 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for 2D grapevine bud detection
Aug 27, 2020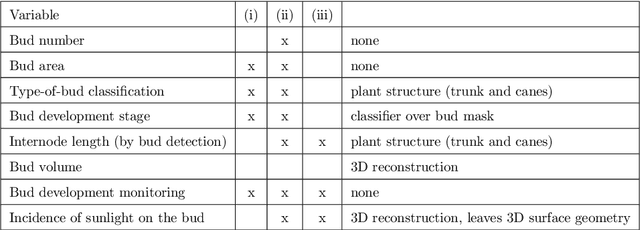
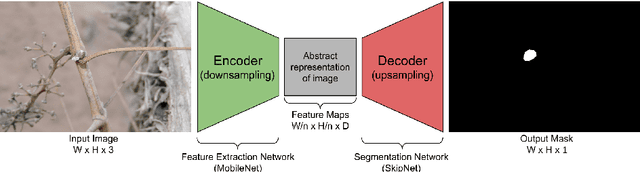
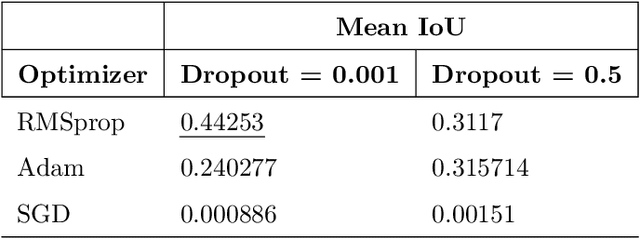

In Viticulture, visual inspection of the plant is a necessary task for measuring relevant variables. In many cases, these visual inspections are susceptible to automation through computer vision methods. Bud detection is one such visual task, central for the measurement of important variables such as: measurement of bud sunlight exposure, autonomous pruning, bud counting, type-of-bud classification, bud geometric characterization, internode length, bud area, and bud development stage, among others. This paper presents a computer method for grapevine bud detection based on a Fully Convolutional Networks MobileNet architecture (FCN-MN). To validate its performance, this architecture was compared in the detection task with a strong method for bud detection, the scanning windows with patch classifier method, showing improvements over three aspects of detection: segmentation, correspondence identification and localization. In its best version of configuration parameters, the present approach showed a detection precision of $95.6\%$, a detection recall of $93.6\%$, a mean Dice measure of $89.1\%$ for correct detection (i.e., detections whose mask overlaps the true bud), with small and nearby false alarms (i.e., detections not overlapping the true bud) as shown by a mean pixel area of only $8\%$ the area of a true bud, and a distance (between mass centers) of $1.1$ true bud diameters. We conclude by discussing how these results for FCN-MN would produce sufficiently accurate measurements of variables bud number, bud area, and internode length, suggesting a good performance in a practical setup.
Log-linear models independence structure comparison
Jul 21, 2019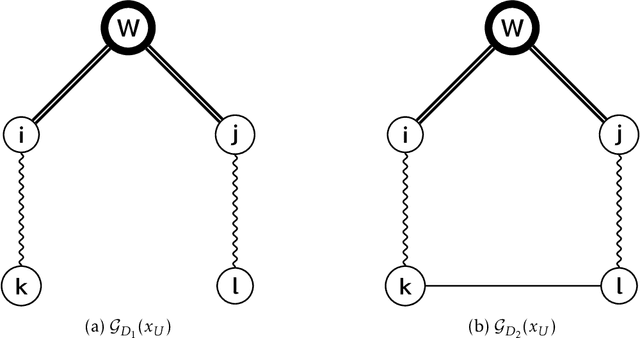
Log-linear models are a family of probability distributions which capture a variety of relationships between variables, including context-specific independencies. There are a number of approaches for automatic learning of their independence structures from data, although to date, no efficient method exists for evaluating these approaches directly in terms of the structures of the models. The only known methods evaluate these approaches indirectly through the complete model produced, that includes not only the structure but also the model parameters, introducing potential distortions in the comparison. This work presents such a method, that is, a measure for the direct comparison of the independence structures of log-linear models, inspired by the Hamming distance comparison method used in undirected graphical models. The measure presented can be efficiently computed in terms of the number of variables of the domain, and is proven to be a distance metric.
