 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Integrated Knowledge Transfer to Large Language Models through Preference Optimization with Biomedical Applications
May 09, 2025The scarcity of high-quality multimodal biomedical data limits the ability to effectively fine-tune pretrained Large Language Models (LLMs) for specialized biomedical tasks. To address this challenge, we introduce MINT (Multimodal Integrated kNowledge Transfer), a framework that aligns unimodal large decoder models with domain-specific decision patterns from multimodal biomedical data through preference optimization. While MINT supports different optimization techniques, we primarily implement it with the Odds Ratio Preference Optimization (ORPO) framework as its backbone. This strategy enables the aligned LLMs to perform predictive tasks using text-only or image-only inputs while retaining knowledge learnt from multimodal data. MINT leverages an upstream multimodal machine learning (MML) model trained on high-quality multimodal data to transfer domain-specific insights to downstream text-only or image-only LLMs. We demonstrate its effectiveness through two key applications: (1) Rare genetic disease prediction from texts, where MINT uses a multimodal encoder model, trained on facial photos and clinical notes, to generate a preference dataset for aligning a lightweight Llama 3.2-3B-Instruct. Despite relying on text input only, the MINT-derived model outperforms models trained with SFT, RAG, or DPO, and even outperforms Llama 3.1-405B-Instruct. (2) Tissue type classification using cell nucleus images, where MINT uses a vision-language foundation model as the preference generator, containing knowledge learnt from both text and histopathological images to align downstream image-only models. The resulting MINT-derived model significantly improves the performance of Llama 3.2-Vision-11B-Instruct on tissue type classification. In summary, MINT provides an effective strategy to align unimodal LLMs with high-quality multimodal expertise through preference optimization.
Integrating Chain-of-Thought and Retrieval Augmented Generation Enhances Rare Disease Diagnosis from Clinical Notes
Mar 15, 2025Background: Several studies show that large language models (LLMs) struggle with phenotype-driven gene prioritization for rare diseases. These studies typically use Human Phenotype Ontology (HPO) terms to prompt foundation models like GPT and LLaMA to predict candidate genes. However, in real-world settings, foundation models are not optimized for domain-specific tasks like clinical diagnosis, yet inputs are unstructured clinical notes rather than standardized terms. How LLMs can be instructed to predict candidate genes or disease diagnosis from unstructured clinical notes remains a major challenge. Methods: We introduce RAG-driven CoT and CoT-driven RAG, two methods that combine Chain-of-Thought (CoT) and Retrieval Augmented Generation (RAG) to analyze clinical notes. A five-question CoT protocol mimics expert reasoning, while RAG retrieves data from sources like HPO and OMIM (Online Mendelian Inheritance in Man). We evaluated these approaches on rare disease datasets, including 5,980 Phenopacket-derived notes, 255 literature-based narratives, and 220 in-house clinical notes from Childrens Hospital of Philadelphia. Results: We found that recent foundations models, including Llama 3.3-70B-Instruct and DeepSeek-R1-Distill-Llama-70B, outperformed earlier versions such as Llama 2 and GPT-3.5. We also showed that RAG-driven CoT and CoT-driven RAG both outperform foundation models in candidate gene prioritization from clinical notes; in particular, both methods with DeepSeek backbone resulted in a top-10 gene accuracy of over 40% on Phenopacket-derived clinical notes. RAG-driven CoT works better for high-quality notes, where early retrieval can anchor the subsequent reasoning steps in domain-specific evidence, while CoT-driven RAG has advantage when processing lengthy and noisy notes.
Multimodal Machine Learning Combining Facial Images and Clinical Texts Improves Diagnosis of Rare Genetic Diseases
Dec 23, 2023Individuals with suspected rare genetic disorders often undergo multiple clinical evaluations, imaging studies, laboratory tests and genetic tests, to find a possible answer over a prolonged period of multiple years. Addressing this diagnostic odyssey thus have substantial clinical, psychosocial, and economic benefits. Many rare genetic diseases have distinctive facial features, which can be used by artificial intelligence algorithms to facilitate clinical diagnosis, in prioritizing candidate diseases to be further examined by lab tests or genetic assays, or in helping the phenotype-driven reinterpretation of genome/exome sequencing data. However, existing methods using frontal facial photo were built on conventional Convolutional Neural Networks (CNNs), rely exclusively on facial images, and cannot capture non-facial phenotypic traits and demographic information essential for guiding accurate diagnoses. Here we introduce GestaltMML, a multimodal machine learning (MML) approach solely based on the Transformer architecture. It integrates the facial images, demographic information (age, sex, ethnicity), and clinical notes of patients to improve prediction accuracy. Furthermore, we also introduce GestaltGPT, a GPT-based methodology with few-short learning capacities that exclusively harnesses textual inputs using a range of large language models (LLMs) including Llama 2, GPT-J and Falcon. We evaluated these methods on a diverse range of datasets, including 449 diseases from the GestaltMatcher Database, several in-house datasets on Beckwith-Wiedemann syndrome, Sotos syndrome, NAA10-related syndrome (neurodevelopmental syndrome) and others. Our results suggest that GestaltMML/GestaltGPT effectively incorporate multiple modalities of data, greatly narrow down candidate genetic diagnosis of rare diseases, and may facilitate the reinterpretation of genome/exome sequencing data.
