 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Graph Convolutional Networks: A unified multi-task and multi-modal learning framework to facilitate health and social-care insights
Mar 27, 2024



This paper introduces a novel Functional Graph Convolutional Network (funGCN) framework that combines Functional Data Analysis and Graph Convolutional Networks to address the complexities of multi-task and multi-modal learning in digital health and longitudinal studies. With the growing importance of health solutions to improve health care and social support, ensure healthy lives, and promote well-being at all ages, funGCN offers a unified approach to handle multivariate longitudinal data for multiple entities and ensures interpretability even with small sample sizes. Key innovations include task-specific embedding components that manage different data types, the ability to perform classification, regression, and forecasting, and the creation of a knowledge graph for insightful data interpretation. The efficacy of funGCN is validated through simulation experiments and a real-data application.
Feature Selection for Functional Data Classification
Jan 11, 2024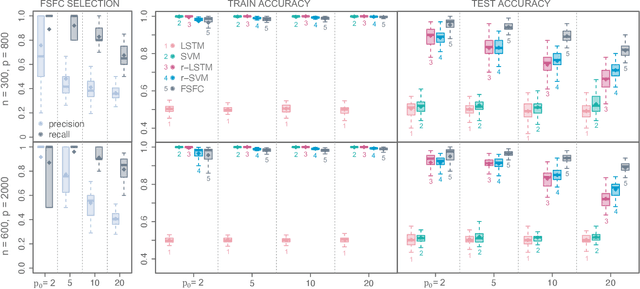
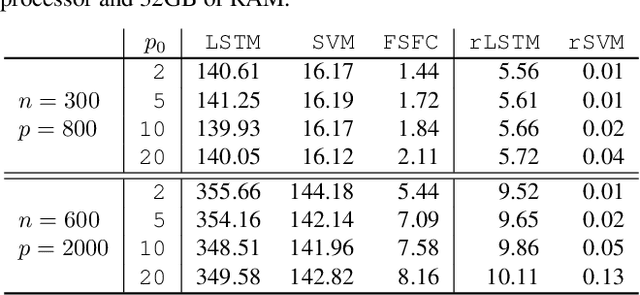
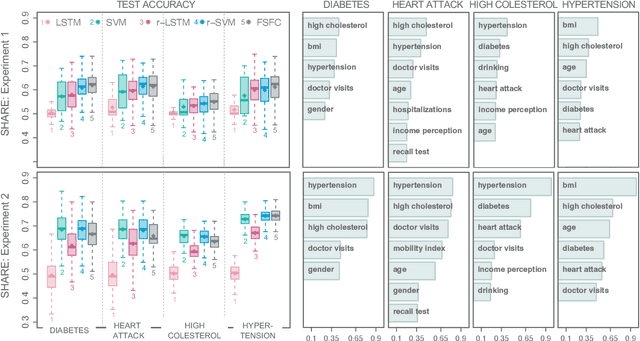
Functional data analysis has emerged as a crucial tool in many contemporary scientific domains that require the integration and interpretation of complex data. Moreover, the advent of new technologies has facilitated the collection of a large number of longitudinal variables, making feature selection pivotal for avoiding overfitting and improving prediction performance. This paper introduces a novel methodology called FSFC (Feature Selection for Functional Classification), that addresses the challenge of jointly performing feature selection and classification of functional data in scenarios with categorical responses and longitudinal features. Our approach tackles a newly defined optimization problem that integrates logistic loss and functional features to identify the most crucial features for classification. To address the minimization procedure, we employ functional principal components and develop a new adaptive version of the Dual Augmented Lagrangian algorithm that leverages the sparsity structure of the problem for dimensionality reduction. The computational efficiency of FSFC enables handling high-dimensional scenarios where the number of features may considerably exceed the number of statistical units. Simulation experiments demonstrate that FSFC outperforms other machine learning and deep learning methods in computational time and classification accuracy. Furthermore, the FSFC feature selection capability can be leveraged to significantly reduce the problem's dimensionality and enhance the performances of other classification algorithms. The efficacy of FSFC is also demonstrated through a real data application, analyzing relationships between four chronic diseases and other health and socio-demographic factors.
