 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Occlusions in the Wild: A Multi-Task Age Head Approach to Age Estimation
Jun 16, 2025Facial age estimation has achieved considerable success under controlled conditions. However, in unconstrained real-world scenarios, which are often referred to as 'in the wild', age estimation remains challenging, especially when faces are partially occluded, which may obscure their visibility. To address this limitation, we propose a new approach integrating generative adversarial networks (GANs) and transformer architectures to enable robust age estimation from occluded faces. We employ an SN-Patch GAN to effectively remove occlusions, while an Attentive Residual Convolution Module (ARCM), paired with a Swin Transformer, enhances feature representation. Additionally, we introduce a Multi-Task Age Head (MTAH) that combines regression and distribution learning, further improving age estimation under occlusion. Experimental results on the FG-NET, UTKFace, and MORPH datasets demonstrate that our proposed approach surpasses existing state-of-the-art techniques for occluded facial age estimation by achieving an MAE of $3.00$, $4.54$, and $2.53$ years, respectively.
Underage Detection through a Multi-Task and MultiAge Approach for Screening Minors in Unconstrained Imagery
Jun 12, 2025Accurate automatic screening of minors in unconstrained images demands models that are robust to distribution shift and resilient to the children under-representation in publicly available data. To overcome these issues, we propose a multi-task architecture with dedicated under/over-age discrimination tasks based on a frozen FaRL vision-language backbone joined with a compact two-layer MLP that shares features across one age-regression head and four binary under-age heads for age thresholds of 12, 15, 18, and 21 years, focusing on the legally critical age range. To address the severe class imbalance, we introduce an $\alpha$-reweighted focal-style loss and age-balanced mini-batch sampling, which equalizes twelve age bins during stochastic optimization. Further improvement is achieved with an age gap that removes edge cases from the loss. Moreover, we set a rigorous evaluation by proposing the Overall Under-Age Benchmark, with 303k cleaned training images and 110k test images, defining both the "ASORES-39k" restricted overall test, which removes the noisiest domains, and the age estimation wild shifts test "ASWIFT-20k" of 20k-images, stressing extreme pose ($>$45{\deg}), expression, and low image quality to emulate real-world shifts. Trained on the cleaned overall set with resampling and age gap, our multiage model "F" lowers the root-mean-square-error on the ASORES-39k restricted test from 5.733 (age-only baseline) to 5.656 years and lifts under-18 detection from F2 score of 0.801 to 0.857 at 1% false-adult rate. Under the domain shift to the wild data of ASWIFT-20k, the same configuration nearly sustains 0.99 recall while boosting F2 from 0.742 to 0.833 with respect to the age-only baseline, demonstrating strong generalization under distribution shift. For the under-12 and under-15 tasks, the respective boosts in F2 are from 0.666 to 0.955 and from 0.689 to 0.916, respectively.
