 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep supervised hashing for fast retrieval of radio image cubes
Sep 02, 2023
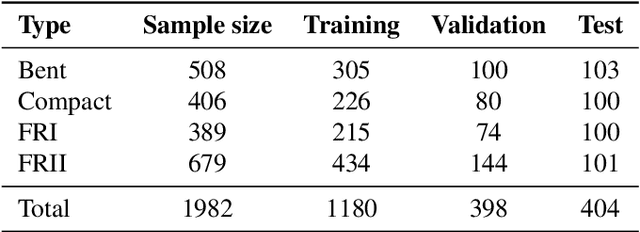


The shear number of sources that will be detected by next-generation radio surveys will be astronomical, which will result in serendipitous discoveries. Data-dependent deep hashing algorithms have been shown to be efficient at image retrieval tasks in the fields of computer vision and multimedia. However, there are limited applications of these methodologies in the field of astronomy. In this work, we utilize deep hashing to rapidly search for similar images in a large database. The experiment uses a balanced dataset of 2708 samples consisting of four classes: Compact, FRI, FRII, and Bent. The performance of the method was evaluated using the mean average precision (mAP) metric where a precision of 88.5\% was achieved. The experimental results demonstrate the capability to search and retrieve similar radio images efficiently and at scale. The retrieval is based on the Hamming distance between the binary hash of the query image and those of the reference images in the database.
Advances on the classification of radio image cubes
May 05, 2023



Modern radio telescopes will daily generate data sets on the scale of exabytes for systems like the Square Kilometre Array (SKA). Massive data sets are a source of unknown and rare astrophysical phenomena that lead to discoveries. Nonetheless, this is only plausible with the exploitation of intensive machine intelligence to complement human-aided and traditional statistical techniques. Recently, there has been a surge in scientific publications focusing on the use of artificial intelligence in radio astronomy, addressing challenges such as source extraction, morphological classification, and anomaly detection. This study presents a succinct, but comprehensive review of the application of machine intelligence techniques on radio images with emphasis on the morphological classification of radio galaxies. It aims to present a detailed synthesis of the relevant papers summarizing the literature based on