 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Detection of Botnet Traffic by features selection and Decision Trees
Jun 30, 2021Botnets are one of the online threats with the biggest presence, causing billionaire losses to global economies. Nowadays, the increasing number of devices connected to the Internet makes it necessary to analyze large amounts of network traffic data. In this work, we focus on increasing the performance on botnet traffic classification by selecting those features that further increase the detection rate. For this purpose we use two feature selection techniques, Information Gain and Gini Importance, which led to three pre-selected subsets of five, six and seven features. Then, we evaluate the three feature subsets along with three models, Decision Tree, Random Forest and k-Nearest Neighbors. To test the performance of the three feature vectors and the three models we generate two datasets based on the CTU-13 dataset, namely QB-CTU13 and EQB-CTU13. We measure the performance as the macro averaged F1 score over the computational time required to classify a sample. The results show that the highest performance is achieved by Decision Trees using a five feature set which obtained a mean F1 score of 85% classifying each sample in an average time of 0.78 microseconds.
Classification of Spam Emails through Hierarchical Clustering and Supervised Learning
May 28, 2020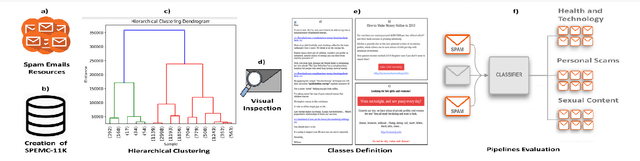
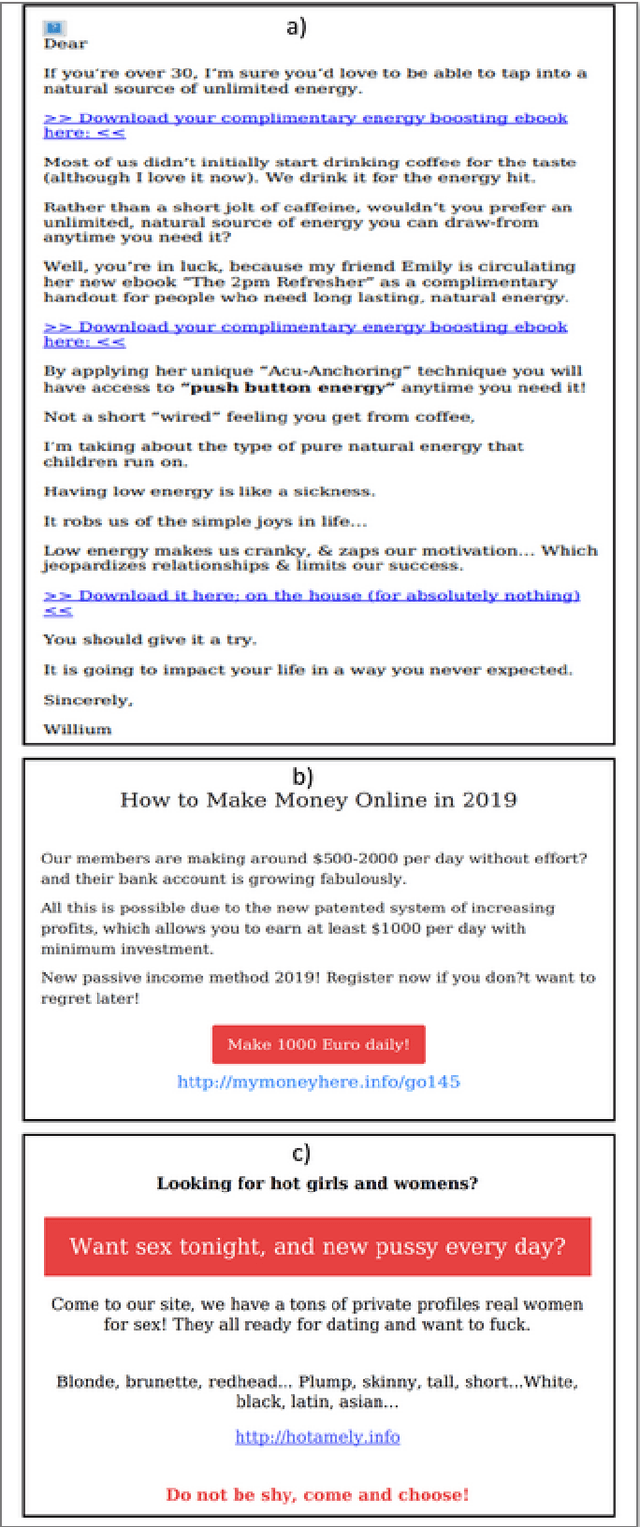
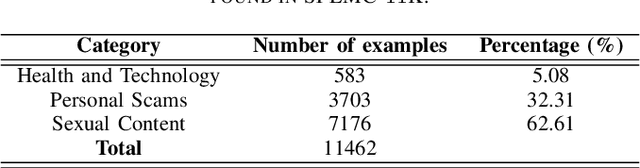
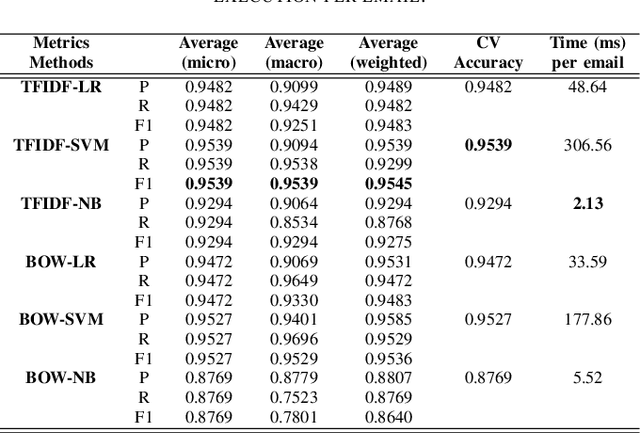
Spammers take advantage of email popularity to send indiscriminately unsolicited emails. Although researchers and organizations continuously develop anti-spam filters based on binary classification, spammers bypass them through new strategies, like word obfuscation or image-based spam. For the first time in literature, we propose to classify spam email in categories to improve the handle of already detected spam emails, instead of just using a binary model. First, we applied a hierarchical clustering algorithm to create SPEMC-$11$K (SPam EMail Classification), the first multi-class dataset, which contains three types of spam emails: Health and Technology, Personal Scams, and Sexual Content. Then, we used SPEMC-$11$K to evaluate the combination of TF-IDF and BOW encodings with Na\"ive Bayes, Decision Trees and SVM classifiers. Finally, we recommend for the task of multi-class spam classification the use of (i) TF-IDF combined with SVM for the best micro F1 score performance, $95.39\%$, and (ii) TD-IDF along with NB for the fastest spam classification, analyzing an email in $2.13$ms.