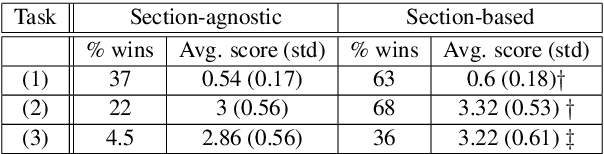
TDMSci: A Specialized Corpus for Scientific Literature Entity Tagging of Tasks Datasets and Metrics
Jan 25, 2021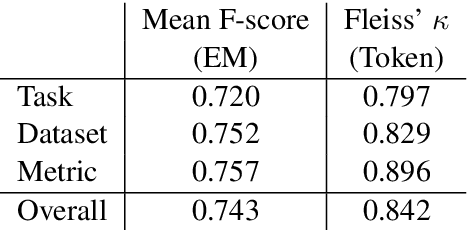
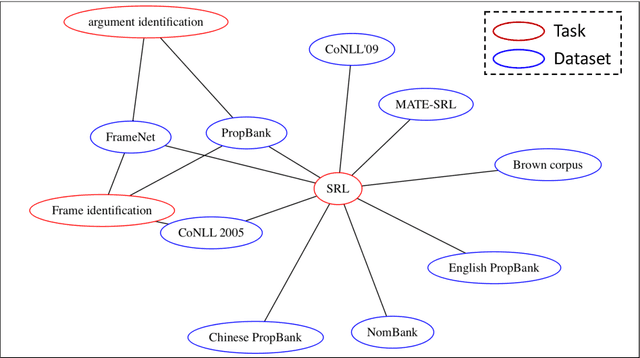
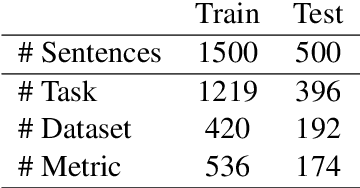
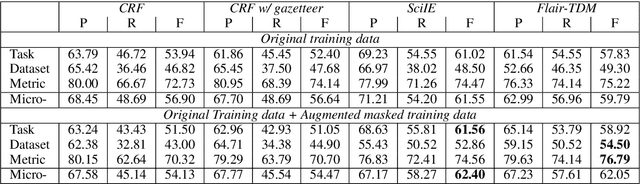
Tasks, Datasets and Evaluation Metrics are important concepts for understanding experimental scientific papers. However, most previous work on information extraction for scientific literature mainly focuses on the abstracts only, and does not treat datasets as a separate type of entity (Zadeh and Schumann, 2016; Luan et al., 2018). In this paper, we present a new corpus that contains domain expert annotations for Task (T), Dataset (D), Metric (M) entities on 2,000 sentences extracted from NLP papers. We report experiment results on TDM extraction using a simple data augmentation strategy and apply our tagger to around 30,000 NLP papers from the ACL Anthology. The corpus is made publicly available to the community for fostering research on scientific publication summarization (Erera et al., 2019) and knowledge discovery.
A Summarization System for Scientific Documents
Aug 29, 2019

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Identification of Tasks, Datasets, Evaluation Metrics, and Numeric Scores for Scientific Leaderboards Construction
Jun 21, 2019

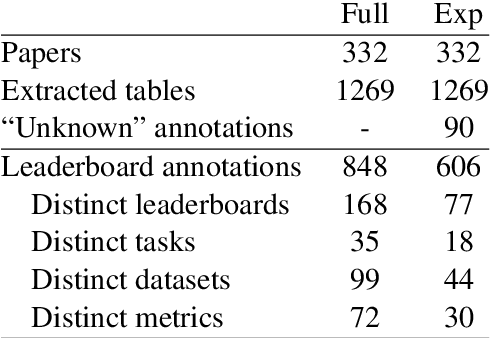
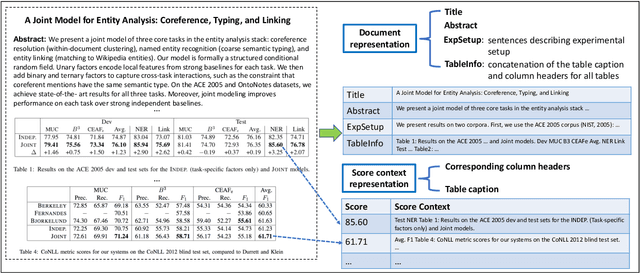
While the fast-paced inception of novel tasks and new datasets helps foster active research in a community towards interesting directions, keeping track of the abundance of research activity in different areas on different datasets is likely to become increasingly difficult. The community could greatly benefit from an automatic system able to summarize scientific results, e.g., in the form of a leaderboard. In this paper we build two datasets and develop a framework (TDMS-IE) aimed at automatically extracting task, dataset, metric and score from NLP papers, towards the automatic construction of leaderboards. Experiments show that our model outperforms several baselines by a large margin. Our model is a first step towards automatic leaderboard construction, e.g., in the NLP domain.
