 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End NLP Knowledge Graph Construction
Jun 02, 2021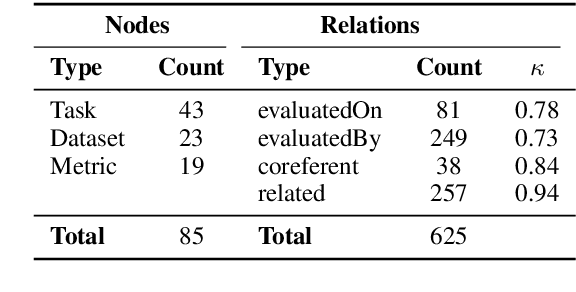
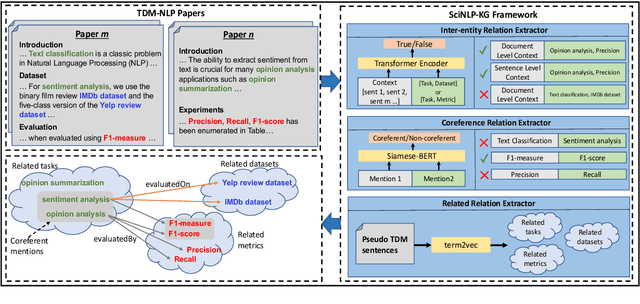

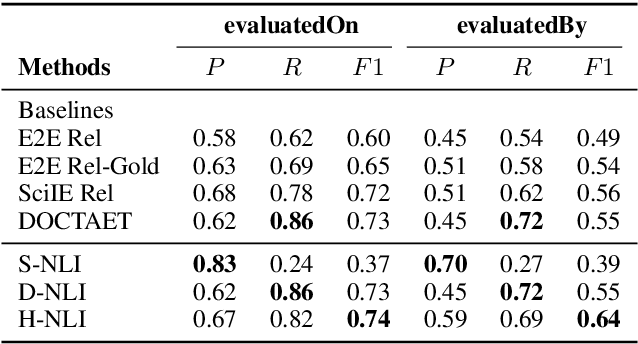
This paper studies the end-to-end construction of an NLP Knowledge Graph (KG) from scientific papers. We focus on extracting four types of relations: evaluatedOn between tasks and datasets, evaluatedBy between tasks and evaluation metrics, as well as coreferent and related relations between the same type of entities. For instance, F1-score is coreferent with F-measure. We introduce novel methods for each of these relation types and apply our final framework (SciNLP-KG) to 30,000 NLP papers from ACL Anthology to build a large-scale KG, which can facilitate automatically constructing scientific leaderboards for the NLP community. The results of our experiments indicate that the resulting KG contains high-quality information.
TDMSci: A Specialized Corpus for Scientific Literature Entity Tagging of Tasks Datasets and Metrics
Jan 25, 2021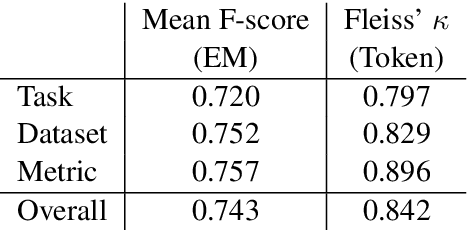
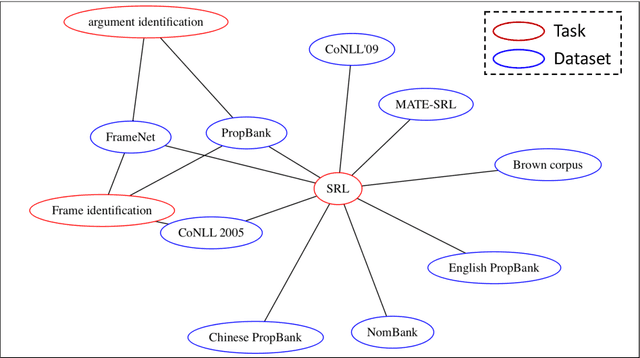
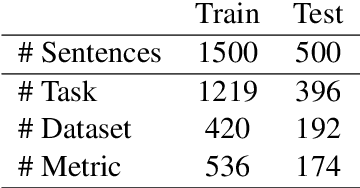
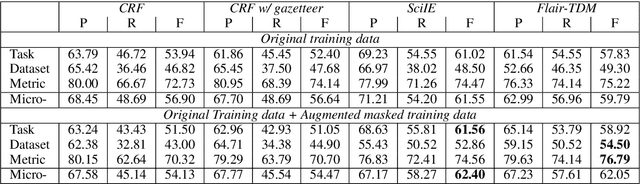
Tasks, Datasets and Evaluation Metrics are important concepts for understanding experimental scientific papers. However, most previous work on information extraction for scientific literature mainly focuses on the abstracts only, and does not treat datasets as a separate type of entity (Zadeh and Schumann, 2016; Luan et al., 2018). In this paper, we present a new corpus that contains domain expert annotations for Task (T), Dataset (D), Metric (M) entities on 2,000 sentences extracted from NLP papers. We report experiment results on TDM extraction using a simple data augmentation strategy and apply our tagger to around 30,000 NLP papers from the ACL Anthology. The corpus is made publicly available to the community for fostering research on scientific publication summarization (Erera et al., 2019) and knowledge discovery.
A Summarization System for Scientific Documents
Aug 29, 2019

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Identification of Tasks, Datasets, Evaluation Metrics, and Numeric Scores for Scientific Leaderboards Construction
Jun 21, 2019

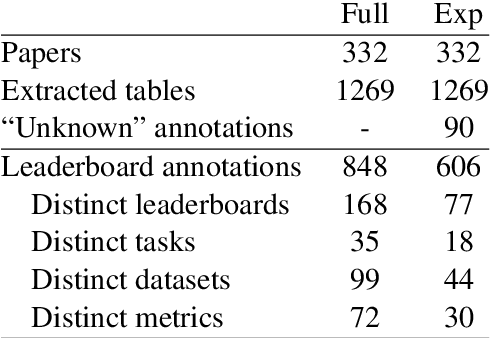
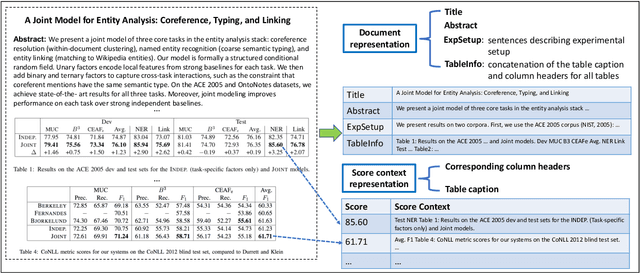
While the fast-paced inception of novel tasks and new datasets helps foster active research in a community towards interesting directions, keeping track of the abundance of research activity in different areas on different datasets is likely to become increasingly difficult. The community could greatly benefit from an automatic system able to summarize scientific results, e.g., in the form of a leaderboard. In this paper we build two datasets and develop a framework (TDMS-IE) aimed at automatically extracting task, dataset, metric and score from NLP papers, towards the automatic construction of leaderboards. Experiments show that our model outperforms several baselines by a large margin. Our model is a first step towards automatic leaderboard construction, e.g., in the NLP domain.