PushPull-Net: Inhibition-driven ResNet robust to image corruptions
Aug 07, 2024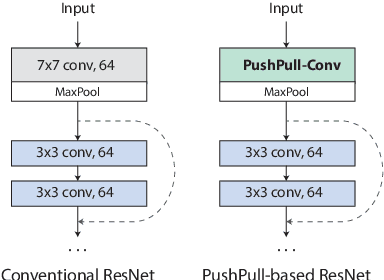
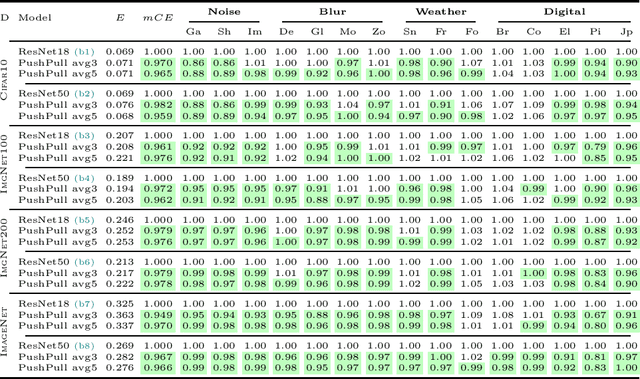
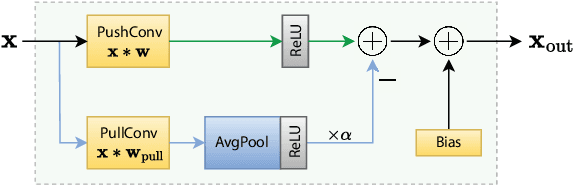
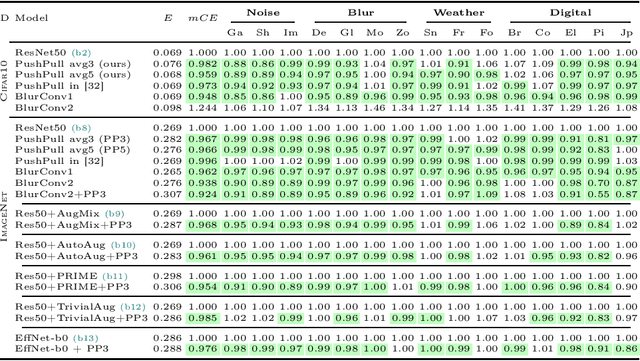
We introduce a novel computational unit, termed PushPull-Conv, in the first layer of a ResNet architecture, inspired by the anti-phase inhibition phenomenon observed in the primary visual cortex. This unit redefines the traditional convolutional layer by implementing a pair of complementary filters: a trainable push kernel and its counterpart, the pull kernel. The push kernel (analogous to traditional convolution) learns to respond to specific stimuli, while the pull kernel reacts to the same stimuli but of opposite contrast. This configuration enhances stimulus selectivity and effectively inhibits response in regions lacking preferred stimuli. This effect is attributed to the push and pull kernels, which produce responses of comparable magnitude in such regions, thereby neutralizing each other. The incorporation of the PushPull-Conv into ResNets significantly increases their robustness to image corruption. Our experiments with benchmark corruption datasets show that the PushPull-Conv can be combined with other data augmentation techniques to further improve model robustness. We set a new robustness benchmark on ResNet50 achieving an $mCE$ of 49.95$\%$ on ImageNet-C when combining PRIME augmentation with PushPull inhibition.
MeWEHV: Mel and Wave Embeddings for Human Voice Tasks
Sep 28, 2022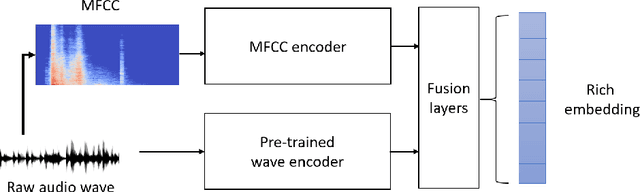
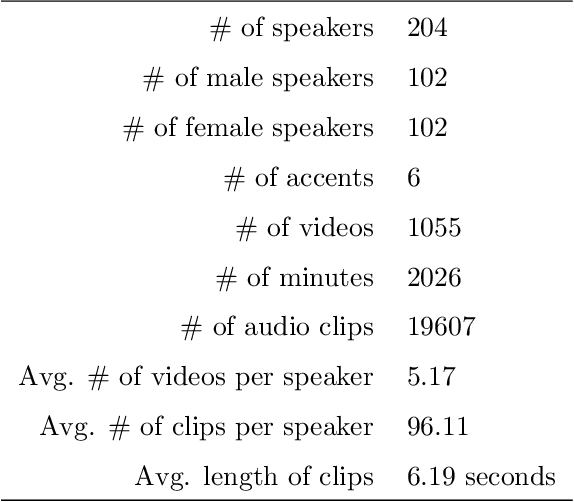

A recent trend in speech processing is the use of embeddings created through machine learning models trained on a specific task with large datasets. By leveraging the knowledge already acquired, these models can be reused in new tasks where the amount of available data is small. This paper proposes a pipeline to create a new model, called Mel and Wave Embeddings for Human Voice Tasks (MeWEHV), capable of generating robust embeddings for speech processing. MeWEHV combines the embeddings generated by a pre-trained raw audio waveform encoder model, and deep features extracted from Mel Frequency Cepstral Coefficients (MFCCs) using Convolutional Neural Networks (CNNs). We evaluate the performance of MeWEHV on three tasks: speaker, language, and accent identification. For the first one, we use the VoxCeleb1 dataset and present YouSpeakers204, a new and publicly available dataset for English speaker identification that contains 19607 audio clips from 204 persons speaking in six different accents, allowing other researchers to work with a very balanced dataset, and to create new models that are robust to multiple accents. For evaluating the language identification task, we use the VoxForge and Common Language datasets. Finally, for accent identification, we use the Latin American Spanish Corpora (LASC) and Common Voice datasets. Our approach allows a significant increase in the performance of state-of-the-art models on all the tested datasets, with a low additional computational cost.