Blankets Joint Posterior score for learning Markov network structures
Mar 27, 2017
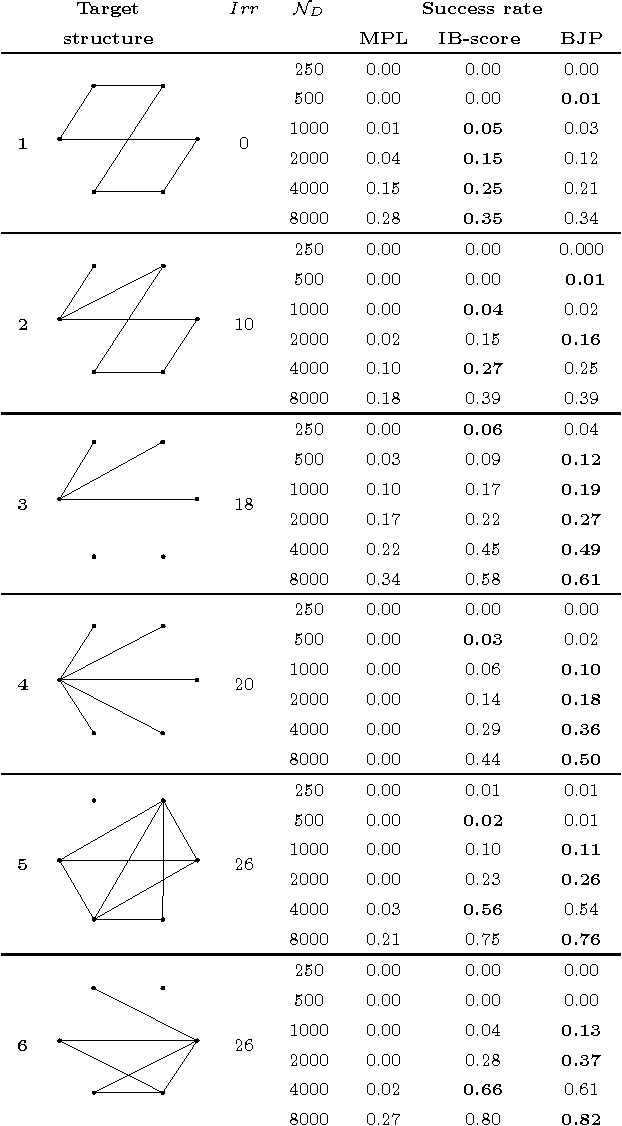

Markov networks are extensively used to model complex sequential, spatial, and relational interactions in a wide range of fields. By learning the structure of independences of a domain, more accurate joint probability distributions can be obtained for inference tasks or, more directly, for interpreting the most significant relations among the variables. Recently, several researchers have investigated techniques for automatically learning the structure from data by obtaining the probabilistic maximum-a-posteriori structure given the available data. However, all the approximations proposed decompose the posterior of the whole structure into local sub-problems, by assuming that the posteriors of the Markov blankets of all the variables are mutually independent. In this work, we propose a scoring function for relaxing such assumption. The Blankets Joint Posterior score computes the joint posterior of structures as a joint distribution of the collection of its Markov blankets. Essentially, the whole posterior is obtained by computing the posterior of the blanket of each variable as a conditional distribution that takes into account information from other blankets in the network. We show in our experimental results that the proposed approximation can improve the sample complexity of state-of-the-art scores when learning complex networks, where the independence assumption between blanket variables is clearly incorrect.
