 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Visual Recognition with Deep Neural Networks: A Survey on Recent Advances and New Directions
Sep 09, 2021
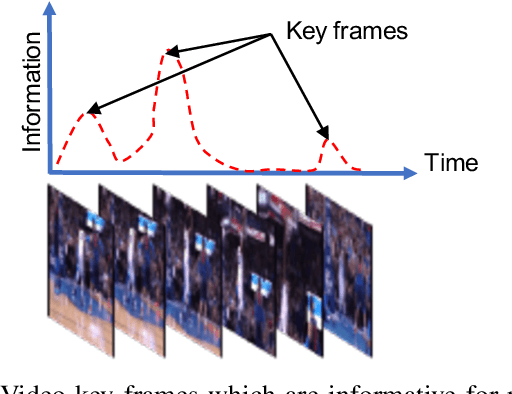
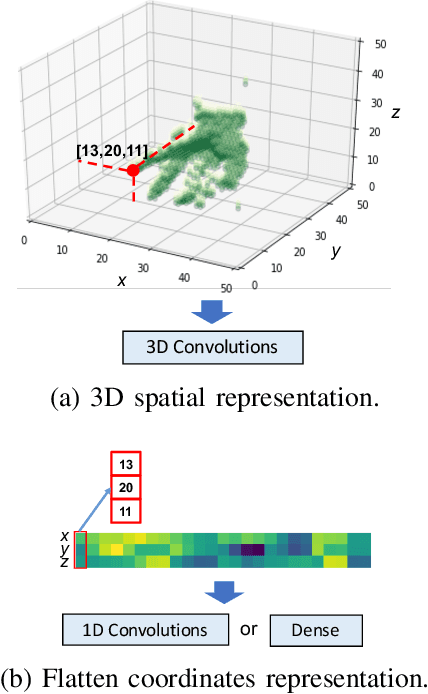
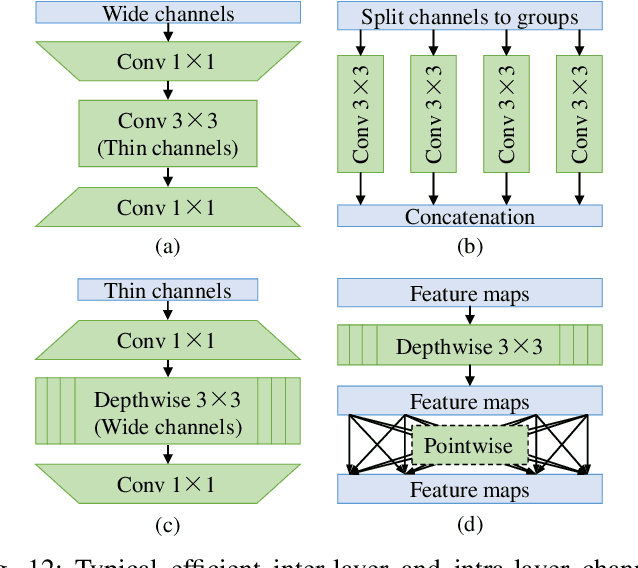
Visual recognition is currently one of the most important and active research areas in computer vision, pattern recognition, and even the general field of artificial intelligence. It has great fundamental importance and strong industrial needs. Deep neural networks (DNNs) have largely boosted their performances on many concrete tasks, with the help of large amounts of training data and new powerful computation resources. Though recognition accuracy is usually the first concern for new progresses, efficiency is actually rather important and sometimes critical for both academic research and industrial applications. Moreover, insightful views on the opportunities and challenges of efficiency are also highly required for the entire community. While general surveys on the efficiency issue of DNNs have been done from various perspectives, as far as we are aware, scarcely any of them focused on visual recognition systematically, and thus it is unclear which progresses are applicable to it and what else should be concerned. In this paper, we present the review of the recent advances with our suggestions on the new possible directions towards improving the efficiency of DNN-related visual recognition approaches. We investigate not only from the model but also the data point of view (which is not the case in existing surveys), and focus on three most studied data types (images, videos and points). This paper attempts to provide a systematic summary via a comprehensive survey which can serve as a valuable reference and inspire both researchers and practitioners who work on visual recognition problems.
