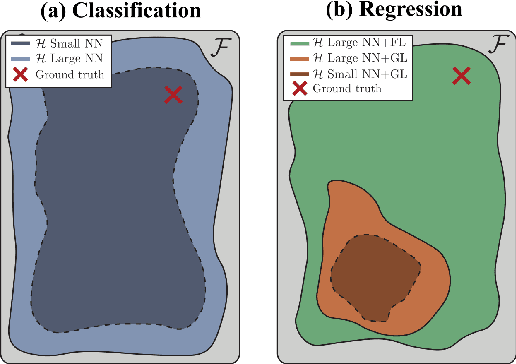
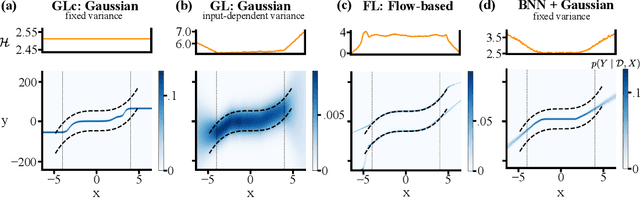

Although neural networks are powerful function approximators, the underlying modelling assumptions ultimately define the likelihood and thus the hypothesis class they are parameterizing. In classification, these assumptions are minimal as the commonly employed softmax is capable of representing any categorical distribution. In regression, however, restrictive assumptions on the type of continuous distribution to be realized are typically placed, like the dominant choice of training via mean-squared error and its underlying Gaussianity assumption. Recently, modelling advances allow to be agnostic to the type of continuous distribution to be modelled, granting regression the flexibility of classification models. While past studies stress the benefit of such flexible regression models in terms of performance, here we study the effect of the model choice on uncertainty estimation. We highlight that under model misspecification, aleatoric uncertainty is not properly captured, and that a Bayesian treatment of a misspecified model leads to unreliable epistemic uncertainty estimates. Overall, our study provides an overview on how modelling choices in regression may influence uncertainty estimation and thus any downstream decision making process.
Uncertainty-based out-of-distribution detection requires suitable function space priors
Oct 12, 2021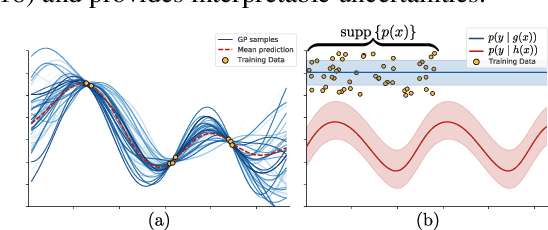

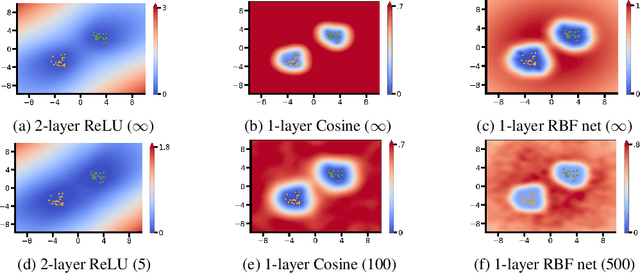
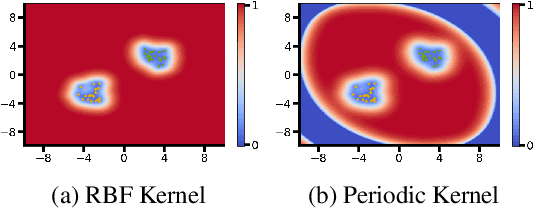
The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNNs) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and show that proper Bayesian inference with function space priors induced by neural networks does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact due to the correspondence with Gaussian processes. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Importantly, we find this OOD behavior to be consistent with the corresponding finite-width networks. Desirable function space properties can be encoded in the prior in weight space, however, this currently only applies to a specified subset of the domain and thus does not inherently extend to OOD data. Finally, we argue that a trade-off between generalization and OOD capabilities might render the application of BNNs for OOD detection undesirable in practice. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
Are Bayesian neural networks intrinsically good at out-of-distribution detection?
