 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Text Classification Approach to Identify Child Sexual Exploitation Material
Nov 13, 2020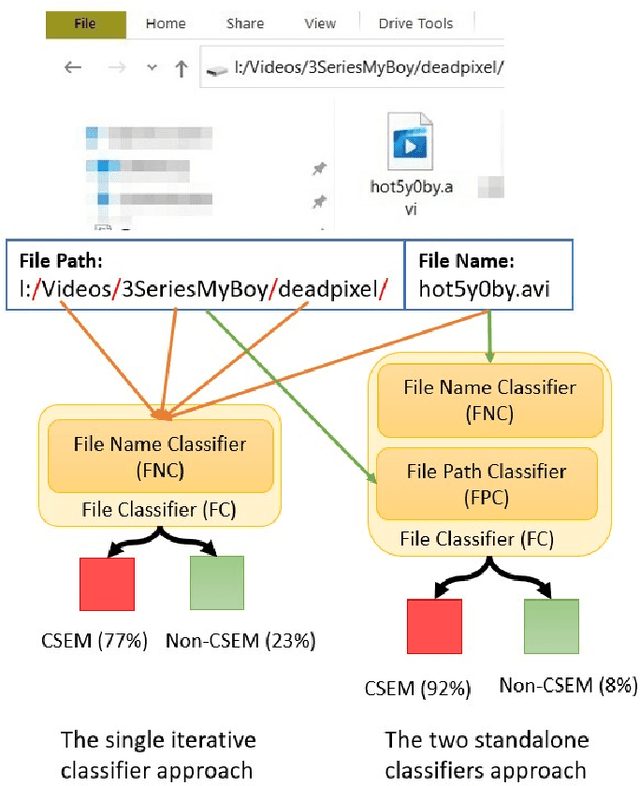
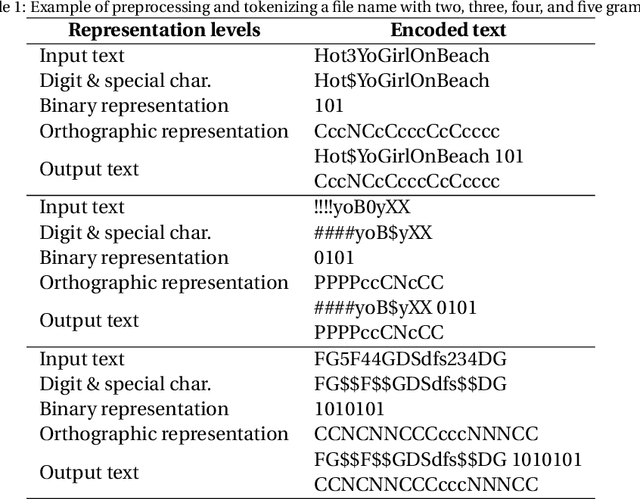
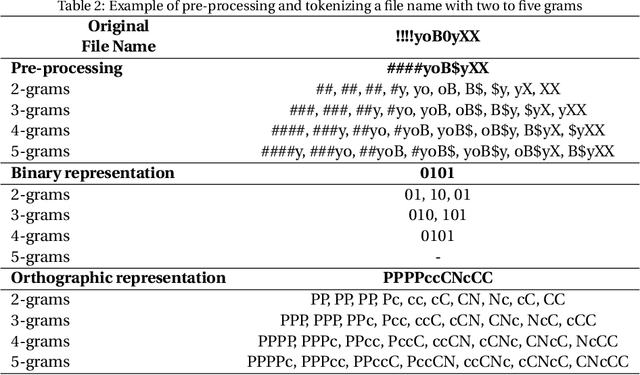

Producing or sharing Child Sexual Exploitation Material (CSEM) is a serious crime fought vigorously by Law Enforcement Agencies (LEAs). When an LEA seizes a computer from a potential producer or consumer of CSEM, they need to analyze the suspect's hard disk's files looking for pieces of evidence. However, a manual inspection of the file content looking for CSEM is a time-consuming task. In most cases, it is unfeasible in the amount of time available for the Spanish police using a search warrant. Instead of analyzing its content, another approach that can be used to speed up the process is to identify CSEM by analyzing the file names and their absolute paths. The main challenge for this task lies behind dealing with short text distorted deliberately by the owners of this material using obfuscated words and user-defined naming patterns. This paper presents and compares two approaches based on short text classification to identify CSEM files. The first one employs two independent supervised classifiers, one for the file name and the other for the path, and their outputs are later on fused into a single score. Conversely, the second approach uses only the file name classifier to iterate over the file's absolute path. Both approaches operate at the character n-grams level, while binary and orthographic features enrich the file name representation, and a binary Logistic Regression model is used for classification. The presented file classifier achieved an average class recall of 0.98. This solution could be integrated into forensic tools and services to support Law Enforcement Agencies to identify CSEM without tackling every file's visual content, which is computationally much more highly demanding.
