 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Textiles that Teach: Fabric-Based Haptic Device Improves the Rate of Motor Learning
Jul 12, 2021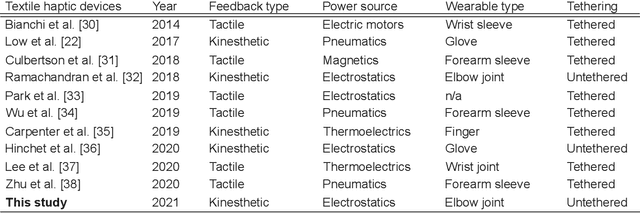
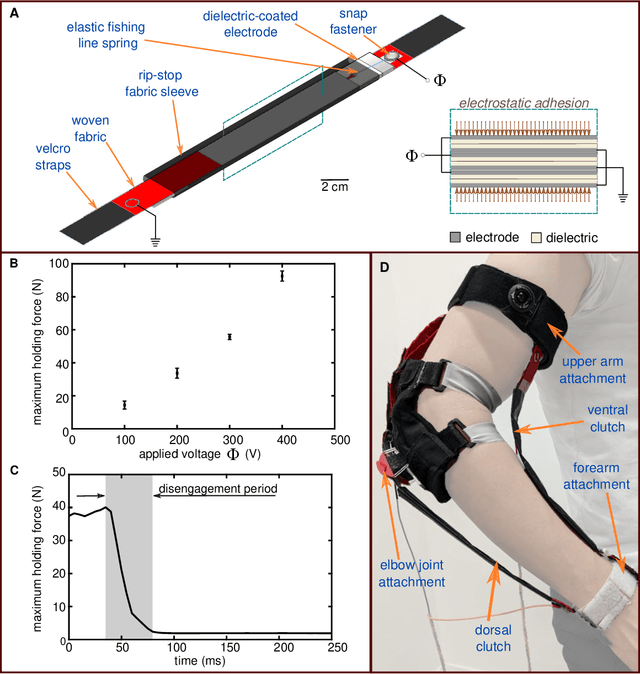
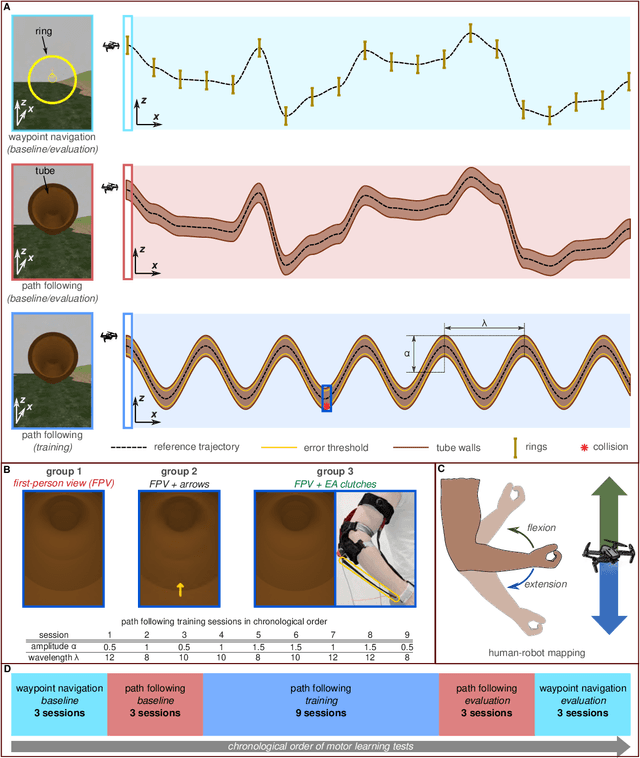
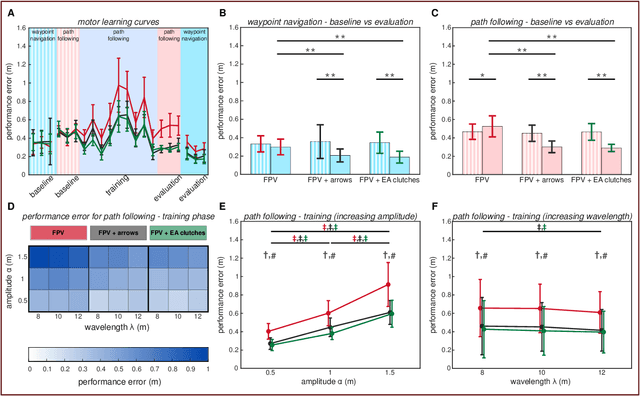
People learn motor activities best when they are conscious of their errors and make a concerted effort to correct them. While haptic interfaces can facilitate motor training, existing interfaces are often bulky and do not always ensure post-training skill retention. Here, we describe a programmable haptic sleeve composed of textile-based electroadhesive clutches for skill acquisition and retention. We show its functionality in a motor learning study where users control a drone's movement using elbow joint rotation. Haptic feedback is used to restrain elbow motion and make users aware of their errors. This helps users consciously learn to avoid errors from occurring. While all subjects exhibited similar performance during the baseline phase of motor learning, those subjects who received haptic feedback from the haptic sleeve committed 23.5% fewer errors than subjects in the control group during the evaluation phase. The results show that the sleeve helps users retain and transfer motor skills better than visual feedback alone. This work shows the potential for fabric-based haptic interfaces as a training aid for motor tasks in the fields of rehabilitation and teleoperation.