Jul 26, 2021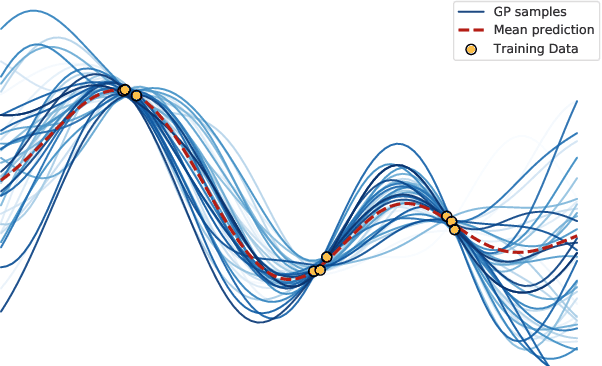

The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNN) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and provide empirical evidence that proper Bayesian inference with common neural network architectures does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact considering the corresponding Gaussian process. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Finally, we study finite-width networks using HMC, and observe OOD behavior that is consistent with the infinite-width case. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
Repulsive Deep Ensembles are Bayesian
Jun 22, 2021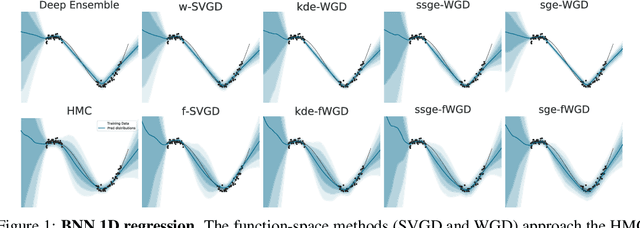

Deep ensembles have recently gained popularity in the deep learning community for their conceptual simplicity and efficiency. However, maintaining functional diversity between ensemble members that are independently trained with gradient descent is challenging. This can lead to pathologies when adding more ensemble members, such as a saturation of the ensemble performance, which converges to the performance of a single model. Moreover, this does not only affect the quality of its predictions, but even more so the uncertainty estimates of the ensemble, and thus its performance on out-of-distribution data. We hypothesize that this limitation can be overcome by discouraging different ensemble members from collapsing to the same function. To this end, we introduce a kernelized repulsive term in the update rule of the deep ensembles. We show that this simple modification not only enforces and maintains diversity among the members but, even more importantly, transforms the maximum a posteriori inference into proper Bayesian inference. Namely, we show that the training dynamics of our proposed repulsive ensembles follow a Wasserstein gradient flow of the KL divergence with the true posterior. We study repulsive terms in weight and function space and empirically compare their performance to standard ensembles and Bayesian baselines on synthetic and real-world prediction tasks.