Efficient Detection of Botnet Traffic by features selection and Decision Trees
Jun 30, 2021Botnets are one of the online threats with the biggest presence, causing billionaire losses to global economies. Nowadays, the increasing number of devices connected to the Internet makes it necessary to analyze large amounts of network traffic data. In this work, we focus on increasing the performance on botnet traffic classification by selecting those features that further increase the detection rate. For this purpose we use two feature selection techniques, Information Gain and Gini Importance, which led to three pre-selected subsets of five, six and seven features. Then, we evaluate the three feature subsets along with three models, Decision Tree, Random Forest and k-Nearest Neighbors. To test the performance of the three feature vectors and the three models we generate two datasets based on the CTU-13 dataset, namely QB-CTU13 and EQB-CTU13. We measure the performance as the macro averaged F1 score over the computational time required to classify a sample. The results show that the highest performance is achieved by Decision Trees using a five feature set which obtained a mean F1 score of 85% classifying each sample in an average time of 0.78 microseconds.
Video Camera Identification from Sensor Pattern Noise with a Constrained ConvNet
Dec 11, 2020
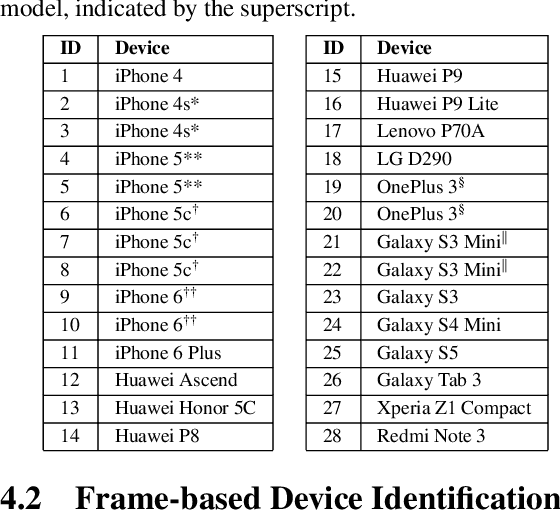
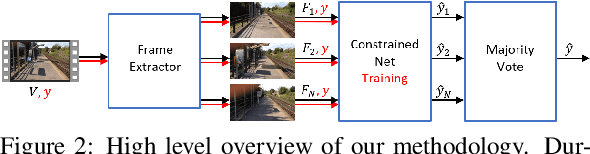

The identification of source cameras from videos, though it is a highly relevant forensic analysis topic, has been studied much less than its counterpart that uses images. In this work we propose a method to identify the source camera of a video based on camera specific noise patterns that we extract from video frames. For the extraction of noise pattern features, we propose an extended version of a constrained convolutional layer capable of processing color inputs. Our system is designed to classify individual video frames which are in turn combined by a majority vote to identify the source camera. We evaluated this approach on the benchmark VISION data set consisting of 1539 videos from 28 different cameras. To the best of our knowledge, this is the first work that addresses the challenge of video camera identification on a device level. The experiments show that our approach is very promising, achieving up to 93.1% accuracy while being robust to the WhatsApp and YouTube compression techniques. This work is part of the EU-funded project 4NSEEK focused on forensics against child sexual abuse.