Estimacion de carga muscular mediante imagenes
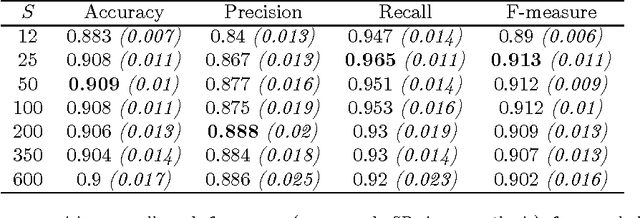
Jun 02, 2016Un problema de gran interes en disciplinas como la ocupacional, ergonomica y deportiva, es la medicion de variables biomecanicas involucradas en el movimiento humano (como las fuerzas musculares internas y torque de articulaciones). Actualmente este problema se resuelve en un proceso de dos pasos. Primero capturando datos con dispositivos poco pr\'acticos, intrusivos y costosos. Luego estos datos son usados como entrada en modelos complejos para obtener las variables biomecanicas como salida. El presente trabajo representa una alternativa automatizada, no intrusiva y economica al primer paso, proponiendo la captura de estos datos a traves de imagenes. En trabajos futuros la idea es automatizar todo el proceso de calculo de esas variables. En este trabajo elegimos un caso particular de medicion de variables biomecanicas: el problema de estimar el nivel discreto de carga muscular que estan ejerciendo los musculos de un brazo. Para estimar a partir de imagenes estaticas del brazo ejerciendo la fuerza de sostener la carga, el nivel de la misma, realizamos un proceso de clasificacion. Nuestro enfoque utiliza Support Vector Machines para clasificacion, combinada con una etapa de pre-procesamiento que extrae caracter{\i}sticas visuales utilizando variadas tecnicas (Bag of Keypoints, Local Binary Patterns, Histogramas de Color, Momentos de Contornos) En los mejores casos (Local Binary Patterns y Momentos de Contornos) obtenemos medidas de performance en la clasificacion (Precision, Recall, F-Measure y Accuracy) superiores al 90 %.
Computer Vision Approach for Low Cost, High Precision Measurement of Grapevine Trunk Diameter in Outdoor Conditions
May 09, 2016



Trunk diameter is a variable of agricultural interest, used mainly in the prediction of fruit trees production. It is correlated with leaf area and biomass of trees, and consequently gives a good estimate of the potential production of the plants. This work presents a low cost, high precision method for the measurement of trunk diameter of grapevines based on Computer Vision techniques. Several methods based on Computer Vision and other techniques are introduced in the literature. These methods present different advantages for crop management: they are amenable to be operated by unknowledgeable personnel, with lower operational costs; they result in lower stress levels to knowledgeable personnel, avoiding the deterioration of the measurement quality over time; and they make the measurement process amenable to be embedded in larger autonomous systems, allowing more measurements to be taken with equivalent costs. To date, all existing autonomous methods are either of low precision, or have a prohibitive cost for massive agricultural adoption, leaving the manual Vernier caliper or tape measure as the only choice in most situations. In this work we present a semi-autonomous measurement method that is susceptible to be fully automated, cost effective for mass adoption, and its precision is competitive (with slight improvements) over the caliper manual method.
Image Classification of Grapevine Buds using Scale-Invariant Features Transform, Bag of Features and Support Vector Machines
May 09, 2016

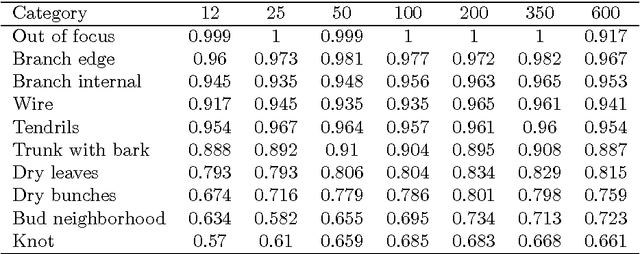
In viticulture, there are several applications where bud detection in vineyard images is a necessary task, susceptible of being automated through the use of computer vision methods. A common and effective family of visual detection algorithms are the scanning-window type, that slide a (usually) fixed size window along the original image, classifying each resulting windowed-patch as containing or not containing the target object. The simplicity of these algorithms finds its most challenging aspect in the classification stage. Interested in grapevine buds detection in natural field conditions, this paper presents a classification method for images of grapevine buds ranging 100 to 1600 pixels in diameter, captured in outdoor, under natural field conditions, in winter (i.e., no grape bunches, very few leaves, and dormant buds), without artificial background, and with minimum equipment requirements. The proposed method uses well-known computer vision technologies: Scale-Invariant Feature Transform for calculating low-level features, Bag of Features for building an image descriptor, and Support Vector Machines for training a classifier. When evaluated over images containing buds of at least 100 pixels in diameter, the approach achieves a recall higher than 0.9 and a precision of 0.86 over all windowed-patches covering the whole bud and down to 60% of it, and scaled up to window patches containing a proportion of 20%-80% of bud versus background pixels. This robustness on the position and size of the window demonstrates its viability for use as the classification stage in a scanning-window detection algorithms.
