 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLNode: Curriculum Learning for Node Classification
Paper and Code

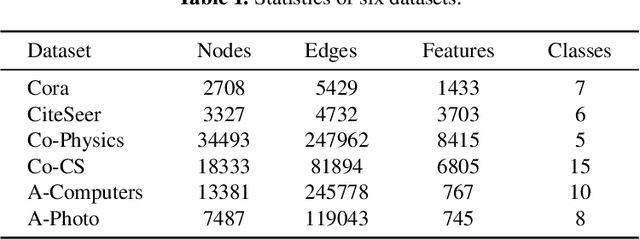


Node classification is a fundamental graph-based task that aims to predict the classes of unlabeled nodes, for which Graph Neural Networks (GNNs) are the state-of-the-art methods. In current GNNs, training nodes (or training samples) are treated equally throughout training. The quality of the samples, however, varies greatly according to the graph structure. Consequently, the performance of GNNs could be harmed by two types of low-quality samples: (1) Inter-class nodes situated near class boundaries that connect neighboring classes. These nodes' representations lack the typical characteristics of their corresponding classes. Because GNNs are data-driven approaches, training on these nodes could degrade the accuracy. (2) Mislabeled nodes. In real-world graphs, nodes are often mislabeled, which can significantly degrade the robustness of GNNs. To mitigate the detrimental effect of the low-quality samples, we present CLNode (Curriculum Learning for Node Classification), which automatically adjusts the weights of samples during training based on their quality. Specifically, we first design a neighborhood-based difficulty measurer to accurately measure the quality of samples. Subsequently, based on these measurements, we employ a training scheduler to adjust the sample weights in each training epoch. To evaluate the effectiveness of CLNode, we conduct extensive experiments by applying it to four representative backbone GNNs. Experimental results on six real-world networks demonstrate that CLNode is a general framework that can be combined with various GNNs to improve their accuracy and robustness.