 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Grow-Shrink strategy for learning Markov network structures constrained by context-specific independences
Paper and Code
Jul 30, 2014

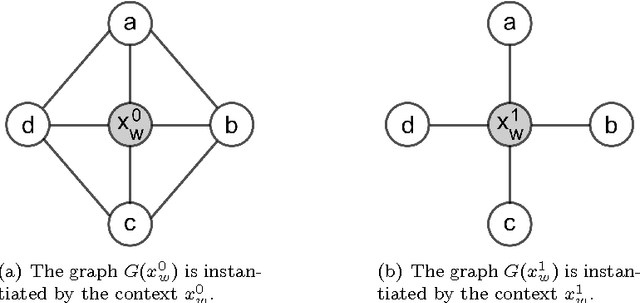
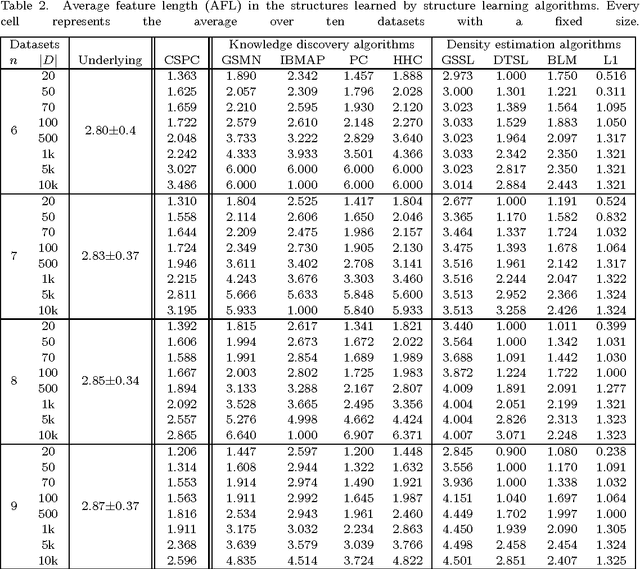
Markov networks are models for compactly representing complex probability distributions. They are composed by a structure and a set of numerical weights. The structure qualitatively describes independences in the distribution, which can be exploited to factorize the distribution into a set of compact functions. A key application for learning structures from data is to automatically discover knowledge. In practice, structure learning algorithms focused on "knowledge discovery" present a limitation: they use a coarse-grained representation of the structure. As a result, this representation cannot describe context-specific independences. Very recently, an algorithm called CSPC was designed to overcome this limitation, but it has a high computational complexity. This work tries to mitigate this downside presenting CSGS, an algorithm that uses the Grow-Shrink strategy for reducing unnecessary computations. On an empirical evaluation, the structures learned by CSGS achieve competitive accuracies and lower computational complexity with respect to those obtained by CSPC.