data complexity, data pre-processing, and methodological novelty in radio astronomy. The rapid advancement and application of computer intelligence in radio astronomy has resulted in a revolution and a new paradigm shift in the automation of daunting data processes. However, the optimal exploitation of artificial intelligence in radio astronomy, calls for continued collaborative efforts in the creation of annotated data sets. Additionally, in order to quickly locate radio galaxies with similar or dissimilar physical characteristics, it is necessary to index the identified radio sources. Nonetheless, this issue has not been adequately addressed in the literature, making it an open area for further study.
To remove or not remove Mobile Apps? A data-driven predictive model approach
Jun 08, 2022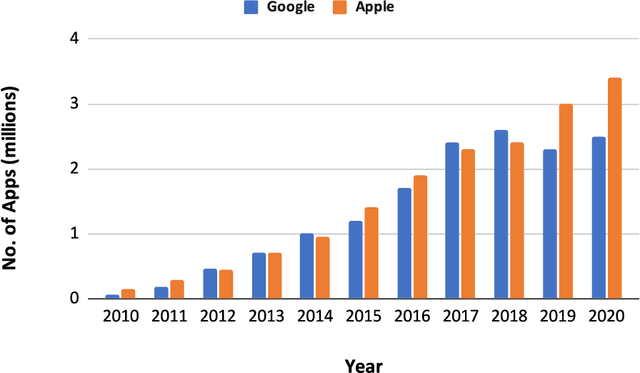
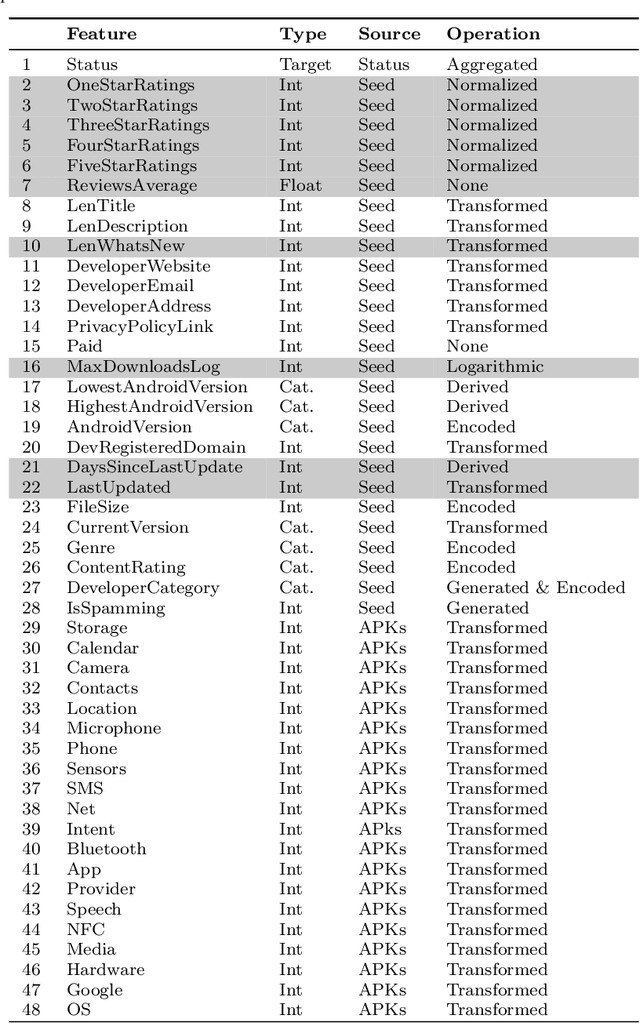
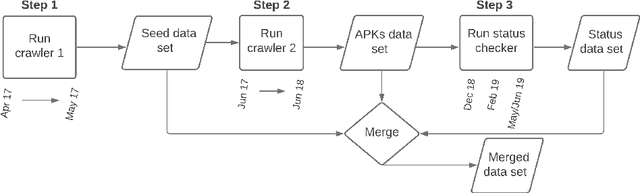
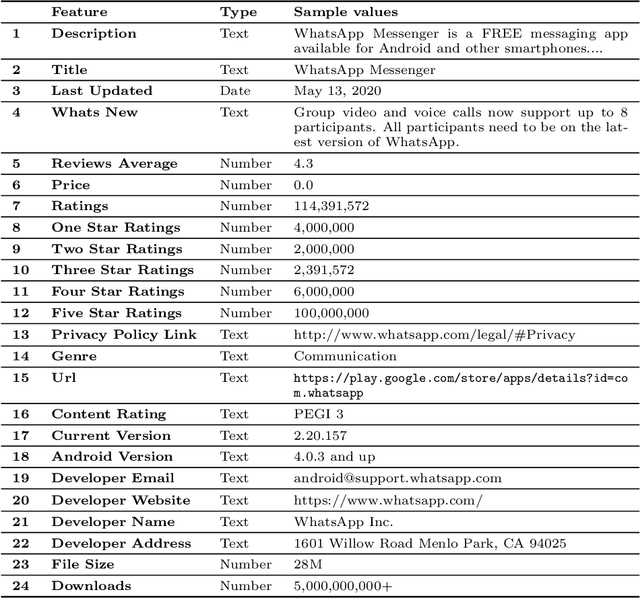
Mobile app stores are the key distributors of mobile applications. They regularly apply vetting processes to the deployed apps. Yet, some of these vetting processes might be inadequate or applied late. The late removal of applications might have unpleasant consequences for developers and users alike. Thus, in this work we propose a data-driven predictive approach that determines whether the respective app will be removed or accepted. It also indicates the features' relevance that help the stakeholders in the interpretation. In turn, our approach can support developers in improving their apps and users in downloading the ones that are less likely to be removed. We focus on the Google App store and we compile a new data set of 870,515 applications, 56% of which have actually been removed from the market. Our proposed approach is a bootstrap aggregating of multiple XGBoost machine learning classifiers. We propose two models: user-centered using 47 features, and developer-centered using 37 features, the ones only available before deployment. We achieve the following Areas Under the ROC Curves (AUCs) on the test set: user-centered = 0.792, developer-centered = 0.762.