Evaluating Performance of an Adult Pornography Classifier for Child Sexual Abuse Detection
May 18, 2020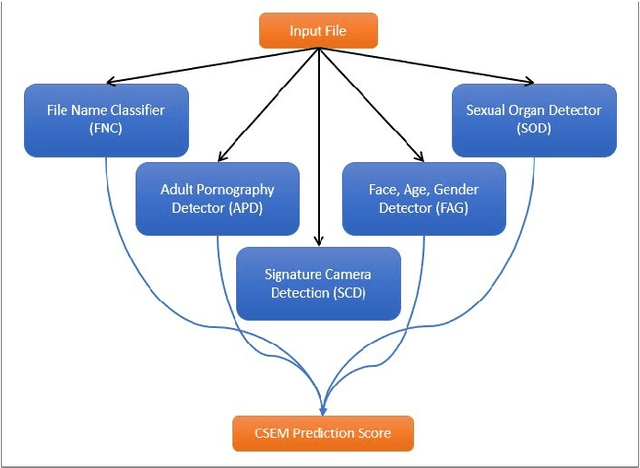
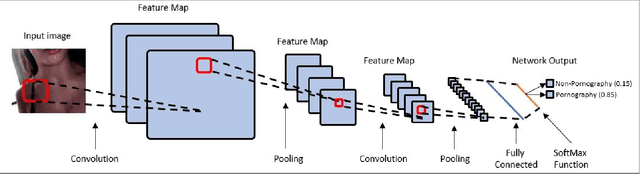


The information technology revolution has facilitated reaching pornographic material for everyone, including minors who are the most vulnerable in case they were abused. Accuracy and time performance are features desired by forensic tools oriented to child sexual abuse detection, whose main components may rely on image or video classifiers. In this paper, we identify which are the hardware and software requirements that may affect the performance of a forensic tool. We evaluated the adult porn classifier proposed by Yahoo, based on Deep Learning, into two different OS and four Hardware configurations, with two and four different CPU and GPU, respectively. The classification speed on Ubuntu Operating System is $~5$ and $~2$ times faster than on Windows 10, when a CPU and GPU are used, respectively. We demonstrate the superiority of a GPU-based machine rather than a CPU-based one, being $7$ to $8$ times faster. Finally, we prove that the upward and downward interpolation process conducted while resizing the input images do not influence the performance of the selected prediction model.
Improving Named Entity Recognition in Tor Darknet with Local Distance Neighbor Feature
May 18, 2020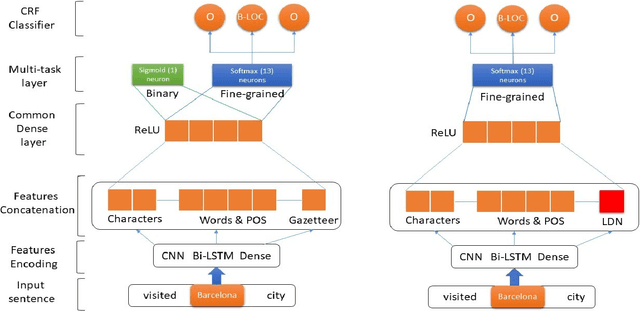
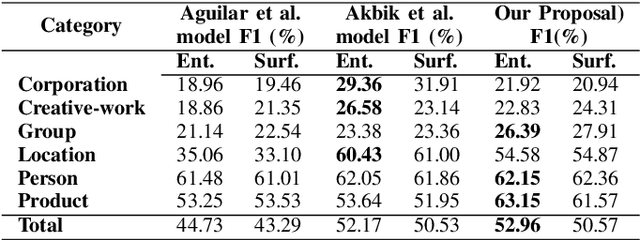
Name entity recognition in noisy user-generated texts is a difficult task usually enhanced by incorporating an external resource of information, such as gazetteers. However, gazetteers are task-specific, and they are expensive to build and maintain. This paper adopts and improves the approach of Aguilar et al. by presenting a novel feature, called Local Distance Neighbor, which substitutes gazetteers. We tested the new approach on the W-NUT-2017 dataset, obtaining state-of-the-art results for the Group, Person and Product categories of Named Entities. Next, we added 851 manually labeled samples to the W-NUT-2017 dataset to account for named entities in the Tor Darknet related to weapons and drug selling. Finally, our proposal achieved an entity and surface F1 scores of 52.96% and 50.57% on this extended dataset, demonstrating its usefulness for Law Enforcement Agencies to detect named entities in the Tor hidden services.