 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Tasks, Datasets, Evaluation Metrics, and Numeric Scores for Scientific Leaderboards Construction
Paper and Code


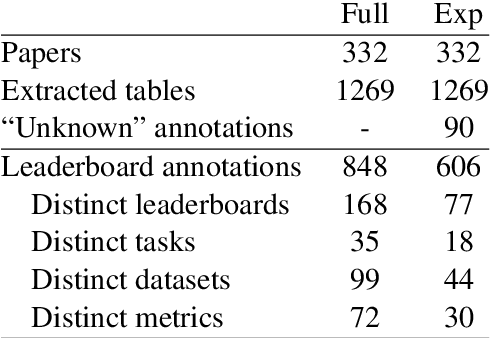
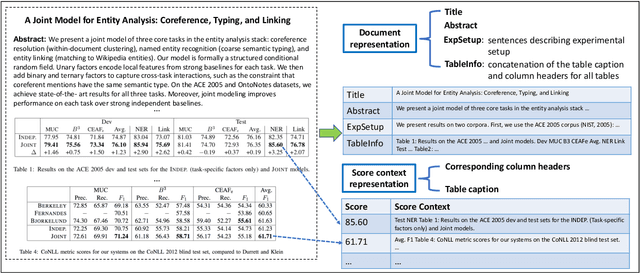
While the fast-paced inception of novel tasks and new datasets helps foster active research in a community towards interesting directions, keeping track of the abundance of research activity in different areas on different datasets is likely to become increasingly difficult. The community could greatly benefit from an automatic system able to summarize scientific results, e.g., in the form of a leaderboard. In this paper we build two datasets and develop a framework (TDMS-IE) aimed at automatically extracting task, dataset, metric and score from NLP papers, towards the automatic construction of leaderboards. Experiments show that our model outperforms several baselines by a large margin. Our model is a first step towards automatic leaderboard construction, e.g., in the NLP domain.