Short Text Classification Approach to Identify Child Sexual Exploitation Material
Nov 13, 2020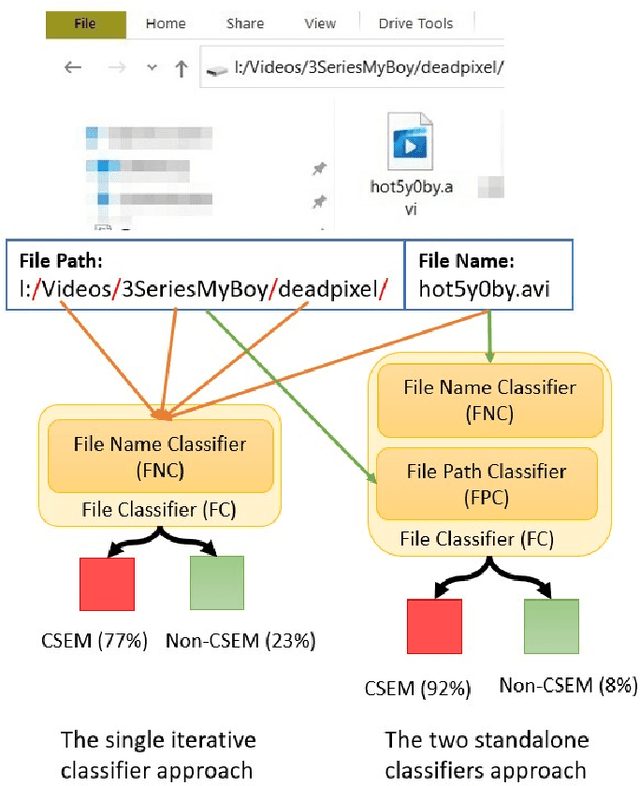
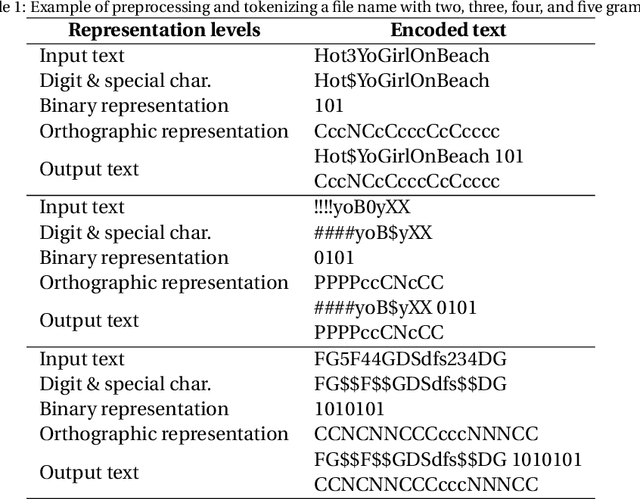
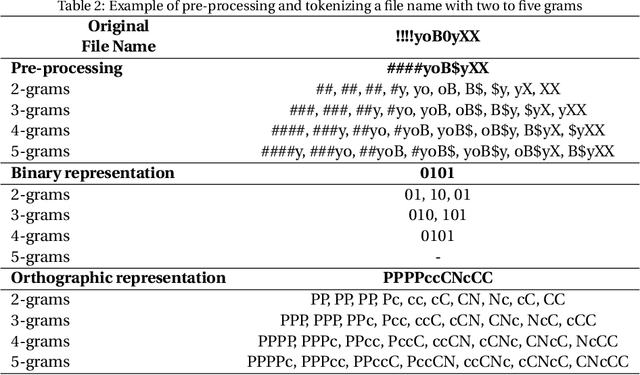

Producing or sharing Child Sexual Exploitation Material (CSEM) is a serious crime fought vigorously by Law Enforcement Agencies (LEAs). When an LEA seizes a computer from a potential producer or consumer of CSEM, they need to analyze the suspect's hard disk's files looking for pieces of evidence. However, a manual inspection of the file content looking for CSEM is a time-consuming task. In most cases, it is unfeasible in the amount of time available for the Spanish police using a search warrant. Instead of analyzing its content, another approach that can be used to speed up the process is to identify CSEM by analyzing the file names and their absolute paths. The main challenge for this task lies behind dealing with short text distorted deliberately by the owners of this material using obfuscated words and user-defined naming patterns. This paper presents and compares two approaches based on short text classification to identify CSEM files. The first one employs two independent supervised classifiers, one for the file name and the other for the path, and their outputs are later on fused into a single score. Conversely, the second approach uses only the file name classifier to iterate over the file's absolute path. Both approaches operate at the character n-grams level, while binary and orthographic features enrich the file name representation, and a binary Logistic Regression model is used for classification. The presented file classifier achieved an average class recall of 0.98. This solution could be integrated into forensic tools and services to support Law Enforcement Agencies to identify CSEM without tackling every file's visual content, which is computationally much more highly demanding.
