 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of uncertainty estimation approaches for DNN-based camera localization
Nov 02, 2022



Camera localization, i.e., camera pose regression, represents a very important task in computer vision, since it has many practical applications, such as autonomous driving. A reliable estimation of the uncertainties in camera localization is also important, as it would allow to intercept localization failures, which would be dangerous. Even though the literature presents some uncertainty estimation methods, to the best of our knowledge their effectiveness has not been thoroughly examined. This work compares the performances of three consolidated epistemic uncertainty estimation methods: Monte Carlo Dropout (MCD), Deep Ensemble (DE), and Deep Evidential Regression (DER), in the specific context of camera localization. We exploited CMRNet, a DNN approach for multi-modal image to LiDAR map registration, by modifying its internal configuration to allow for an extensive experimental activity with the three methods on the KITTI dataset. Particularly significant has been the application of DER. We achieve accurate camera localization and a calibrated uncertainty, to the point that some method can be used for detecting localization failures.
CMRNet++: Map and Camera Agnostic Monocular Visual Localization in LiDAR Maps
May 22, 2020

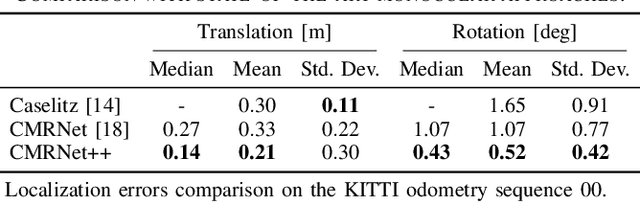
Localization is a critically essential and crucial enabler of autonomous robots. While deep learning has made significant strides in many computer vision tasks, it is still yet to make a sizeable impact on improving capabilities of metric visual localization. One of the major hindrances has been the inability of existing Convolutional Neural Network (CNN)-based pose regression methods to generalize to previously unseen places. Our recently introduced CMRNet effectively addresses this limitation by enabling map independent monocular localization in LiDAR-maps. In this paper, we now take it a step further by introducing CMRNet++, which is a significantly more robust model that not only generalizes to new places effectively, but is also independent of the camera parameters. We enable this capability by combining deep learning with geometric techniques, and by moving the metric reasoning outside the learning process. In this way, the weights of the network are not tied to a specific camera. Extensive evaluations of CMRNet++ on three challenging autonomous driving datasets, i.e., KITTI, Argoverse, and Lyft5, show that CMRNet++ outperforms CMRNet as well as other baselines by a large margin. More importantly, for the first-time, we demonstrate the ability of a deep learning approach to accurately localize without any retraining or fine-tuning in a completely new environment and independent of the camera parameters.
A Benchmark for Point Clouds Registration Algorithms
Apr 06, 2020
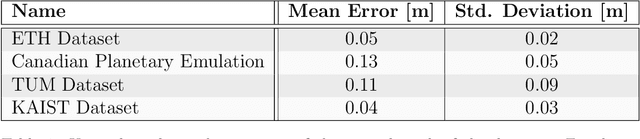

Point clouds registration is a fundamental step of many point clouds processing pipelines; however, most algorithms are tested on data collected ad-hoc and not shared with the research community. These data often cover only a very limited set of use cases; therefore, the results cannot be generalised. Public datasets proposed until now, taken individually, cover only a few kinds of environment and mostly a single sensor. For these reasons, we developed a benchmark, for localization and mapping applications, using multiple publicly available datasets. In this way, we have been able to cover many kinds of environments and many kinds of sensor that can produce point clouds. Furthermore, the ground truth has been thoroughly inspected and evaluated to ensure its quality. For some of the datasets, the accuracy of the ground truth system was not reported by the original authors, therefore we estimated it with our own novel method, based on an iterative registration algorithm. Along with the data, we provide a broad set of registration problems, chosen to cover different types of initial misalignment, various degrees of overlap, and different kinds of registration problems. Lastly, we propose a metric to measure the performances of registration algorithms: it combines the commonly used rotation and translation errors together, to allow an objective comparison of the alignments. This work aims at encouraging authors to use a public and shared benchmark, instead than data collected ad-hoc, to ensure objectivity and repeatability, two fundamental characteristics in any scientific field.
Vehicle Ego-Lane Estimation with Sensor Failure Modeling
Feb 06, 2020