Device-based Image Matching with Similarity Learning by Convolutional Neural Networks that Exploit the Underlying Camera Sensor Pattern Noise
Apr 23, 2020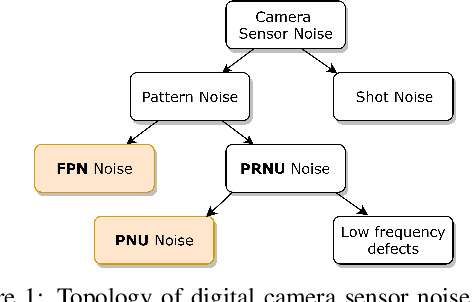
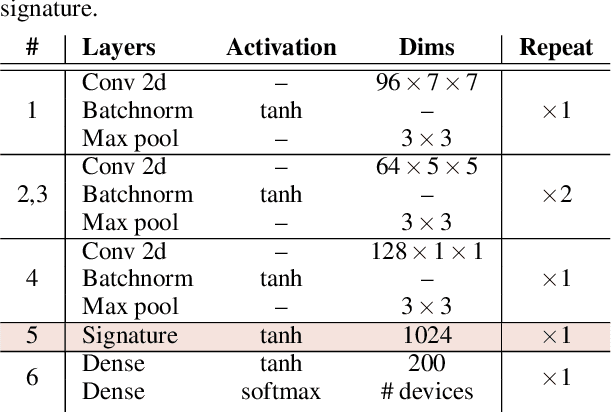
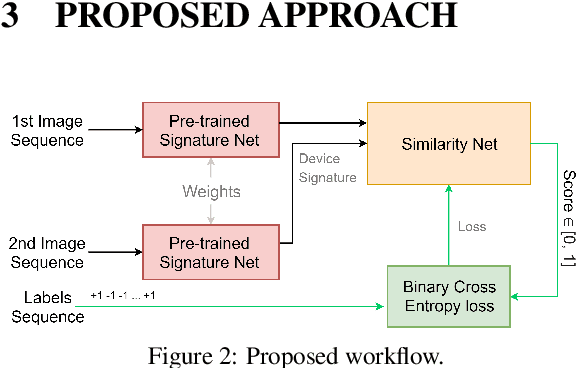
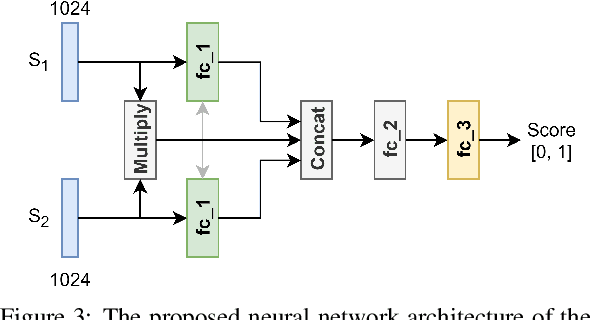
One of the challenging problems in digital image forensics is the capability to identify images that are captured by the same camera device. This knowledge can help forensic experts in gathering intelligence about suspects by analyzing digital images. In this paper, we propose a two-part network to quantify the likelihood that a given pair of images have the same source camera, and we evaluated it on the benchmark Dresden data set containing 1851 images from 31 different cameras. To the best of our knowledge, we are the first ones addressing the challenge of device-based image matching. Though the proposed approach is not yet forensics ready, our experiments show that this direction is worth pursuing, achieving at this moment 85 percent accuracy. This ongoing work is part of the EU-funded project 4NSEEK concerned with forensics against child sexual abuse.
* 7 pages, 4 figures, conference paper