VIODE: A Simulated Dataset to Address the Challenges of Visual-Inertial Odometry in Dynamic Environments
Feb 11, 2021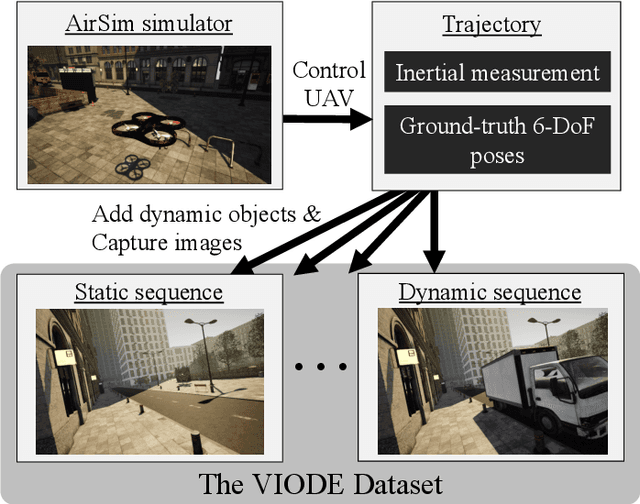

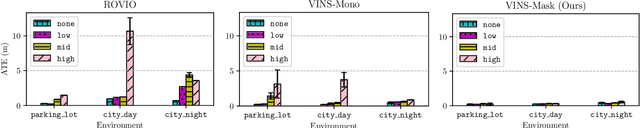

Dynamic environments such as urban areas are still challenging for popular visual-inertial odometry (VIO) algorithms. Existing datasets typically fail to capture the dynamic nature of these environments, therefore making it difficult to quantitatively evaluate the robustness of existing VIO methods. To address this issue, we propose three contributions: firstly, we provide the VIODE benchmark, a novel dataset recorded from a simulated UAV that navigates in challenging dynamic environments. The unique feature of the VIODE dataset is the systematic introduction of moving objects into the scenes. It includes three environments, each of which is available in four dynamic levels that progressively add moving objects. The dataset contains synchronized stereo images and IMU data, as well as ground-truth trajectories and instance segmentation masks. Secondly, we compare state-of-the-art VIO algorithms on the VIODE dataset and show that they display substantial performance degradation in highly dynamic scenes. Thirdly, we propose a simple extension for visual localization algorithms that relies on semantic information. Our results show that scene semantics are an effective way to mitigate the adverse effects of dynamic objects on VIO algorithms. Finally, we make the VIODE dataset publicly available at https://github.com/kminoda/VIODE.
Vision-based flocking in outdoor environments
Dec 02, 2020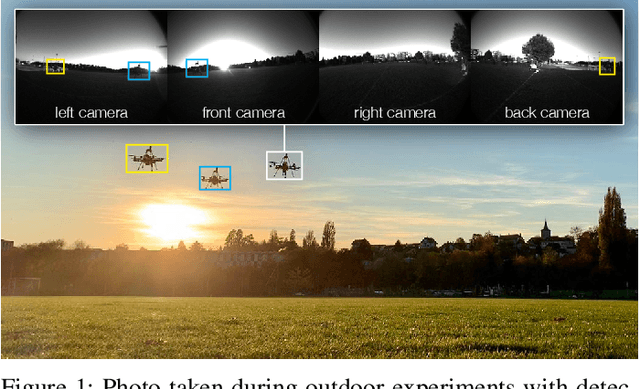
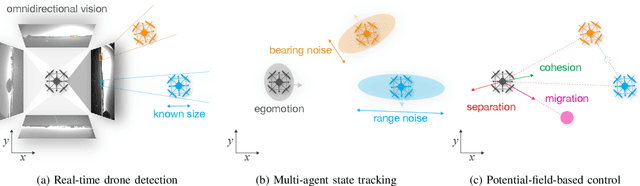
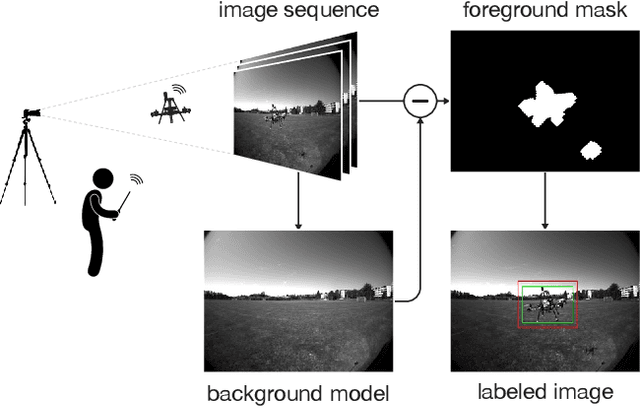

Deployment of drone swarms usually relies on inter-agent communication or visual markers that are mounted on the vehicles to simplify their mutual detection. This letter proposes a vision-based detection and tracking algorithm that enables groups of drones to navigate without communication or visual markers. We employ a convolutional neural network to