Temporal-wise Attention Spiking Neural Networks for Event Streams Classification
Jul 25, 2021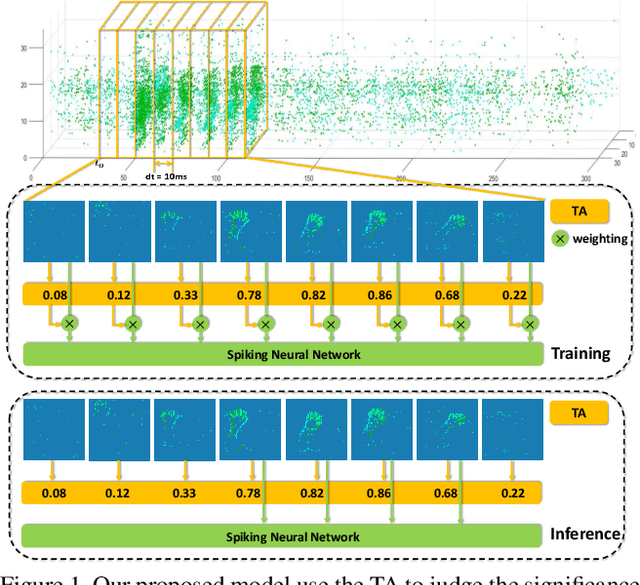

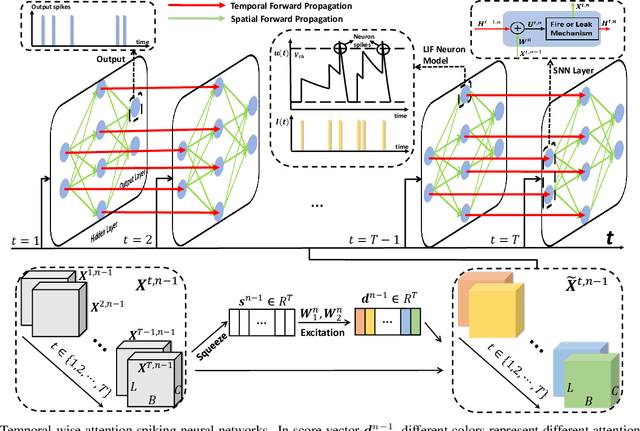

How to effectively and efficiently deal with spatio-temporal event streams, where the events are generally sparse and non-uniform and have the microsecond temporal resolution, is of great value and has various real-life applications. Spiking neural network (SNN), as one of the brain-inspired event-triggered computing models, has the potential to extract effective spatio-temporal features from the event streams. However, when aggregating individual events into frames with a new higher temporal resolution, existing SNN models do not attach importance to that the serial frames have different signal-to-noise ratios since event streams are sparse and non-uniform. This situation interferes with the performance of existing SNNs. In this work, we propose a temporal-wise attention SNN (TA-SNN) model to learn frame-based representation for processing event streams. Concretely, we extend the attention concept to temporal-wise input to judge the significance of frames for the final decision at the training stage, and discard the irrelevant frames at the inference stage. We demonstrate that TA-SNN models improve the accuracy of event streams classification tasks. We also study the impact of multiple-scale temporal resolutions for frame-based representation. Our approach is tested on three different classification tasks: gesture recognition, image classification, and spoken digit recognition. We report the state-of-the-art results on these tasks, and get the essential improvement of accuracy (almost 19\%) for gesture recognition with only 60 ms.
