 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMRNet++: Map and Camera Agnostic Monocular Visual Localization in LiDAR Maps
Paper and Code


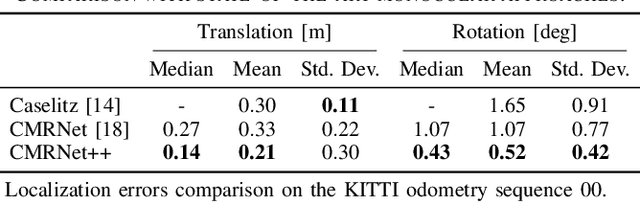
Localization is a critically essential and crucial enabler of autonomous robots. While deep learning has made significant strides in many computer vision tasks, it is still yet to make a sizeable impact on improving capabilities of metric visual localization. One of the major hindrances has been the inability of existing Convolutional Neural Network (CNN)-based pose regression methods to generalize to previously unseen places. Our recently introduced CMRNet effectively addresses this limitation by enabling map independent monocular localization in LiDAR-maps. In this paper, we now take it a step further by introducing CMRNet++, which is a significantly more robust model that not only generalizes to new places effectively, but is also independent of the camera parameters. We enable this capability by combining deep learning with geometric techniques, and by moving the metric reasoning outside the learning process. In this way, the weights of the network are not tied to a specific camera. Extensive evaluations of CMRNet++ on three challenging autonomous driving datasets, i.e., KITTI, Argoverse, and Lyft5, show that CMRNet++ outperforms CMRNet as well as other baselines by a large margin. More importantly, for the first-time, we demonstrate the ability of a deep learning approach to accurately localize without any retraining or fine-tuning in a completely new environment and independent of the camera parameters.