On Stein Variational Neural Network Ensembles
Jun 22, 2021
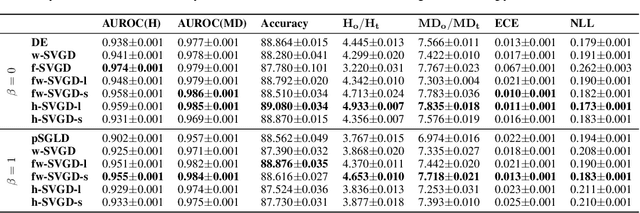
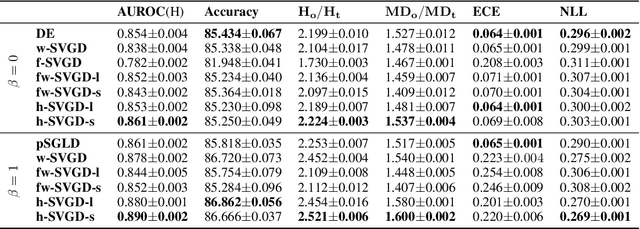
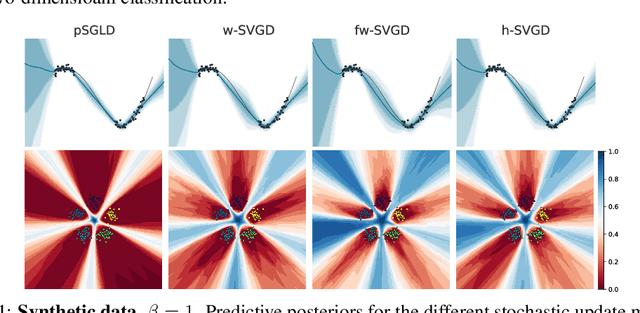
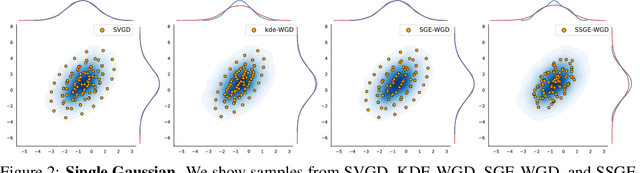
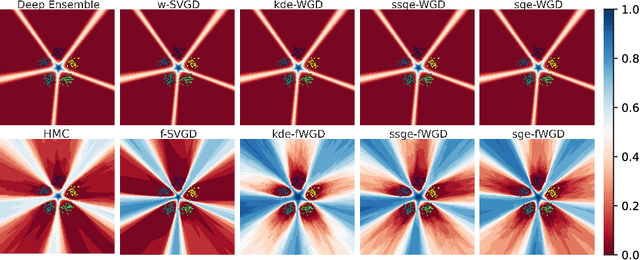
Ensembles of deep neural networks have achieved great success recently, but they do not offer a proper Bayesian justification. Moreover, while they allow for averaging of predictions over several hypotheses, they do not provide any guarantees for their diversity, leading to redundant solutions in function space. In contrast, particle-based inference methods, such as Stein variational gradient descent (SVGD), offer a Bayesian framework, but rely on the choice of a kernel to measure the similarity between ensemble members. In this work, we study different SVGD methods operating in the weight space, function space, and in a hybrid setting. We compare the SVGD approaches to other ensembling-based methods in terms of their theoretical properties and assess their empirical performance on synthetic and real-world tasks. We find that SVGD using functional and hybrid kernels can overcome the limitations of deep ensembles. It improves on functional diversity and uncertainty estimation and approaches the true Bayesian posterior more closely. Moreover, we show that using stochastic SVGD updates, as opposed to the standard deterministic ones, can further improve the performance.
