Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Validation: Selectivity has a Price, but Variety is Free
Paper and Code
Apr 25, 2018
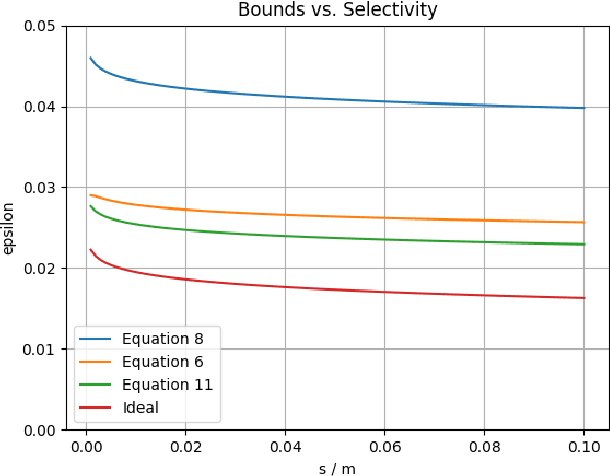
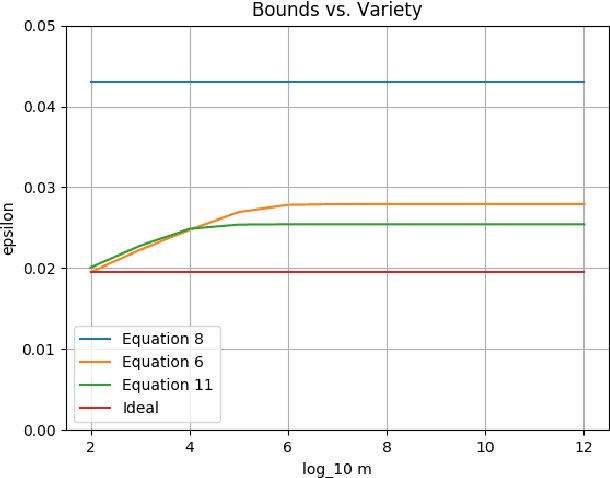
Suppose some classifiers are selected from a set of hypothesis classifiers to form an equally-weighted ensemble that selects a member classifier at random for each input example. Then the ensemble has an error bound consisting of the average error bound for the member classifiers, a term for selectivity that varies from zero (if all hypothesis classifiers are selected) to a standard uniform error bound (if only a single classifier is selected), and small constants. There is no penalty for using a richer hypothesis set if the same fraction of the hypothesis classifiers are selected for the ensemble.
View paper on