The Grow-Shrink strategy for learning Markov network structures constrained by context-specific independences
Jul 30, 2014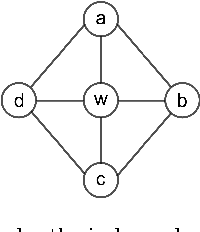

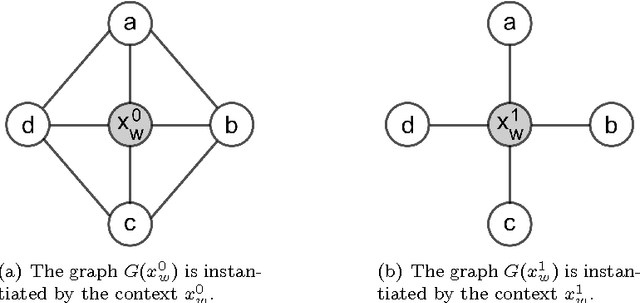
Markov networks are models for compactly representing complex probability distributions. They are composed by a structure and a set of numerical weights. The structure qualitatively describes independences in the distribution, which can be exploited to factorize the distribution into a set of compact functions. A key application for learning structures from data is to automatically discover knowledge. In practice, structure learning algorithms focused on "knowledge discovery" present a limitation: they use a coarse-grained representation of the structure. As a result, this representation cannot describe context-specific independences. Very recently, an algorithm called CSPC was designed to overcome this limitation, but it has a high computational complexity. This work tries to mitigate this downside presenting CSGS, an algorithm that uses the Grow-Shrink strategy for reducing unnecessary computations. On an empirical evaluation, the structures learned by CSGS achieve competitive accuracies and lower computational complexity with respect to those obtained by CSPC.
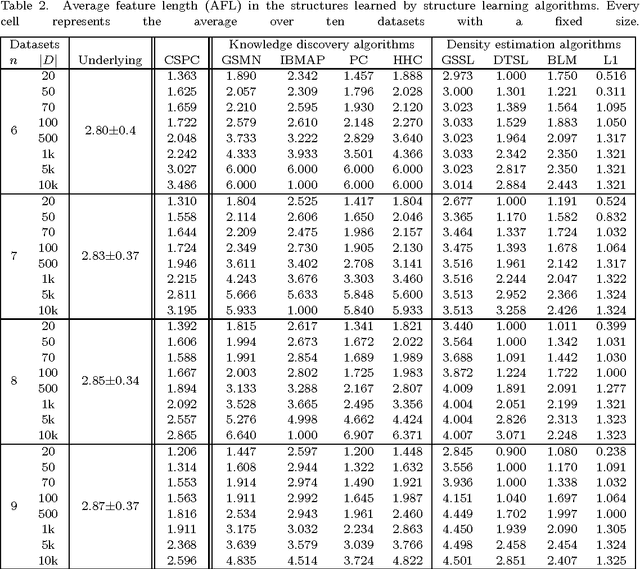
The IBMAP approach for Markov networks structure learning
Feb 25, 2014
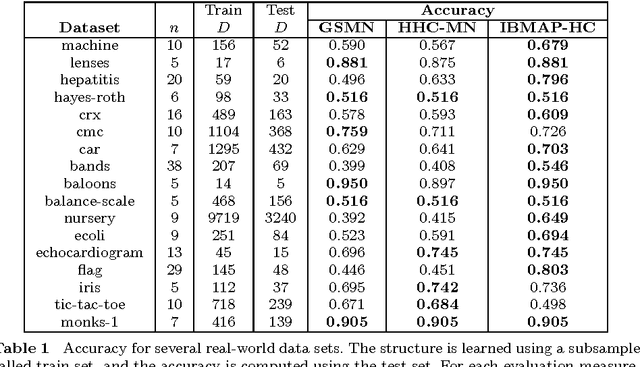
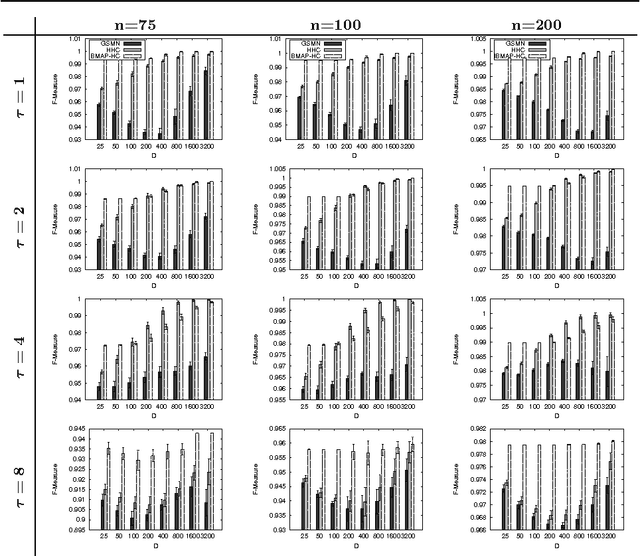
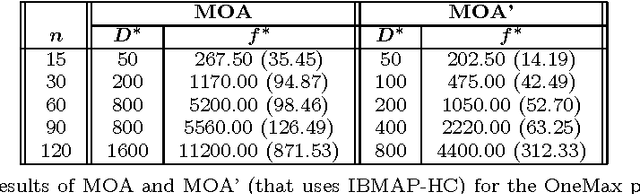
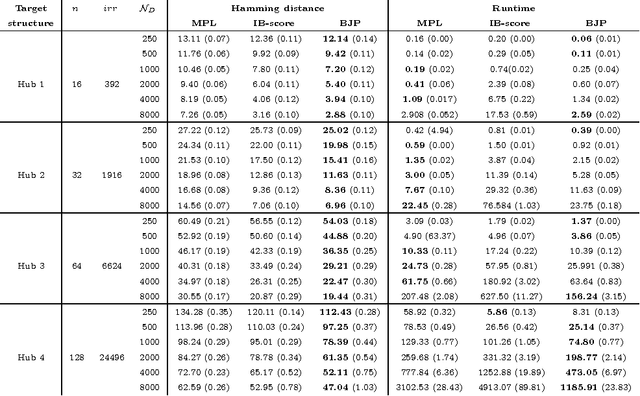
In this work we consider the problem of learning the structure of Markov networks from data. We present an approach for tackling this problem called IBMAP, together with an efficient instantiation of the approach: the IBMAP-HC algorithm, designed for avoiding important limitations of existing independence-based algorithms. These algorithms proceed by performing statistical independence tests on data, trusting completely the outcome of each test. In practice tests may be incorrect, resulting in potential cascading errors and the consequent reduction in the quality of the structures learned. IBMAP contemplates this uncertainty in the outcome of the tests through a probabilistic maximum-a-posteriori