 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBursting Scientific Filter Bubbles: Boosting Innovation via Novel Author Discovery
Sep 10, 2021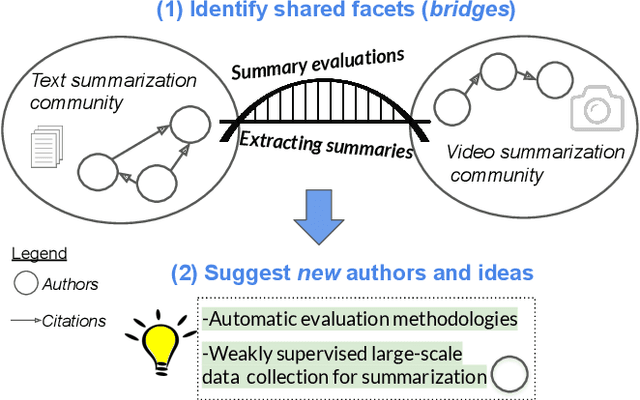
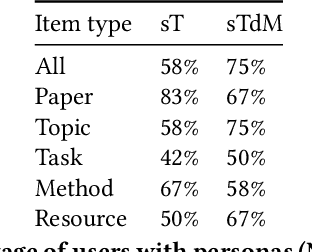
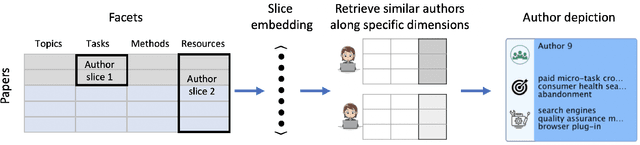
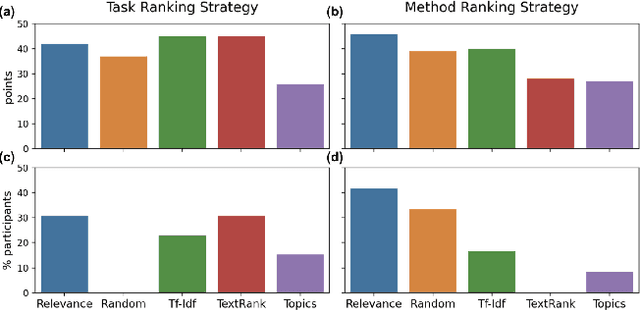
Isolated silos of scientific research and the growing challenge of information overload limit awareness across the literature and hinder innovation. Algorithmic curation and recommendation, which often prioritize relevance, can further reinforce these informational "filter bubbles." In response, we describe Bridger, a system for facilitating discovery of scholars and their work, to explore design tradeoffs between relevant and novel recommendations. We construct a faceted representation of authors with information gleaned from their papers and inferred author personas, and use it to develop an approach that locates commonalities ("bridges") and contrasts between scientists -- retrieving partially similar authors rather than aiming for strict similarity. In studies with computer science researchers, this approach helps users discover authors considered useful for generating novel research directions, outperforming a state-of-art neural model. In addition to recommending new content, we also demonstrate an approach for displaying it in a manner that boosts researchers' ability to understand the work of authors with whom they are unfamiliar. Finally, our analysis reveals that Bridger connects authors who have different citation profiles, publish in different venues, and are more distant in social co-authorship networks, raising the prospect of bridging diverse communities and facilitating discovery.
SciCo: Hierarchical Cross-Document Coreference for Scientific Concepts
Apr 18, 2021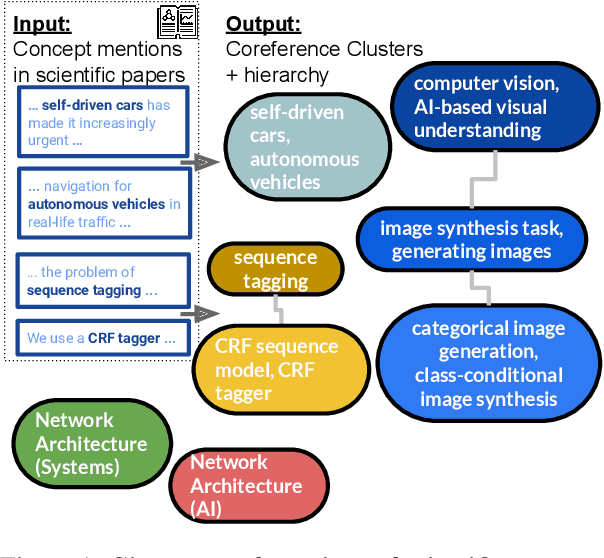

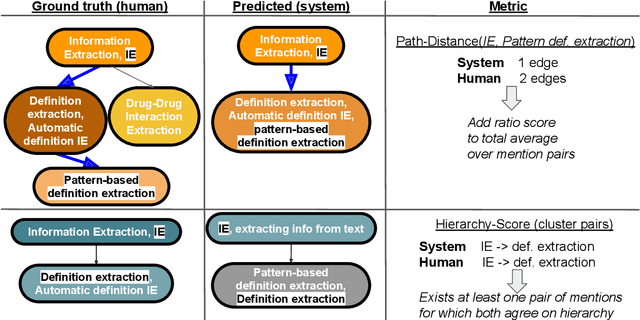
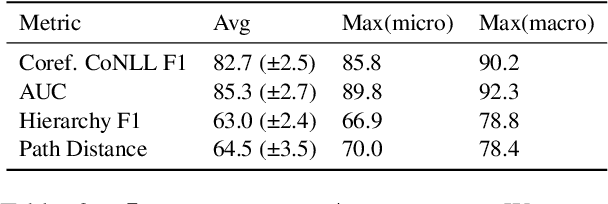
Determining coreference of concept mentions across multiple documents is fundamental for natural language understanding. Work on cross-document coreference resolution (CDCR) typically considers mentions of events in the news, which do not often involve abstract technical concepts that are prevalent in science and technology. These complex concepts take diverse or ambiguous forms and have many hierarchical levels of granularity (e.g., tasks and subtasks), posing challenges for CDCR. We present a new task of hierarchical CDCR for concepts in scientific papers, with the goal of jointly inferring coreference clusters and hierarchy between them. We create SciCo, an expert-annotated dataset for this task, which is 3X larger than the prominent ECB+ resource. We find that tackling both coreference and hierarchy at once outperforms disjoint models, which we hope will spur development of joint models for SciCo.
A Probabilistic Model of Action for Least-Commitment Planning with Information Gather
Feb 27, 2013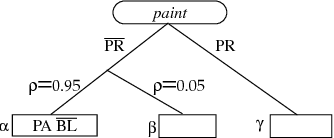

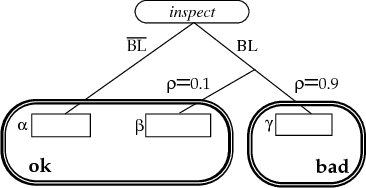
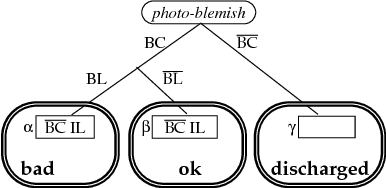
