 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERT: A Transfomer Based Model for Spatio-Temporal Sensor Data with Missing Values for Environmental Monitoring
Jun 09, 2023Environmental monitoring is crucial to our understanding of climate change, biodiversity loss and pollution. The availability of large-scale spatio-temporal data from sources such as sensors and satellites allows us to develop sophisticated models for forecasting and understanding key drivers. However, the data collected from sensors often contain missing values due to faulty equipment or maintenance issues. The missing values rarely occur simultaneously leading to data that are multivariate misaligned sparse time series. We propose two models that are capable of performing multivariate spatio-temporal forecasting while handling missing data naturally without the need for imputation. The first model is a transformer-based model, which we name SERT (Spatio-temporal Encoder Representations from Transformers). The second is a simpler model named SST-ANN (Sparse Spatio-Temporal Artificial Neural Network) which is capable of providing interpretable results. We conduct extensive experiments on two different datasets for multivariate spatio-temporal forecasting and show that our models have competitive or superior performance to those at the state-of-the-art.
Short Text Classification Approach to Identify Child Sexual Exploitation Material
Nov 13, 2020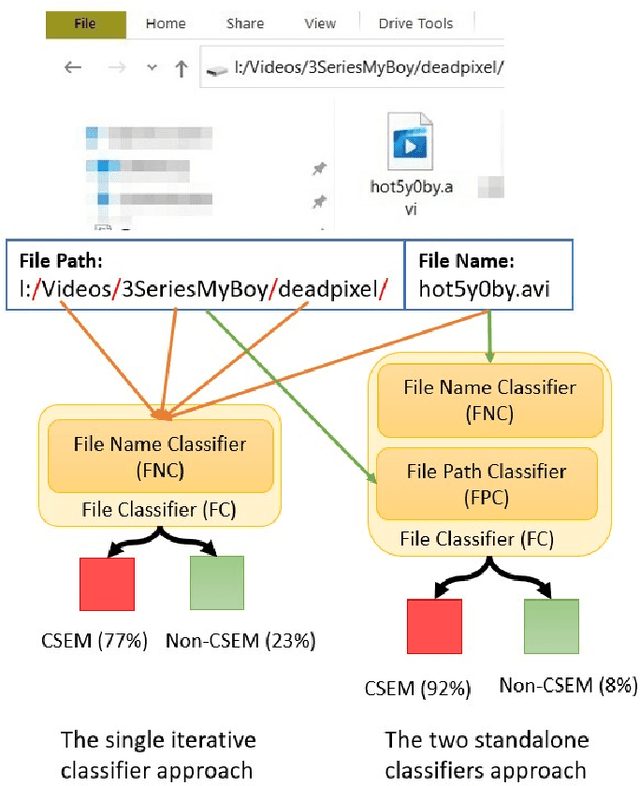
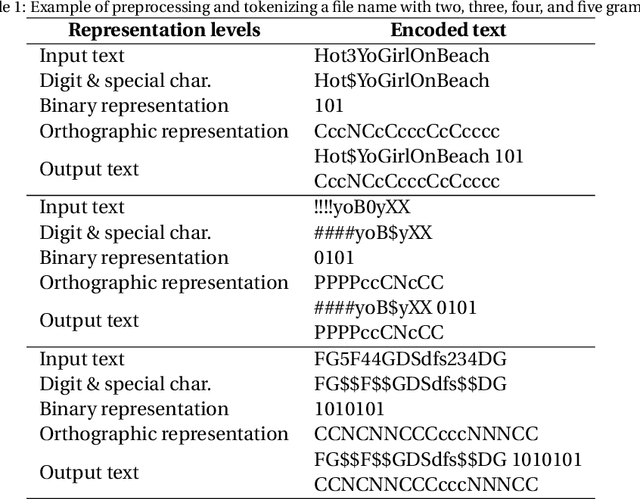
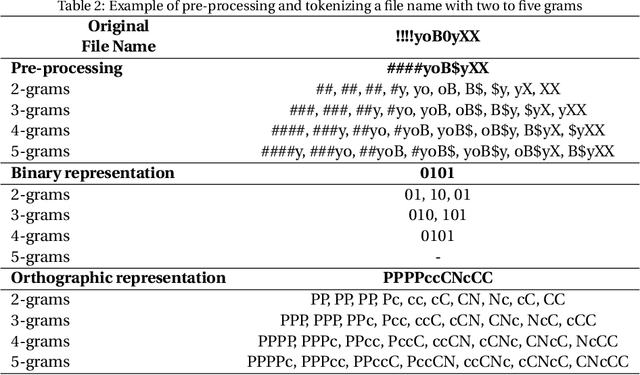

Producing or sharing Child Sexual Exploitation Material (CSEM) is a serious crime fought vigorously by Law Enforcement Agencies (LEAs). When an LEA seizes a computer from a potential producer or consumer of CSEM, they need to analyze the suspect's hard disk's files looking for pieces of evidence. However, a manual inspection of the file content looking for CSEM is a time-consuming task. In most cases, it is unfeasible in the amount of time available for the Spanish police using a search warrant. Instead of analyzing its content, another approach that can be used to speed up the process is to identify CSEM by analyzing the file names and their absolute paths. The main challenge for this task lies behind dealing with short text distorted deliberately by the owners of this material using obfuscated words and user-defined naming patterns. This paper presents and compares two approaches based on short text classification to identify CSEM files. The first one employs two independent supervised classifiers, one for the file name and the other for the path, and their outputs are later on fused into a single score. Conversely, the second approach uses only the file name classifier to iterate over the file's absolute path. Both approaches operate at the character n-grams level, while binary and orthographic features enrich the file name representation, and a binary Logistic Regression model is used for classification. The presented file classifier achieved an average class recall of 0.98. This solution could be integrated into forensic tools and services to support Law Enforcement Agencies to identify CSEM without tackling every file's visual content, which is computationally much more highly demanding.