approach. The approach is instantiated in the IBMAP-HC algorithm, a structure selection strategy that performs a polynomial heuristic local search in the space of possible structures. We present an extensive empirical evaluation on synthetic and real data, showing that our algorithm outperforms significantly the current independence-based algorithms, in terms of data efficiency and quality of learned structures, with equivalent computational complexities. We also show the performance of IBMAP-HC in a real-world application of knowledge discovery: EDAs, which are evolutionary algorithms that use structure learning on each generation for modeling the distribution of populations. The experiments show that when IBMAP-HC is used to learn the structure, EDAs improve the convergence to the optimum.
Efficient Markov Network Structure Discovery Using Independence Tests
Jan 15, 2014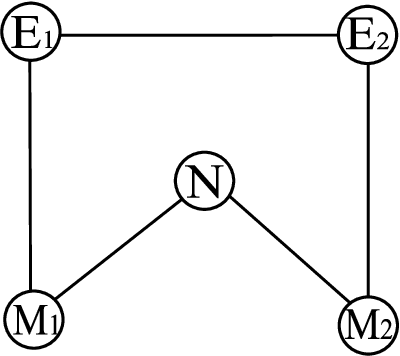
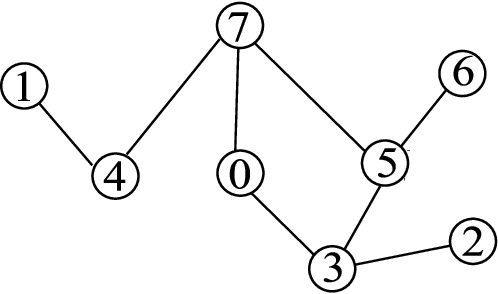
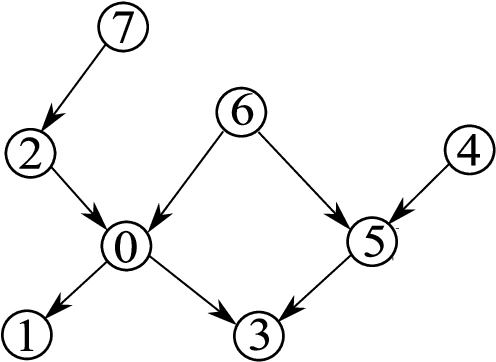
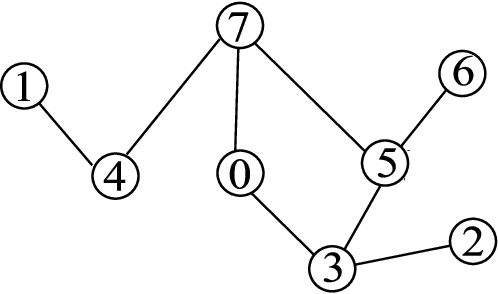
We present two algorithms for learning the structure of a Markov network from data: GSMN* and GSIMN. Both algorithms use statistical independence tests to infer the structure by successively constraining the set of structures consistent with the results of these tests. Until very recently, algorithms for structure learning were based on maximum likelihood estimation, which has been proved to be NP-hard for Markov networks due to the difficulty of estimating the parameters of the network, needed for the computation of the data likelihood. The independence-based approach does not require the computation of the likelihood, and thus both GSMN* and GSIMN can compute the structure efficiently (as shown in our experiments). GSMN* is an adaptation of the Grow-Shrink algorithm of Margaritis and Thrun for learning the structure of Bayesian networks. GSIMN extends GSMN* by additionally exploiting Pearls well-known properties of the conditional independence relation to infer novel independences from known ones, thus avoiding the performance of statistical tests to estimate them. To accomplish this efficiently GSIMN uses the Triangle theorem, also introduced in this work, which is a simplified