Classification of Industrial Control Systems screenshots using Transfer Learning
May 21, 2020
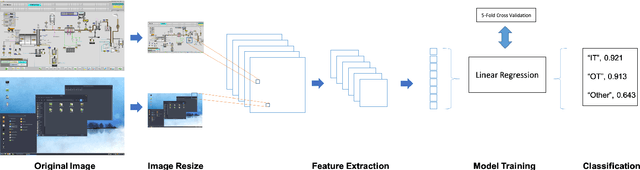

Industrial Control Systems depend heavily on security and monitoring protocols. Several tools are available for this purpose, which scout vulnerabilities and take screenshots from various control panels for later analysis. However, they do not adequately classify images into specific control groups, which can difficult operations performed by manual operators. In order to solve this problem, we use transfer learning with five CNN architectures, pre-trained on Imagenet, to determine which one best classifies screenshots obtained from Industrial Controls Systems. Using 337 manually labeled images, we train these architectures and study their performance both in accuracy and CPU and GPU time. We find out that MobilenetV1 is the best architecture based on its 97,95% of F1-Score, and its speed on CPU with 0.47 seconds per image. In systems where time is critical and GPU is available, VGG16 is preferable because it takes 0.04 seconds to process images, but dropping performance to 87,67%.
Device-based Image Matching with Similarity Learning by Convolutional Neural Networks that Exploit the Underlying Camera Sensor Pattern Noise
Apr 23, 2020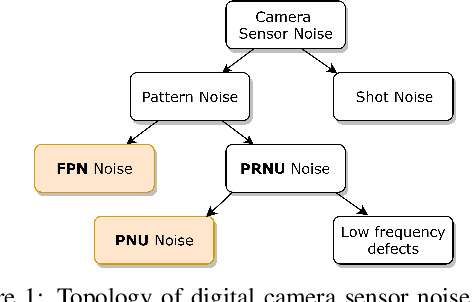
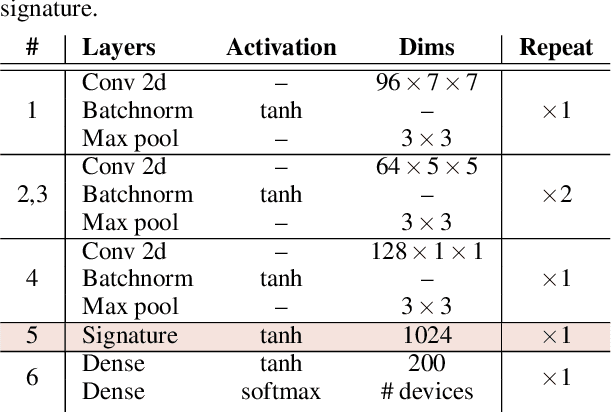
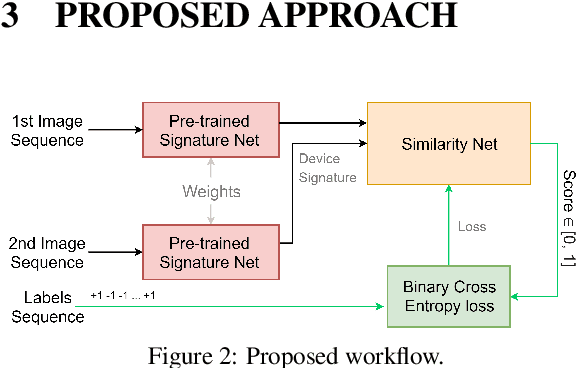
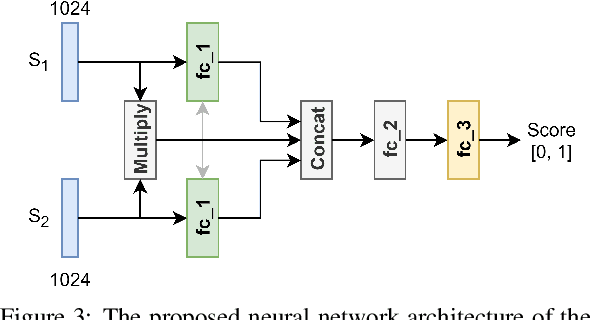
One of the challenging problems in digital image forensics is the capability to identify images that are captured by the same camera device. This knowledge can help forensic experts in gathering intelligence about suspects by analyzing digital images. In this paper, we propose a two-part network to quantify the likelihood that a given pair of images have the same source camera, and we evaluated it on the benchmark Dresden data set containing 1851 images from 31 different cameras. To the best of our knowledge, we are the first ones addressing the challenge of device-based image matching. Though the proposed approach is not yet forensics ready, our experiments show that this direction is worth pursuing, achieving at this moment 85 percent accuracy. This ongoing work is part of the EU-funded project 4NSEEK concerned with forensics against child sexual abuse.
