 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024

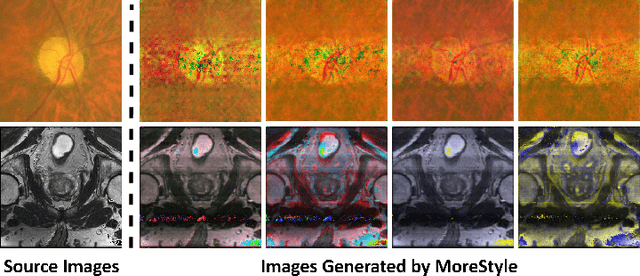

The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
Deformable Mixer Transformer with Gating for Multi-Task Learning of Dense Prediction
Aug 18, 2023



CNNs and Transformers have their own advantages and both have been widely used for dense prediction in multi-task learning (MTL). Most of the current studies on MTL solely rely on CNN or Transformer. In this work, we present a novel MTL model by combining both merits of deformable CNN and query-based Transformer with shared gating for multi-task learning of dense prediction. This combination may offer a simple and efficient solution owing to its powerful and flexible task-specific learning and advantages of lower cost, less complexity and smaller parameters than the traditional MTL methods. We introduce deformable mixer Transformer with gating (DeMTG), a simple and effective encoder-decoder architecture up-to-date that incorporates the convolution and attention mechanism in a unified network for MTL. It is exquisitely designed to use advantages of each block, and provide deformable and comprehensive features for all tasks from local and global perspective. First, the deformable mixer encoder contains two types of operators: the channel-aware mixing operator leveraged to allow communication among different channels, and the spatial-aware deformable operator with deformable convolution applied to efficiently sample more informative spatial locations. Second, the task-aware gating transformer decoder is used to perform the task-specific predictions, in which task interaction block integrated with self-attention is applied to capture task interaction features, and the task query block integrated with gating attention is leveraged to select corresponding task-specific features. Further, the experiment results demonstrate that the proposed DeMTG uses fewer GFLOPs and significantly outperforms current Transformer-based and CNN-based competitive models on a variety of metrics on three dense prediction datasets. Our code and models are available at https://github.com/yangyangxu0/DeMTG.
CLNode: Curriculum Learning for Node Classification
Jun 15, 2022
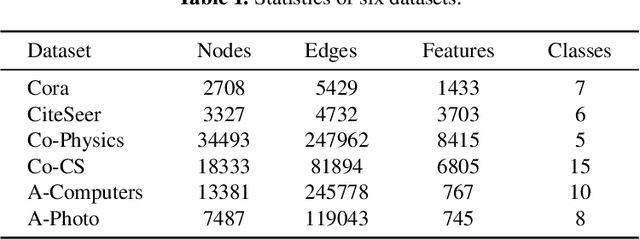


Node classification is a fundamental graph-based task that aims to predict the classes of unlabeled nodes, for which Graph Neural Networks (GNNs) are the state-of-the-art methods. In current GNNs, training nodes (or training samples) are treated equally throughout training. The quality of the samples, however, varies greatly according to the graph structure. Consequently, the performance of GNNs could be harmed by two types of low-quality samples: (1) Inter-class nodes situated near class boundaries that connect neighboring classes. These nodes' representations lack the typical characteristics of their corresponding classes. Because GNNs are data-driven approaches, training on these nodes could degrade the accuracy. (2) Mislabeled nodes. In real-world graphs, nodes are often mislabeled, which can significantly degrade the robustness of GNNs. To mitigate the detrimental effect of the low-quality samples, we present CLNode (Curriculum Learning for Node Classification), which automatically adjusts the weights of samples during training based on their quality. Specifically, we first design a neighborhood-based difficulty measurer to accurately measure the quality of samples. Subsequently, based on these measurements, we employ a training scheduler to adjust the sample weights in each training epoch. To evaluate the effectiveness of CLNode, we conduct extensive experiments by applying it to four representative backbone GNNs. Experimental results on six real-world networks demonstrate that CLNode is a general framework that can be combined with various GNNs to improve their accuracy and robustness.