 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Validation: Selectivity has a Price, but Variety is Free
Apr 25, 2018
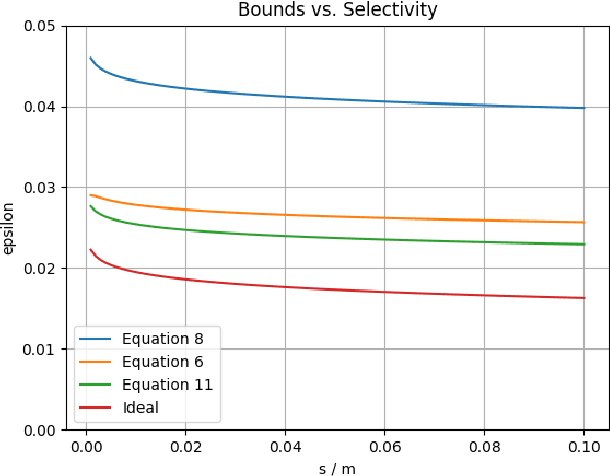
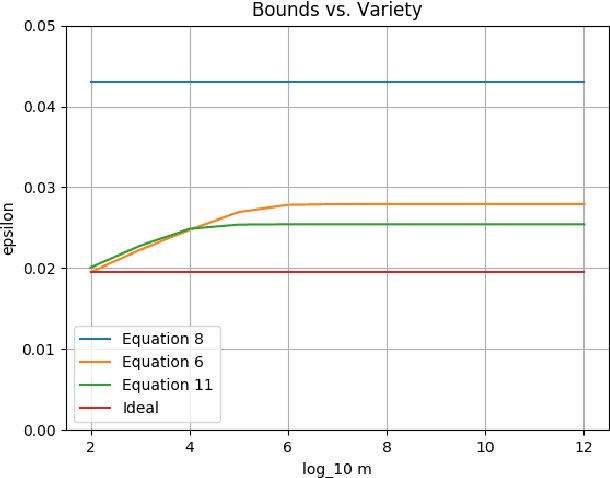
Suppose some classifiers are selected from a set of hypothesis classifiers to form an equally-weighted ensemble that selects a member classifier at random for each input example. Then the ensemble has an error bound consisting of the average error bound for the member classifiers, a term for selectivity that varies from zero (if all hypothesis classifiers are selected) to a standard uniform error bound (if only a single classifier is selected), and small constants. There is no penalty for using a richer hypothesis set if the same fraction of the hypothesis classifiers are selected for the ensemble.
The DARPA Twitter Bot Challenge
Apr 21, 2016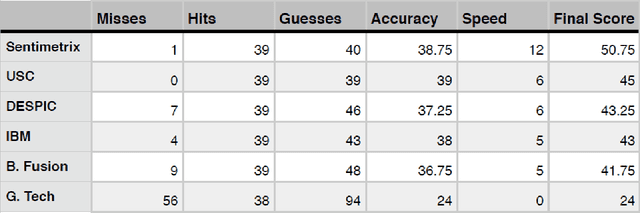
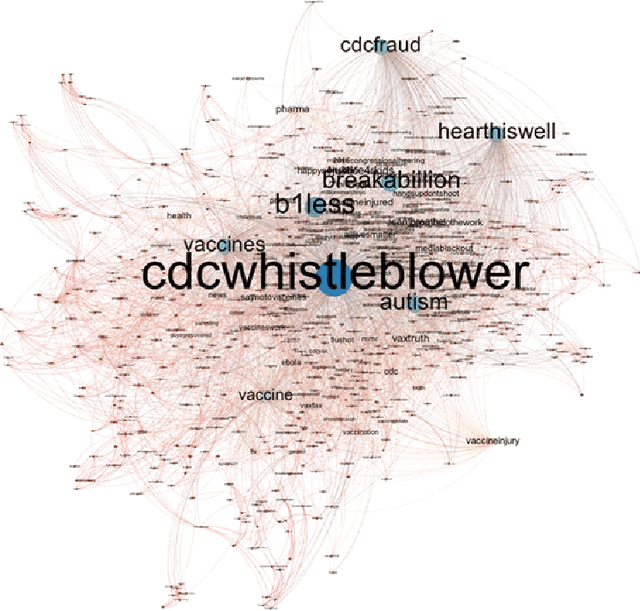
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press