* 7 pages, 4 figures, conference paper
Content-Based Features to Rank Influential Hidden Services of the Tor Darknet
Oct 05, 2019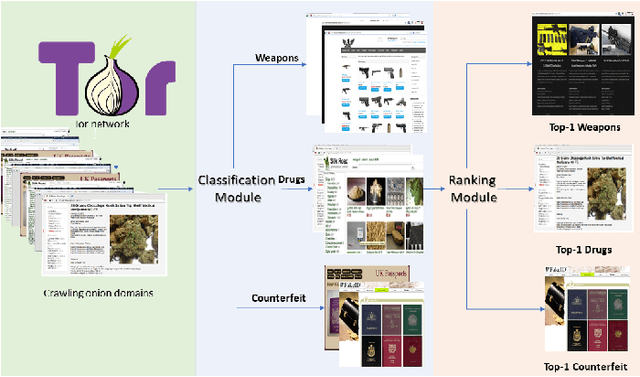
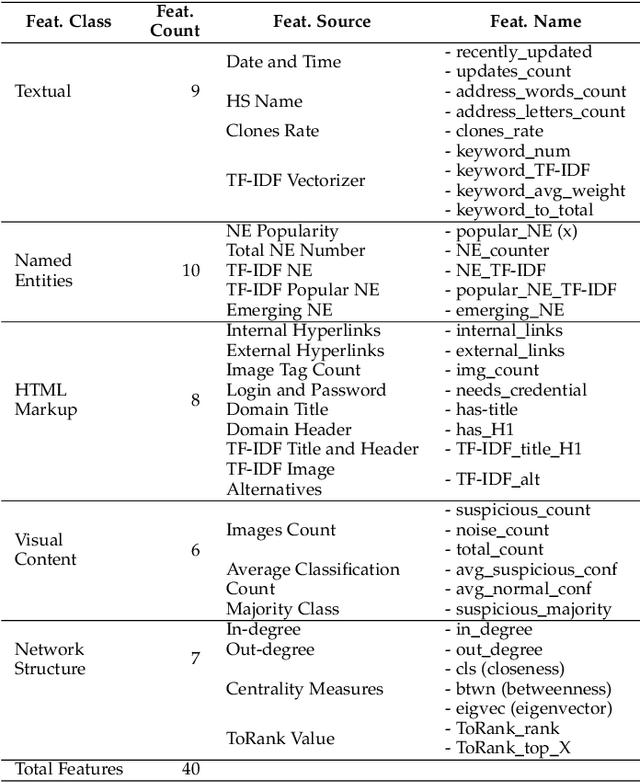
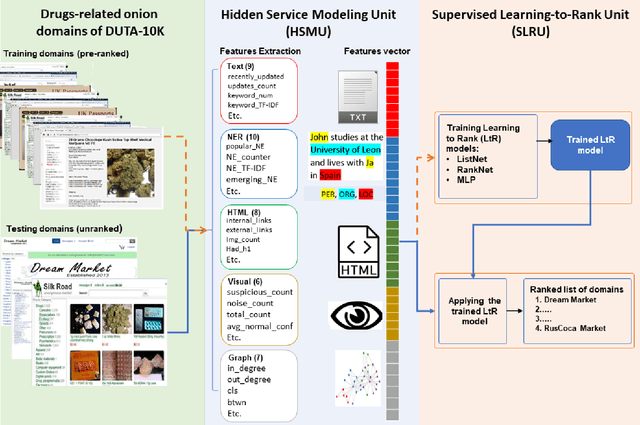

The unevenness importance of criminal activities in the onion domains of the Tor Darknet and the different levels of their appeal to the end-user make them tangled to measure their influence. To this end, this paper presents a novel content-based ranking framework to detect the most influential onion domains. Our approach comprises a modeling unit that represents an onion domain using forty features extracted from five different resources: user-visible text, HTML markup, Named Entities, network topology, and visual content. And also, a ranking unit that, using the Learning-to-Rank (LtR) approach, automatically learns a ranking function by integrating the previously obtained features. Using a case-study based on drugs-related onion domains, we obtained the following results. (1) Among the explored LtR schemes, the listwise approach outperforms the benchmarked methods with an NDCG of 0.95 for the top-10 ranked domains. (2) We proved quantitatively that our framework surpasses the link-based ranking techniques. Also, (3) with the selected feature, we observed that the textual content, composed by text, NER, and HTML features, is the most balanced approach, in terms of efficiency and score obtained. The proposed framework might support Law Enforcement Agencies in detecting the most influential domains related to possible suspicious activities.