detect and localize nearby agents onboard the quadcopters in real-time. Rather than manually labeling a dataset, we automatically annotate images to train the neural network using background subtraction by systematically flying a quadcopter in front of a static camera. We use a multi-agent state tracker to estimate the relative positions and velocities of nearby agents, which are subsequently fed to a flocking algorithm for high-level control. The drones are equipped with multiple cameras to provide omnidirectional visual inputs. The camera setup ensures the safety of the flock by avoiding blind spots regardless of the agent configuration. We evaluate the approach with a group of three real quadcopters that are controlled using the proposed vision-based flocking algorithm. The results show that the drones can safely navigate in an outdoor environment despite substantial background clutter and difficult lighting conditions.
Flexible Disaster Response of Tomorrow -- Final Presentation and Evaluation of the CENTAURO System
Sep 19, 2019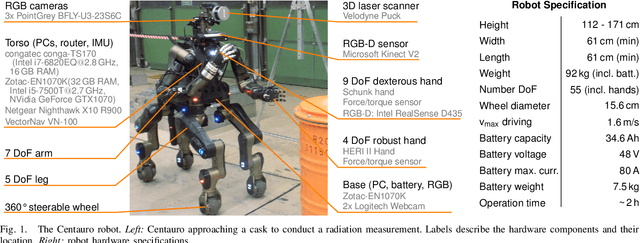

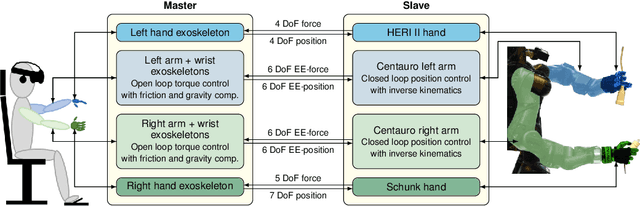
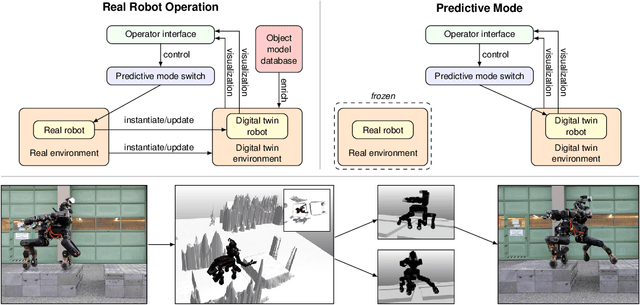
Mobile manipulation robots have high potential to support rescue forces in disaster-response missions. Despite the difficulties imposed by real-world scenarios, robots are promising to perform mission tasks from a safe distance. In the CENTAURO project, we developed a disaster-response system which consists of the highly flexible Centauro robot and suitable control interfaces including an immersive tele-presence suit and support-operator controls on different levels of autonomy. In this article, we give an overview of the final CENTAURO system. In particular, we explain several high-level design decisions and how those were derived from requirements and extensive experience of Kerntechnische Hilfsdienst GmbH, Karlsruhe, Germany (KHG). We focus on components which were recently integrated and report about a systematic evaluation which demonstrated system capabilities and revealed valuable insights.
