 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeWEHV: Mel and Wave Embeddings for Human Voice Tasks
Paper and Code
Sep 28, 2022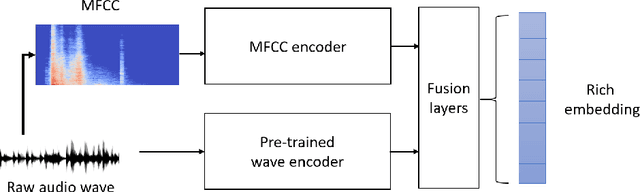
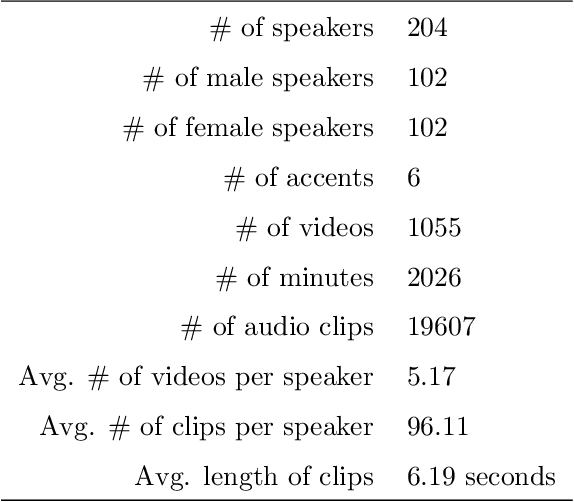
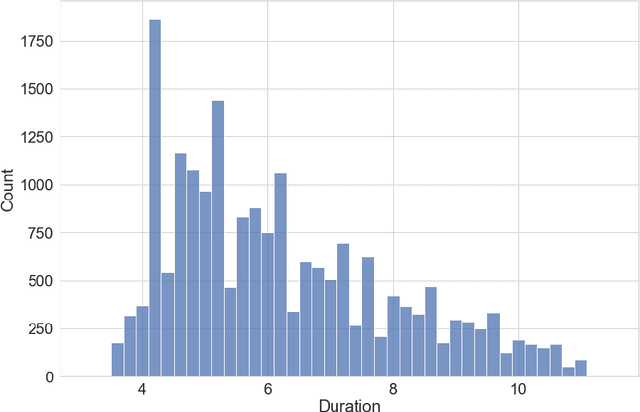

A recent trend in speech processing is the use of embeddings created through machine learning models trained on a specific task with large datasets. By leveraging the knowledge already acquired, these models can be reused in new tasks where the amount of available data is small. This paper proposes a pipeline to create a new model, called Mel and Wave Embeddings for Human Voice Tasks (MeWEHV), capable of generating robust embeddings for speech processing. MeWEHV combines the embeddings generated by a pre-trained raw audio waveform encoder model, and deep features extracted from Mel Frequency Cepstral Coefficients (MFCCs) using Convolutional Neural Networks (CNNs). We evaluate the performance of MeWEHV on three tasks: speaker, language, and accent identification. For the first one, we use the VoxCeleb1 dataset and present YouSpeakers204, a new and publicly available dataset for English speaker identification that contains 19607 audio clips from 204 persons speaking in six different accents, allowing other researchers to work with a very balanced dataset, and to create new models that are robust to multiple accents. For evaluating the language identification task, we use the VoxForge and Common Language datasets. Finally, for accent identification, we use the Latin American Spanish Corpora (LASC) and Common Voice datasets. Our approach allows a significant increase in the performance of state-of-the-art models on all the tested datasets, with a low additional computational cost.