Posterior Meta-Replay for Continual Learning
Mar 01, 2021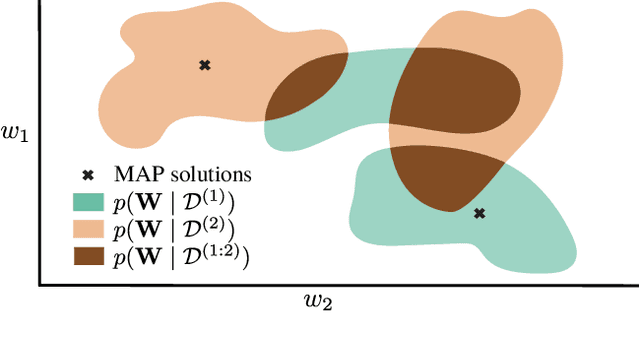
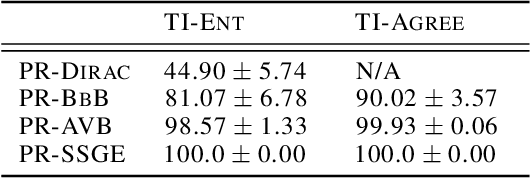
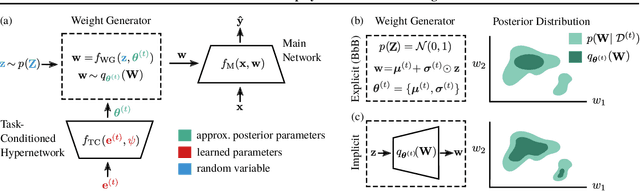
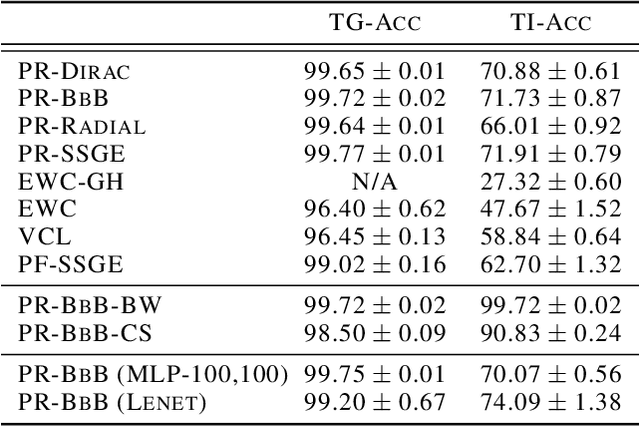
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
Annealed Stein Variational Gradient Descent
Feb 08, 2021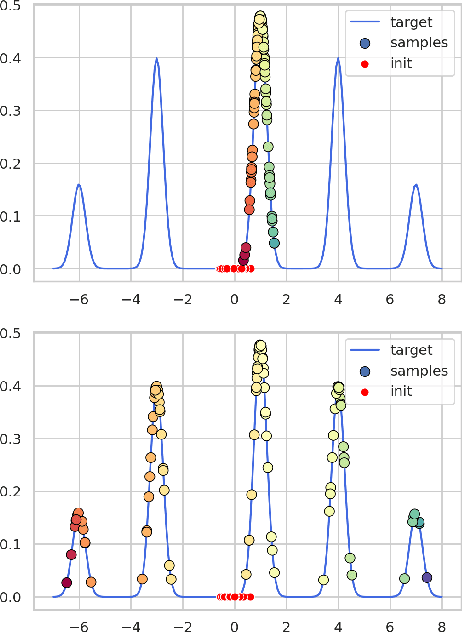

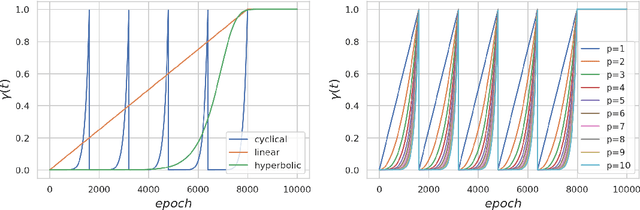
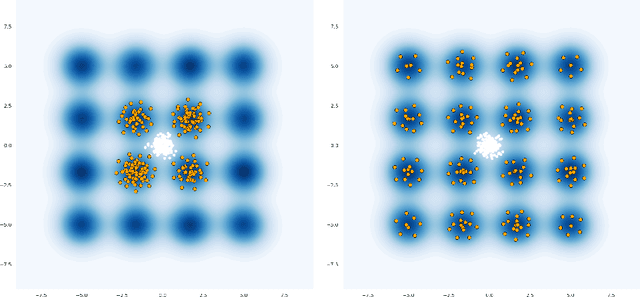
Particle based optimization algorithms have recently been developed as sampling methods that iteratively update a set of particles to approximate a target distribution. In particular Stein variational gradient descent has gained attention in the approximate inference literature for its flexibility and accuracy. We empirically explore the ability of this method to sample from multi-modal distributions and focus on two important issues: (i) the inability of the particles to escape from local modes and (ii) the inefficacy in reproducing the density of the different regions. We propose an annealing schedule to solve these issues and show, through various experiments, how this simple solution leads to significant improvements in mode coverage, without invalidating any theoretical properties of the original algorithm.