Kronecker CP Decomposition with Fast Multiplication for Compressing RNNs
Aug 21, 2020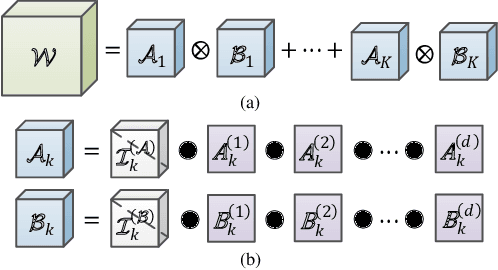
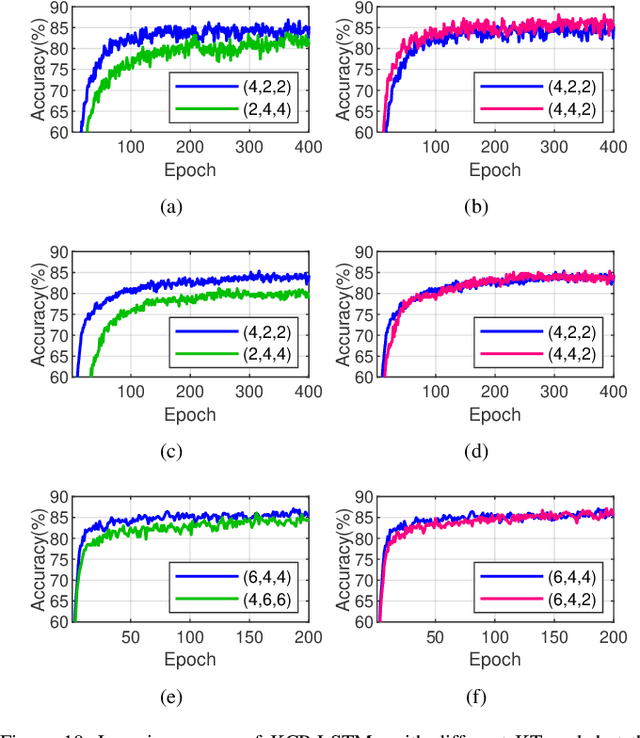
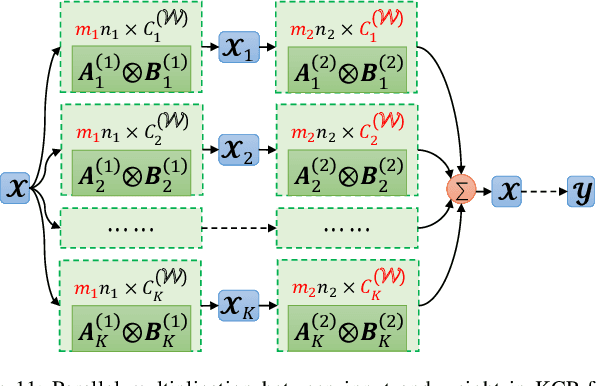
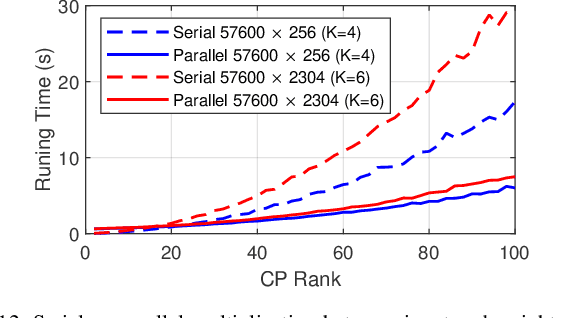
Recurrent neural networks (RNNs) are powerful in the tasks oriented to sequential data, such as natural language processing and video recognition. However, since the modern RNNs, including long-short term memory (LSTM) and gated recurrent unit (GRU) networks, have complex topologies and expensive space/computation complexity, compressing them becomes a hot and promising topic in recent years. Among plenty of compression methods, tensor decomposition, e.g., tensor train (TT), block term (BT), tensor ring (TR) and hierarchical Tucker (HT), appears to be the most amazing approach since a very high compression ratio might be obtained. Nevertheless, none of these tensor decomposition formats can provide both the space and computation efficiency. In this paper, we consider to compress RNNs based on a novel Kronecker CANDECOMP/PARAFAC (KCP) decomposition, which is derived from Kronecker tensor (KT) decomposition, by proposing two fast algorithms of multiplication between the input and the tensor-decomposed weight. According to our experiments based on UCF11, Youtube Celebrities Face and UCF50 datasets, it can be verified that the proposed KCP-RNNs have comparable performance of accuracy with those in other tensor-decomposed formats, and even 278,219x compression ratio could be obtained by the low rank KCP. More importantly, KCP-RNNs are efficient in both space and computation complexity compared with other tensor-decomposed ones under similar ranks. Besides, we find KCP has the best potential for parallel computing to accelerate the calculations in neural networks.