Extracting Factual Min/Max Age Information from Clinical Trial Studies
Apr 05, 2019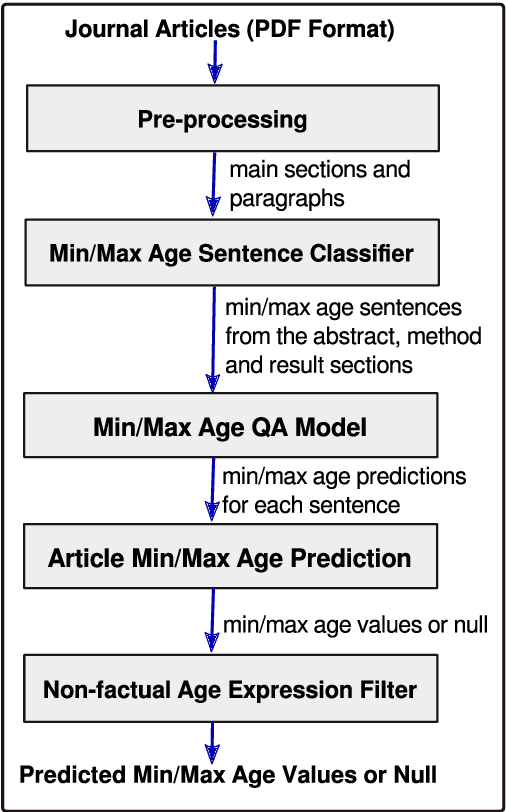
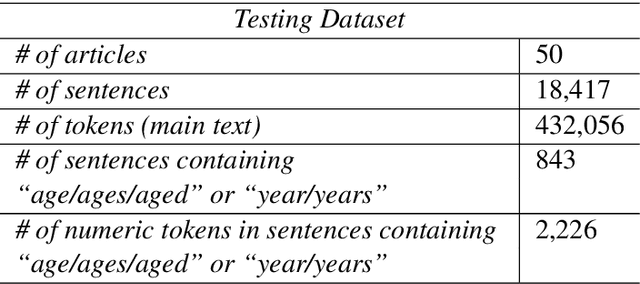
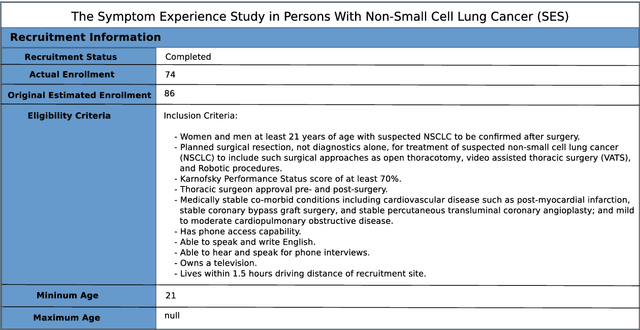
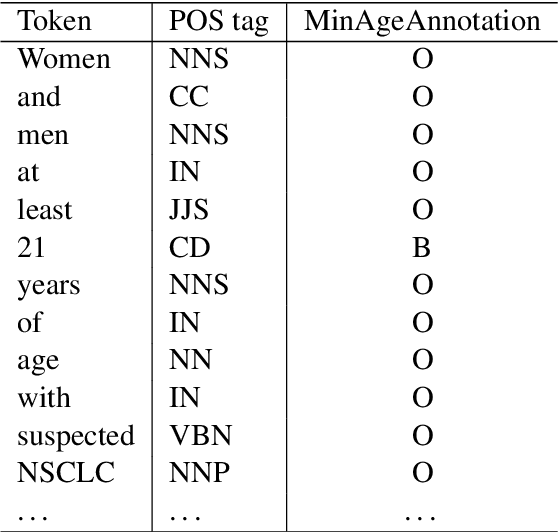
Population age information is an essential characteristic of clinical trials. In this paper, we focus on extracting minimum and maximum (min/max) age values for the study samples from clinical research articles. Specifically, we investigate the use of a neural network model for question answering to address this information extraction task. The min/max age QA model is trained on the massive structured clinical study records from ClinicalTrials.gov. For each article, based on multiple min and max age values extracted from the QA model, we predict both actual min/max age values for the study samples and filter out non-factual age expressions. Our system improves the results over (i) a passage retrieval based IE system and (ii) a CRF-based system by a large margin when evaluated on an annotated dataset consisting of 50 research papers on smoking cessation.