version of the set of Markov axioms. Experimental comparisons on artificial and real-world data sets show GSIMN can yield significant savings with respect to GSMN*, while generating a Markov network with comparable or in some cases improved quality. We also compare GSIMN to a forward-chaining implementation, called GSIMN-FCH, that produces all possible conditional independences resulting from repeatedly applying Pearls theorems on the known conditional independence tests. The results of this comparison show that GSIMN, by the sole use of the Triangle theorem, is nearly optimal in terms of the set of independences tests that it infers.
Learning Markov networks with context-specific independences
Jul 15, 2013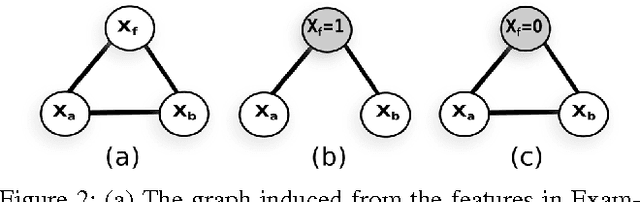

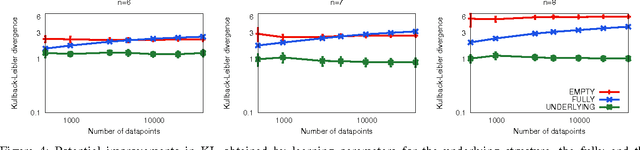
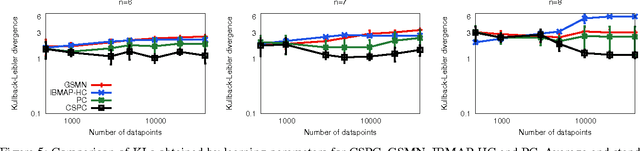
Learning the Markov network structure from data is a problem that has received considerable attention in machine learning, and in many other application fields. This work focuses on a particular approach for this purpose called independence-based learning. Such approach guarantees the learning of the correct structure efficiently, whenever data is sufficient for representing the underlying distribution. However, an important issue of such approach is that the learned structures are encoded in an undirected graph. The problem with graphs is that they cannot encode some types of independence relations, such as the context-specific independences. They are a particular case of conditional independences that is true only for a certain assignment of its conditioning set, in contrast to conditional independences that must hold for all its assignments. In this work we present CSPC, an independence-based algorithm for learning structures that encode context-specific independences, and encoding them in a log-linear model, instead of a graph. The central idea of CSPC is combining the theoretical guarantees provided by the independence-based approach with the benefits of representing complex structures by using features in a log-linear model. We present experiments in a synthetic case, showing that CSPC is more accurate than the state-of-the-art IB algorithms when the underlying distribution contains CSIs.