Learning Vision-based Flight in Drone Swarms by Imitation
Aug 08, 2019
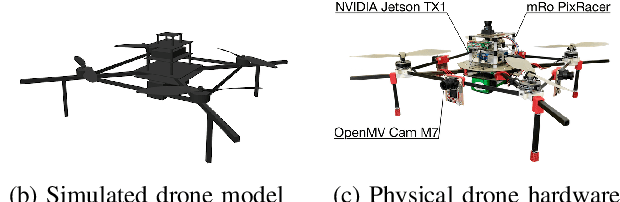

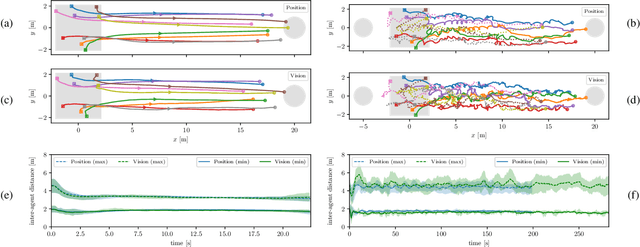
Decentralized drone swarms deployed today either rely on sharing of positions among agents or detecting swarm members with the help of visual markers. This work proposes an entirely visual approach to coordinate markerless drone swarms based on imitation learning. Each agent is controlled by a small and efficient convolutional neural network that takes raw omnidirectional images as inputs and predicts 3D velocity commands that match those computed by a flocking algorithm. We start training in simulation and propose a simple yet effective unsupervised domain adaptation approach to transfer the learned controller to the real world. We further train the controller with data collected in our motion capture hall. We show that the convolutional neural network trained on the visual inputs of the drone can learn not only robust inter-agent collision avoidance but also cohesion of the swarm in a sample-efficient manner. The neural controller effectively learns to localize other agents in the visual input, which we show by visualizing the regions with the most influence on the motion of an agent. We remove the dependence on sharing positions among swarm members by taking only local visual information into account for control. Our work can therefore be seen as the first step towards a fully decentralized, vision-based swarm without the need for communication or visual markers.
Learning Vision-based Cohesive Flight in Drone Swarms
Sep 03, 2018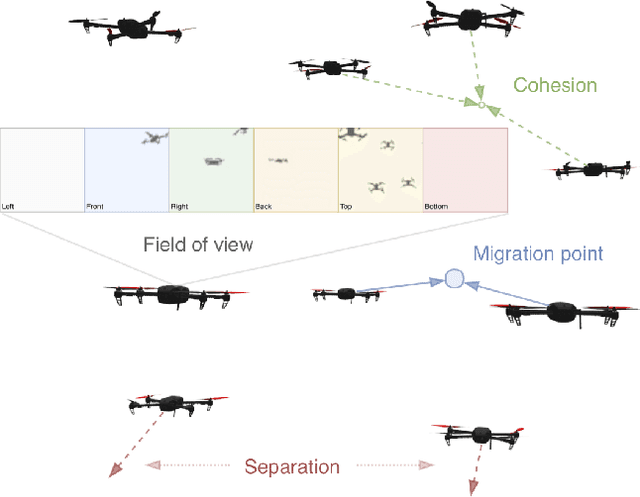
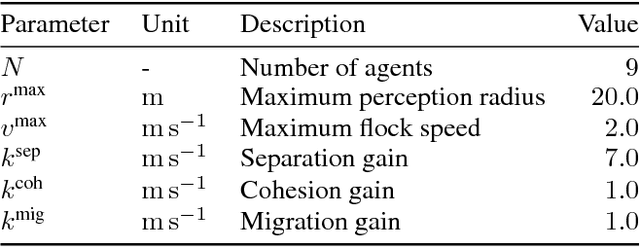

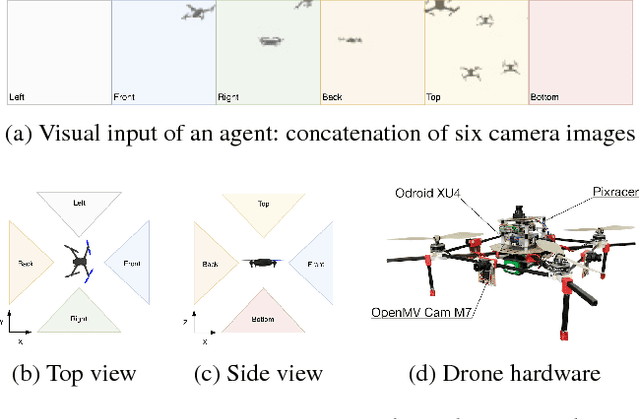
This paper presents a data-driven approach to learning vision-based collective behavior from a simple flocking algorithm. We simulate a swarm of quadrotor drones and formulate the controller as a regression problem in which we generate 3D velocity commands directly from raw camera images. The dataset is created by simultaneously acquiring omnidirectional images and computing the corresponding control command from the flocking algorithm. We show that a convolutional neural network trained on the visual inputs of the drone can learn not only robust collision avoidance but also coherence of the flock in a sample-efficient manner. The neural controller effectively learns to localize other agents in the visual input, which we show by visualizing the regions with the most influence on the motion of an agent. This weakly supervised saliency map can be computed efficiently and may be used as a prior for subsequent detection and relative localization of other agents. We remove the dependence on sharing positions among flock members by taking only local visual information into account for control. Our work can therefore be seen as the first step towards a fully decentralized, vision-based flock without the need for communication or visual markers to aid detection of other agents.