 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Based Features to Rank Influential Hidden Services of the Tor Darknet
Paper and Code
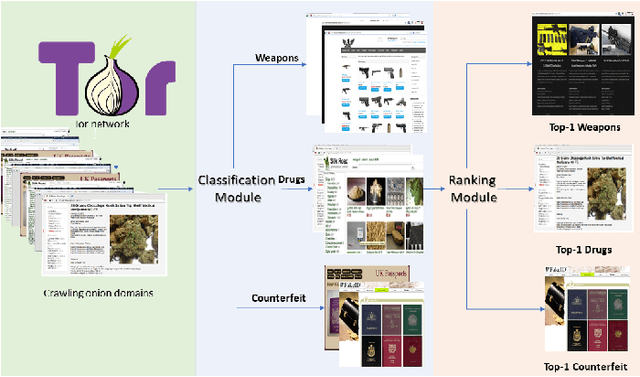
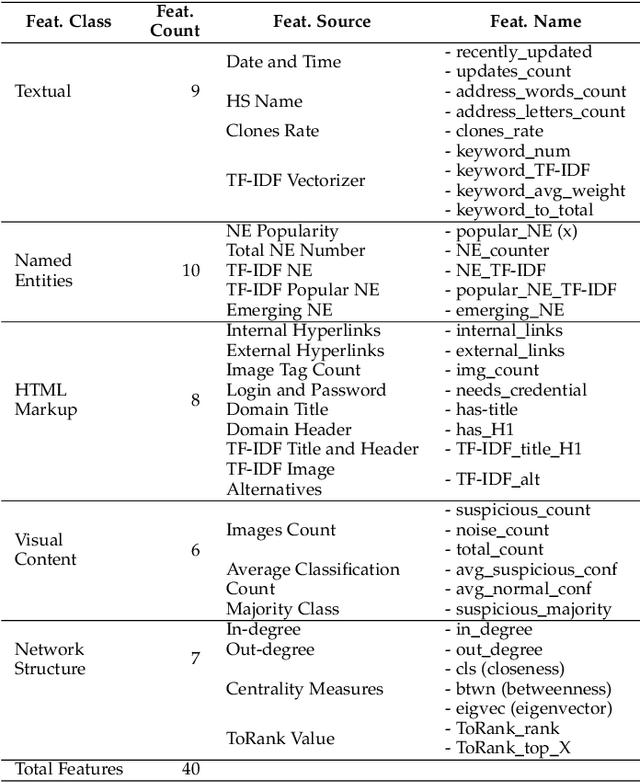
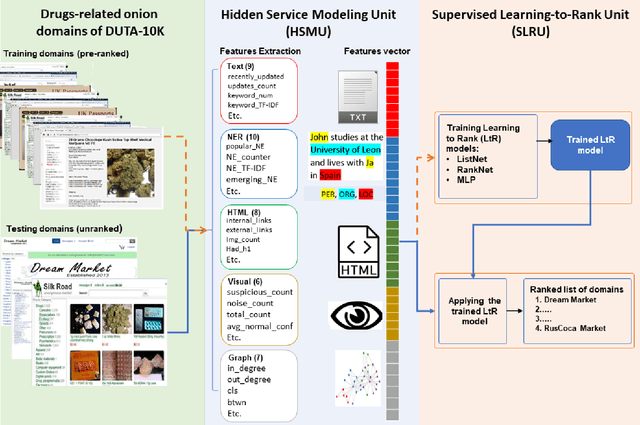

The unevenness importance of criminal activities in the onion domains of the Tor Darknet and the different levels of their appeal to the end-user make them tangled to measure their influence. To this end, this paper presents a novel content-based ranking framework to detect the most influential onion domains. Our approach comprises a modeling unit that represents an onion domain using forty features extracted from five different resources: user-visible text, HTML markup, Named Entities, network topology, and visual content. And also, a ranking unit that, using the Learning-to-Rank (LtR) approach, automatically learns a ranking function by integrating the previously obtained features. Using a case-study based on drugs-related onion domains, we obtained the following results. (1) Among the explored LtR schemes, the listwise approach outperforms the benchmarked methods with an NDCG of 0.95 for the top-10 ranked domains. (2) We proved quantitatively that our framework surpasses the link-based ranking techniques. Also, (3) with the selected feature, we observed that the textual content, composed by text, NER, and HTML features, is the most balanced approach, in terms of efficiency and score obtained. The proposed framework might support Law Enforcement Agencies in detecting the most influential domains related to possible suspicious activities.