Evaluating Performance of an Adult Pornography Classifier for Child Sexual Abuse Detection
May 18, 2020
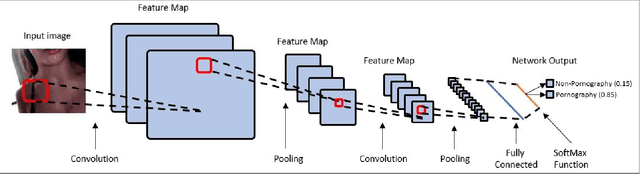


The information technology revolution has facilitated reaching pornographic material for everyone, including minors who are the most vulnerable in case they were abused. Accuracy and time performance are features desired by forensic tools oriented to child sexual abuse detection, whose main components may rely on image or video classifiers. In this paper, we identify which are the hardware and software requirements that may affect the performance of a forensic tool. We evaluated the adult porn classifier proposed by Yahoo, based on Deep Learning, into two different OS and four Hardware configurations, with two and four different CPU and GPU, respectively. The classification speed on Ubuntu Operating System is $~5$ and $~2$ times faster than on Windows 10, when a CPU and GPU are used, respectively. We demonstrate the superiority of a GPU-based machine rather than a CPU-based one, being $7$ to $8$ times faster. Finally, we prove that the upward and downward interpolation process conducted while resizing the input images do not influence the performance of the selected prediction model.
Improving Named Entity Recognition in Tor Darknet with Local Distance Neighbor Feature
May 18, 2020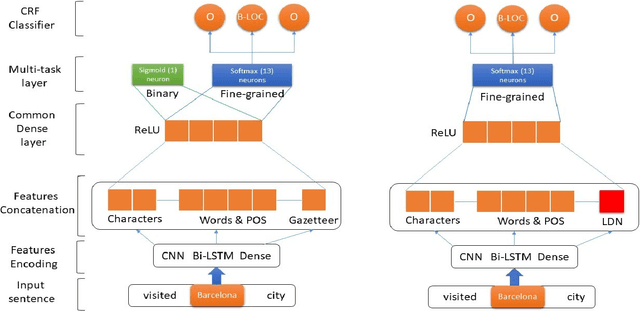
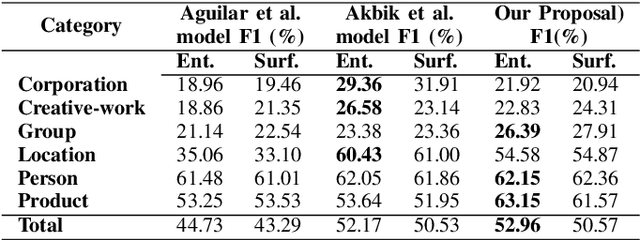
Name entity recognition in noisy user-generated texts is a difficult task usually enhanced by incorporating an external resource of information, such as gazetteers. However, gazetteers are task-specific, and they are expensive to build and maintain. This paper adopts and improves the approach of Aguilar et al. by presenting a novel feature, called Local Distance Neighbor, which substitutes gazetteers. We tested the new approach on the W-NUT-2017 dataset, obtaining state-of-the-art results for the Group, Person and Product categories of Named Entities. Next, we added 851 manually labeled samples to the W-NUT-2017 dataset to account for named entities in the Tor Darknet related to weapons and drug selling. Finally, our proposal achieved an entity and surface F1 scores of 52.96% and 50.57% on this extended dataset, demonstrating its usefulness for Law Enforcement Agencies to detect named entities in the Tor hidden services.
