 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless Compression for 3DCNNs Based on Tensor Train Decomposition
Paper and Code
Dec 08, 2019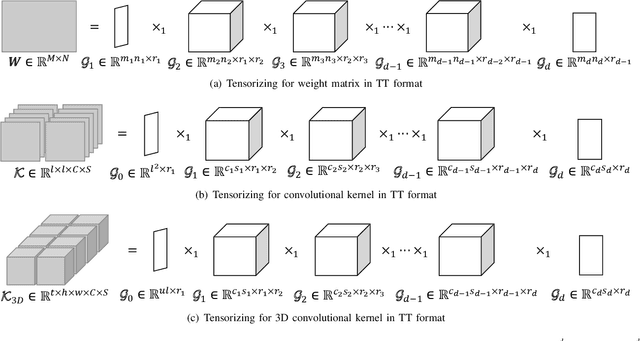
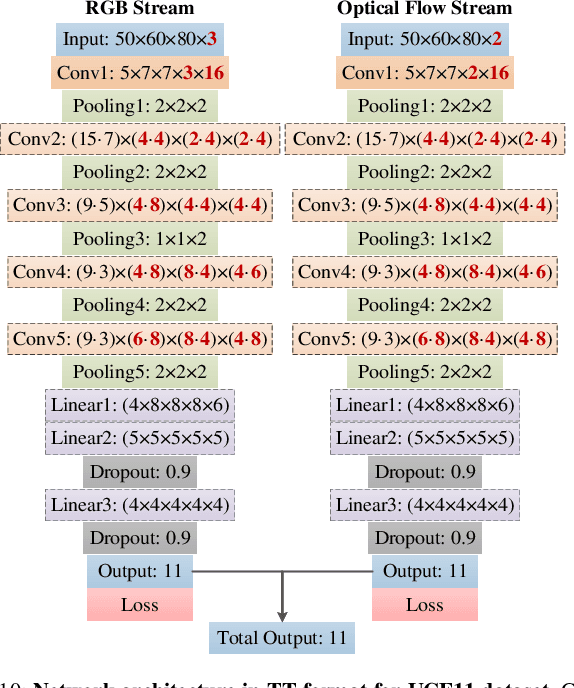
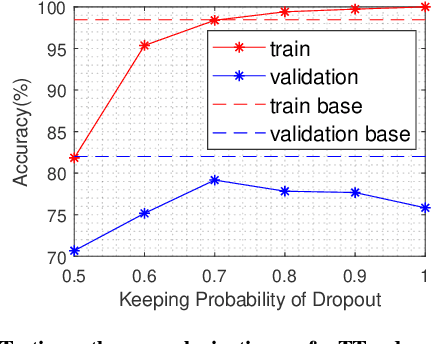
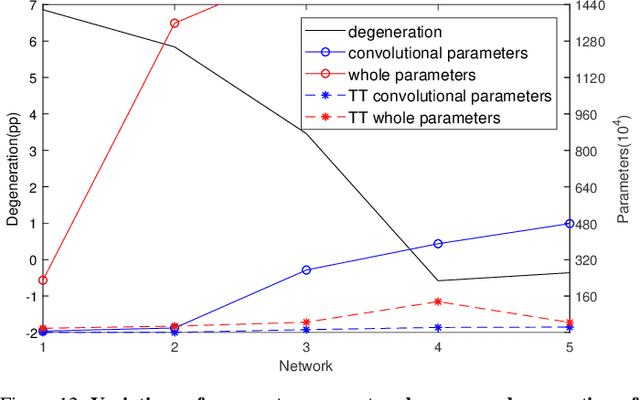
Three dimensional convolutional neural networks (3DCNNs) have been applied in many tasks of video or 3D point cloud recognition. However, due to the higher dimension of convolutional kernels, the space complexity of 3DCNNs is generally larger than that of traditional two dimensional convolutional neural networks (2DCNNs). To miniaturize 3DCNNs for the deployment in confining environments such as embedded devices, neural network compression is a promising approach. In this work, we adopt the tensor train (TT) decomposition, the most compact and simplest \emph{in situ} training compression method, to shrink the 3DCNN models. We give the tensorizing for 3D convolutional kernels in TT format and investigate how to select appropriate ranks for the tensor in TT format. In the light of multiple contrast experiments based on VIVA challenge and UCF11 datasets, we conclude that the TT decomposition can compress redundant 3DCNNs in a ratio up to 121\(\times\) with little accuracy improvement. Besides, we achieve a state-of-the-art result of TT-3DCNN on VIVA challenge dataset (81.83\%).