 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Zero-shot and Few-shot Learning with Instruction-following LLMs for Claim Matching in Automated Fact-checking
Jan 18, 2025


The claim matching (CM) task can benefit an automated fact-checking pipeline by putting together claims that can be resolved with the same fact-check. In this work, we are the first to explore zero-shot and few-shot learning approaches to the task. We consider CM as a binary classification task and experiment with a set of instruction-following large language models (GPT-3.5-turbo, Gemini-1.5-flash, Mistral-7B-Instruct, and Llama-3-8B-Instruct), investigating prompt templates. We introduce a new CM dataset, ClaimMatch, which will be released upon acceptance. We put LLMs to the test in the CM task and find that it can be tackled by leveraging more mature yet similar tasks such as natural language inference or paraphrase detection. We also propose a pipeline for CM, which we evaluate on texts of different lengths.
WikiOmnia: generative QA corpus on the whole Russian Wikipedia
Apr 29, 2022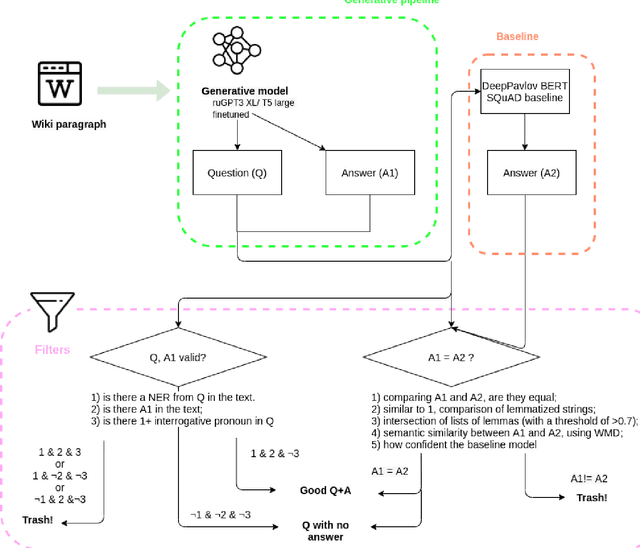
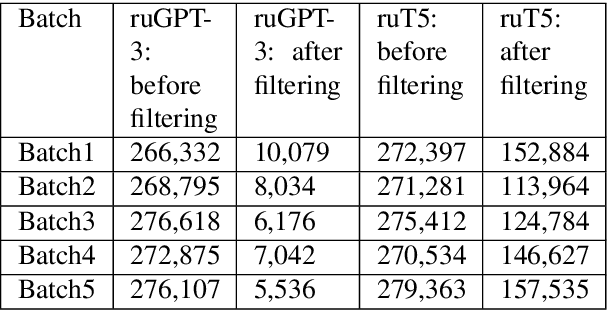
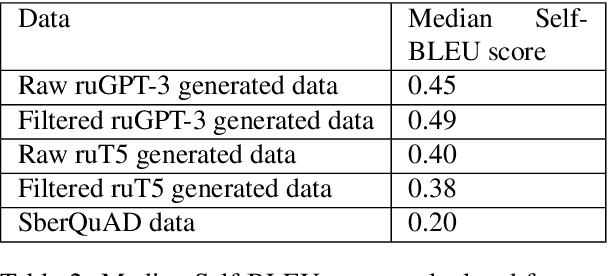
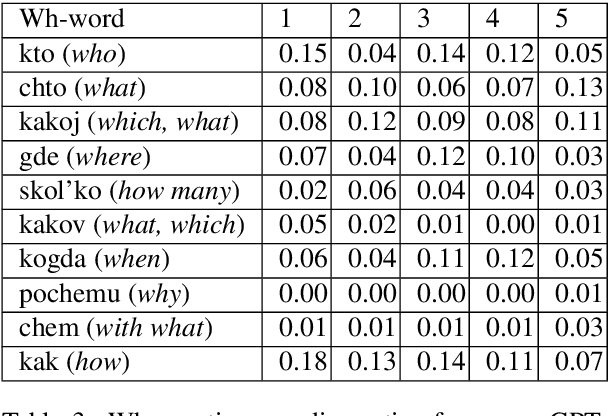
The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. However, compiling factual questions is accompanied by time- and labour-consuming annotation, limiting the training data's potential size. We present the WikiOmnia dataset, a new publicly available set of QA-pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generative pipeline. The dataset includes every available article from Wikipedia for the Russian language. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).