Content-Based Features to Rank Influential Hidden Services of the Tor Darknet
Oct 05, 2019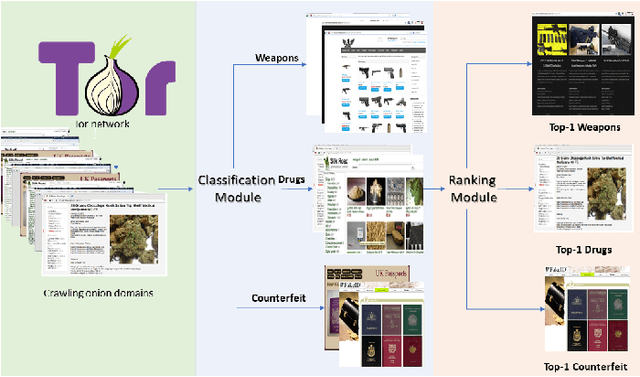
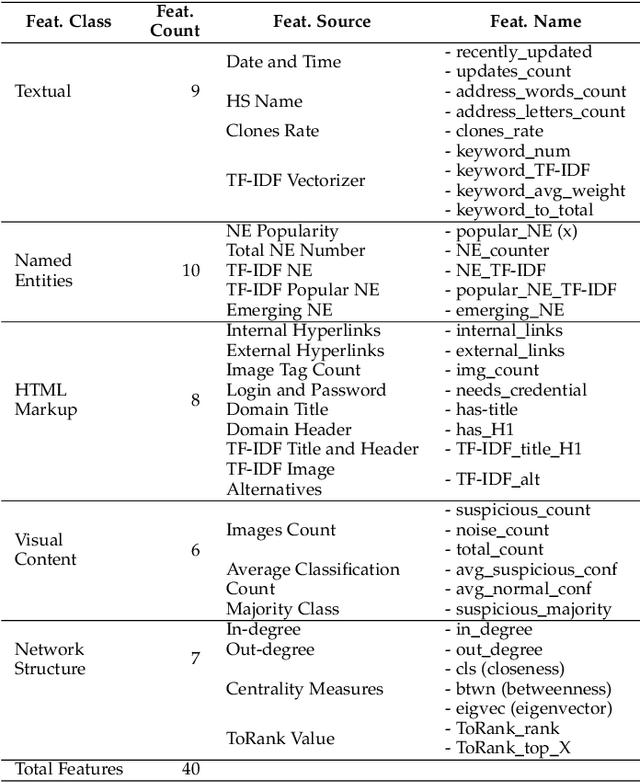
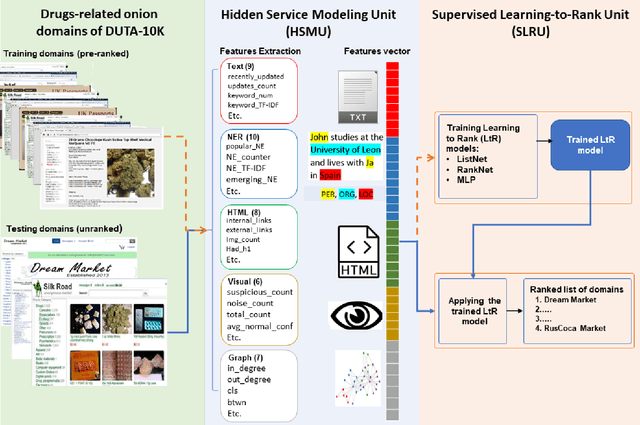

The unevenness importance of criminal activities in the onion domains of the Tor Darknet and the different levels of their appeal to the end-user make them tangled to measure their influence. To this end, this paper presents a novel content-based ranking framework to detect the most influential onion domains. Our approach comprises a modeling unit that represents an onion domain using forty features extracted from five different resources: user-visible text, HTML markup, Named Entities, network topology, and visual content. And also, a ranking unit that, using the Learning-to-Rank (LtR) approach, automatically learns a ranking function by integrating the previously obtained features. Using a case-study based on drugs-related onion domains, we obtained the following results. (1) Among the explored LtR schemes, the listwise approach outperforms the benchmarked methods with an NDCG of 0.95 for the top-10 ranked domains. (2) We proved quantitatively that our framework surpasses the link-based ranking techniques. Also, (3) with the selected feature, we observed that the textual content, composed by text, NER, and HTML features, is the most balanced approach, in terms of efficiency and score obtained. The proposed framework might support Law Enforcement Agencies in detecting the most influential domains related to possible suspicious activities.