Hybrid Tensor Decomposition in Neural Network Compression
Jun 29, 2020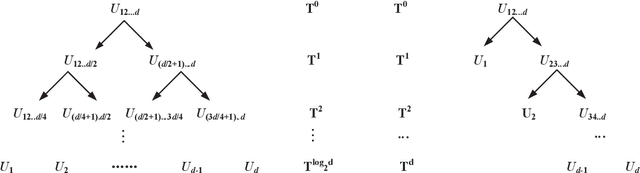
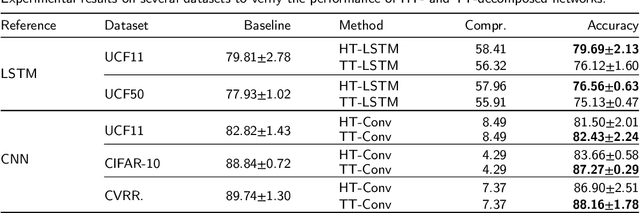
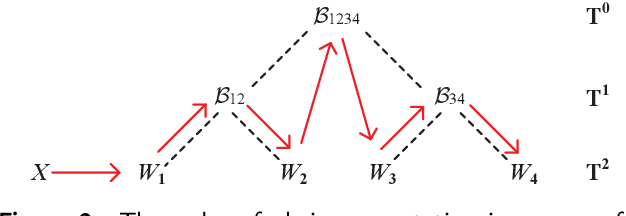
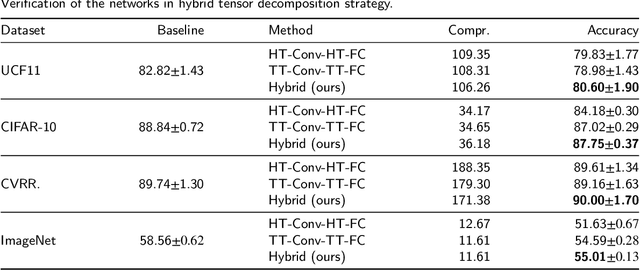
Deep neural networks (DNNs) have enabled impressive breakthroughs in various artificial intelligence (AI) applications recently due to its capability of learning high-level features from big data. However, the current demand of DNNs for computational resources especially the storage consumption is growing due to that the increasing sizes of models are being required for more and more complicated applications. To address this problem, several tensor decomposition methods including tensor-train (TT) and tensor-ring (TR) have been applied to compress DNNs and shown considerable compression effectiveness. In this work, we introduce the hierarchical Tucker (HT), a classical but rarely-used tensor decomposition method, to investigate its capability in neural network compression. We convert the weight matrices and convolutional kernels to both HT and TT formats for comparative study, since the latter is the most widely used decomposition method and the variant of HT. We further theoretically and experimentally discover that the HT format has better performance on compressing weight matrices, while the TT format is more suited for compressing convolutional kernels. Based on this phenomenon we propose a strategy of hybrid tensor decomposition by combining TT and HT together to compress convolutional and fully connected parts separately and attain better accuracy than only using the TT or HT format on convolutional neural networks (CNNs). Our work illuminates the prospects of hybrid tensor decomposition for neural network compression.