We present a probabilistic ego-lane estimation algorithm for highway-like scenarios that is designed to increase the accuracy of the ego-lane estimate, which can be obtained relying only on a noisy line detector and tracker. The contribution relies on a Hidden Markov Model (HMM) with a transient failure model. The proposed algorithm exploits the OpenStreetMap (or other cartographic services) road property lane number as the expected number of lanes and leverages consecutive, possibly incomplete, observations. The algorithm effectiveness is proven by employing different line detectors and showing we could achieve much more usable, i.e. stable and reliable, ego-lane estimates over more than 100 Km of highway scenarios, recorded both in Italy and Spain. Moreover, as we could not find a suitable dataset for a quantitative comparison with other approaches, we collected datasets and manually annotated the Ground Truth about the vehicle ego-lane. Such datasets are made publicly available for usage from the scientific community.
Global visual localization in LiDAR-maps through shared 2D-3D embedding space
Oct 02, 2019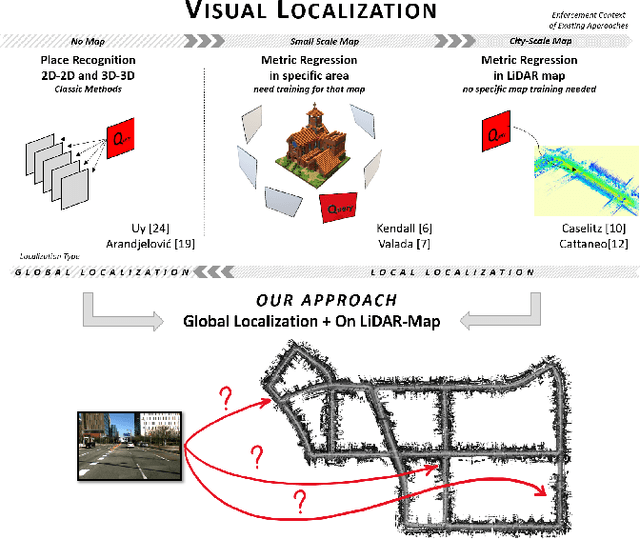
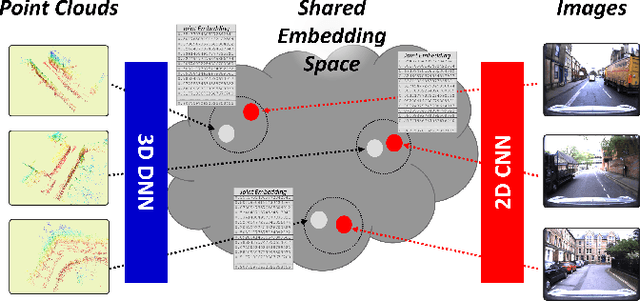
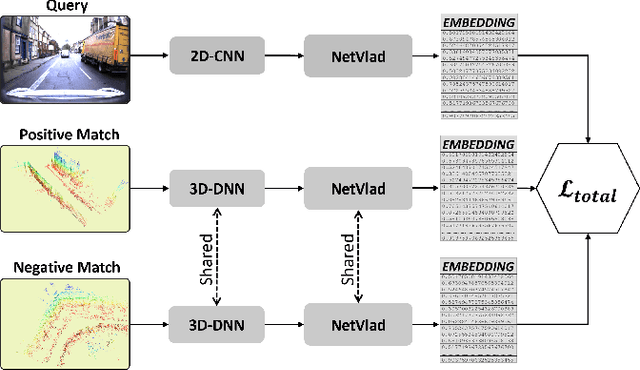
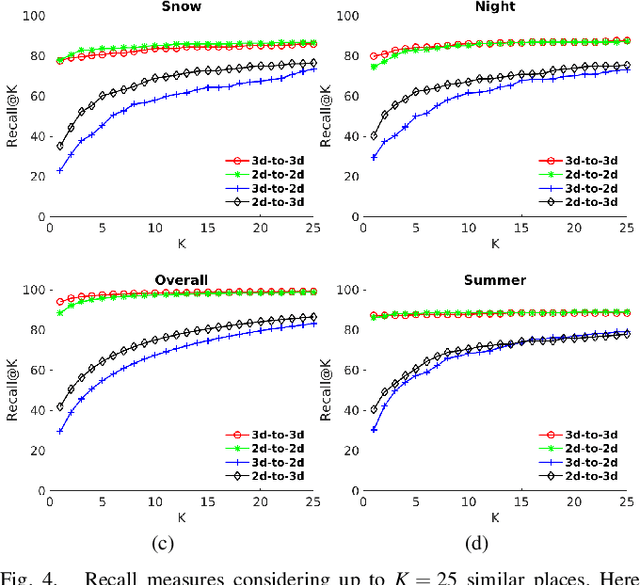
Global localization is an important and widely studied problem for many robotic applications. Place recognition approaches can be exploited to solve this task, e.g., in the autonomous driving field. While most vision-based approaches match an image w.r.t an image database, global visual localization within LiDAR-maps remains fairly unexplored, even though the path toward high definition 3D maps, produced mainly from LiDARs, is clear. In this work we leverage DNN approaches to create a shared embedding space between images and LiDAR-maps, allowing for image to 3D-LiDAR place recognition. We trained a 2D and a 3D Deep Neural Networks (DNNs) that create embeddings, respectively from images and from point clouds, that are close to each other whether they refer to the same place. An extensive experimental activity is presented to assess the effectiveness of the approach w.r.t. different learning methods, network architectures, and loss functions. All the evaluations have been performed using the Oxford Robotcar Dataset, which encompasses a wide range of weather and light conditions.
CMRNet: Camera to LiDAR-Map Registration
Jul 17, 2019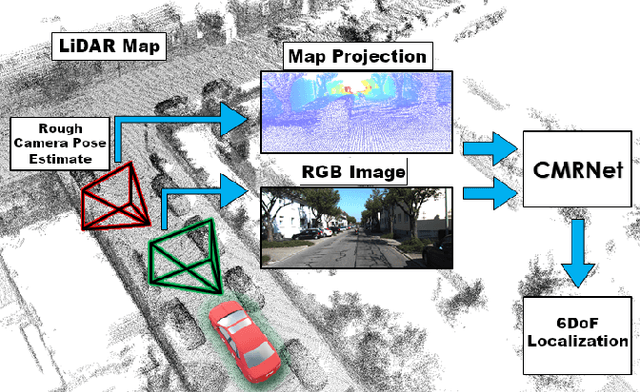


In this paper we present CMRNet, a realtime approach based on a Convolutional Neural Network to localize an RGB image of a scene in a map built from LiDAR data. Our network is not trained in the working area, i.e. CMRNet does not learn the map. Instead it learns to match an image to the map. We validate our approach on the KITTI dataset, processing each frame independently without any tracking procedure. CMRNet achieves 0.27m and 1.07deg median localization accuracy on the sequence 00 of the odometry dataset, starting from a rough pose estimate displaced up to 3.5m and 17deg. To the best of our knowledge this is the first CNN-based approach that learns to match images from a monocular camera to a given, preexisting 3D LiDAR-map.