AI planning algorithms have addressed the problem of generating sequences of operators that achieve some input goal, usually assuming that the planning agent has perfect control over and information about the world. Relaxing these assumptions requires an extension to the action representation that allows reasoning both about the changes an action makes and the information it provides. This paper presents an action representation that extends the deterministic STRIPS model, allowing actions to have both causal and informational effects, both of which can be context dependent and noisy. We also demonstrate how a standard least-commitment planning algorithm can be extended to include informational actions and contingent execution.
A Theory of Goal-Oriented MDPs with Dead Ends
Oct 16, 2012Stochastic Shortest Path (SSP) MDPs is a problem class widely studied in AI, especially in probabilistic planning. They describe a wide range of scenarios but make the restrictive assumption that the goal is reachable from any state, i.e., that dead-end states do not exist. Because of this, SSPs are unable to model various scenarios that may have catastrophic events (e.g., an airplane possibly crashing if it flies into a storm). Even though MDP algorithms have been used for solving problems with dead ends, a principled theory of SSP extensions that would allow dead ends, including theoretically sound algorithms for solving such MDPs, has been lacking. In this paper, we propose three new MDP classes that admit dead ends under increasingly weaker assumptions. We present Value Iteration-based as well as the more efficient heuristic search algorithms for optimally solving each class, and explore theoretical relationships between these classes. We also conduct a preliminary empirical study comparing the performance of our algorithms on different MDP classes, especially on scenarios with unavoidable dead ends.
Crowdsourcing Control: Moving Beyond Multiple Choice
Oct 16, 2012To ensure quality results from crowdsourced tasks, requesters often aggregate worker responses and use one of a plethora of strategies to infer the correct answer from the set of noisy responses. However, all current models assume prior knowledge of all possible outcomes of the task. While not an unreasonable assumption for tasks that can be posited as multiple-choice questions (e.g. n-ary classification), we observe that many tasks do not naturally fit this paradigm, but instead demand a free-response formulation where the outcome space is of infinite size (e.g. audio transcription). We model such tasks with a novel probabilistic graphical model, and design and implement LazySusan, a decision-theoretic controller that dynamically requests responses as necessary in order to infer answers to these tasks. We also design an EM algorithm to jointly learn the parameters of our model while inferring the correct answers to multiple tasks at a time. Live experiments on Amazon Mechanical Turk demonstrate the superiority of LazySusan at solving SAT Math questions, eliminating 83.2% of the error and achieving greater net utility compared to the state-ofthe-art strategy, majority-voting. We also show in live experiments that our EM algorithm outperforms majority-voting on a visualization task that we design.