Lossless Compression for 3DCNNs Based on Tensor Train Decomposition
Dec 08, 2019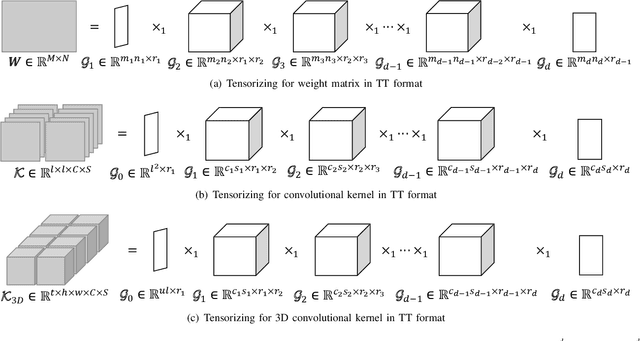
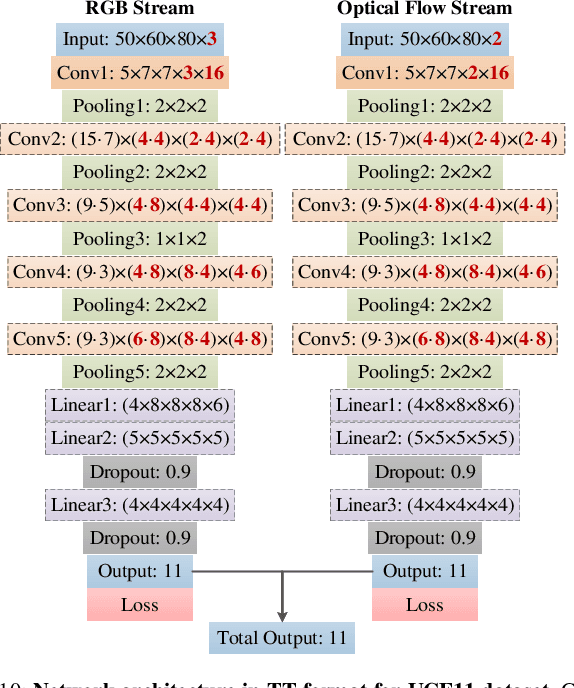
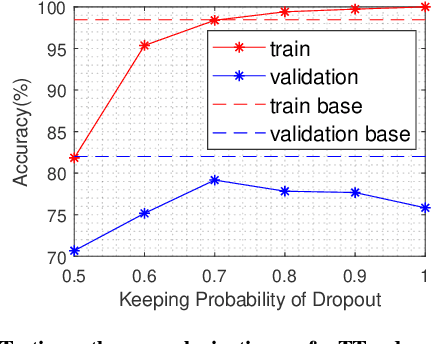
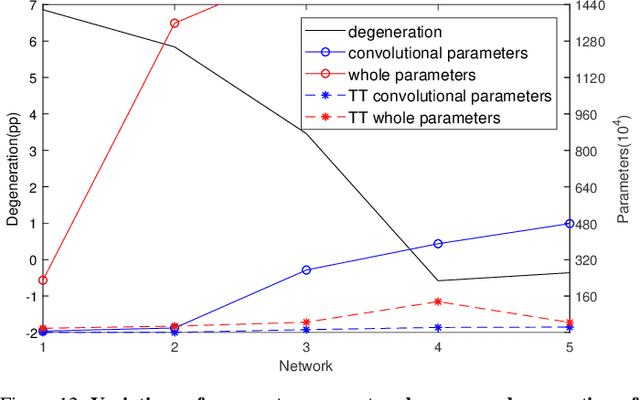
Three dimensional convolutional neural networks (3DCNNs) have been applied in many tasks of video or 3D point cloud recognition. However, due to the higher dimension of convolutional kernels, the space complexity of 3DCNNs is generally larger than that of traditional two dimensional convolutional neural networks (2DCNNs). To miniaturize 3DCNNs for the deployment in confining environments such as embedded devices, neural network compression is a promising approach. In this work, we adopt the tensor train (TT) decomposition, the most compact and simplest \emph{in situ} training compression method, to shrink the 3DCNN models. We give the tensorizing for 3D convolutional kernels in TT format and investigate how to select appropriate ranks for the tensor in TT format. In the light of multiple contrast experiments based on VIVA challenge and UCF11 datasets, we conclude that the TT decomposition can compress redundant 3DCNNs in a ratio up to 121\(\times\) with little accuracy improvement. Besides, we achieve a state-of-the-art result of TT-3DCNN on VIVA challenge dataset (81.83\%).