Not All Large Language Models Succumb to the "Reversal Curse": A Comparative Study of Deductive Logical Reasoning in BERT and GPT Models
Dec 06, 2023The "Reversal Curse" refers to the scenario where auto-regressive decoder large language models (LLMs), such as ChatGPT, trained on "A is B" fail to learn "B is A", demonstrating a basic failure of logical deduction. This raises a red flag in the use of GPT models for certain general tasks such as constructing knowledge graphs, considering their adherence to this symmetric principle. In our study, we examined a bidirectional LLM, BERT, and found that it is immune to the reversal curse. Driven by ongoing efforts to construct biomedical knowledge graphs with LLMs, we also embarked on evaluating more complex but essential deductive reasoning capabilities. This process included first training encoder and decoder language models to master the intersection ($\cap$) and union ($\cup$) operations on two sets and then moving on to assess their capability to infer different combinations of union ($\cup$) and intersection ($\cap$) operations on three newly created sets. The findings showed that while both encoder and decoder language models, trained for tasks involving two sets (union/intersection), were proficient in such scenarios, they encountered difficulties when dealing with operations that included three sets (various combinations of union and intersection). Our research highlights the distinct characteristics of encoder and decoder models in simple and complex logical reasoning. In practice, the choice between BERT and GPT should be guided by the specific requirements and nature of the task at hand, leveraging their respective strengths in bidirectional context comprehension and sequence prediction.
Enhancing Phenotype Recognition in Clinical Notes Using Large Language Models: PhenoBCBERT and PhenoGPT
Aug 11, 2023



We hypothesize that large language models (LLMs) based on the transformer architecture can enable automated detection of clinical phenotype terms, including terms not documented in the HPO. In this study, we developed two types of models: PhenoBCBERT, a BERT-based model, utilizing Bio+Clinical BERT as its pre-trained model, and PhenoGPT, a GPT-based model that can be initialized from diverse GPT models, including open-source versions such as GPT-J, Falcon, and LLaMA, as well as closed-source versions such as GPT-3 and GPT-3.5. We compared our methods with PhenoTagger, a recently developed HPO recognition tool that combines rule-based and deep learning methods. We found that our methods can extract more phenotype concepts, including novel ones not characterized by HPO. We also performed case studies on biomedical literature to illustrate how new phenotype information can be recognized and extracted. We compared current BERT-based versus GPT-based models for phenotype tagging, in multiple aspects including model architecture, memory usage, speed, accuracy, and privacy protection. We also discussed the addition of a negation step and an HPO normalization layer to the transformer models for improved HPO term tagging. In conclusion, PhenoBCBERT and PhenoGPT enable the automated discovery of phenotype terms from clinical notes and biomedical literature, facilitating automated downstream tasks to derive new biological insights on human diseases.
Deep Reinforcement Learning Empowered Rate Selection of XP-HARQ
Aug 04, 2023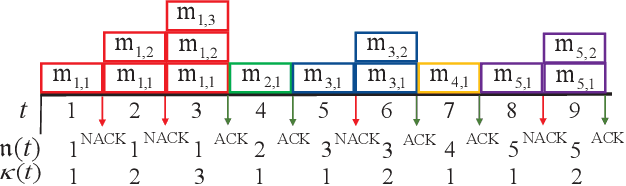

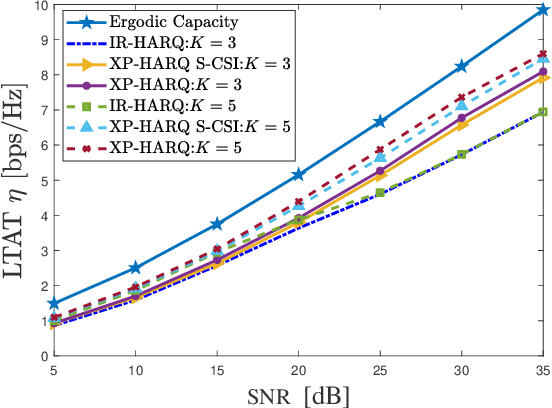
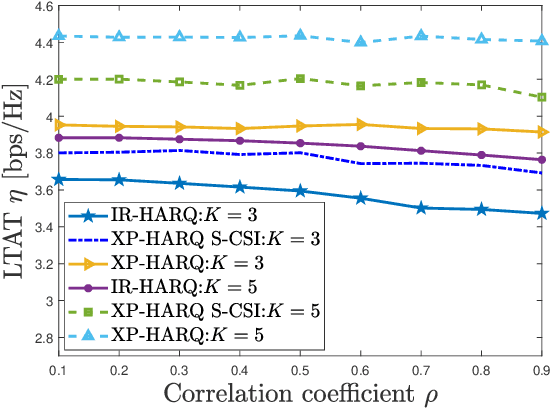
The complex transmission mechanism of cross-packet hybrid automatic repeat request (XP-HARQ) hinders its optimal system design. To overcome this difficulty, this letter attempts to use the deep reinforcement learning (DRL) to solve the rate selection problem of XP-HARQ over correlated fading channels. In particular, the long term average throughput (LTAT) is maximized by properly choosing the incremental information rate for each HARQ round on the basis of the outdated channel state information (CSI) available at the transmitter. The rate selection problem is first converted into a Markov decision process (MDP), which is then solved by capitalizing on the algorithm of deep deterministic policy gradient (DDPG) with prioritized experience replay. The simulation results finally corroborate the superiority of the proposed XP-HARQ scheme over the conventional HARQ with incremental redundancy (HARQ-IR) and the XP-HARQ with only statistical CSI.
On the Prime Number Divisibility by Deep Learning
Apr 03, 2023Certain tasks such as determining whether a given integer can be divided by 2, 3, or other prime numbers may be trivial for human beings, but can be less straightforward for computers in the absence of pre-specified algorithms. In this paper, we tested multiple deep learning architectures and feature engineering approaches, and evaluated the scenario of determining divisibility of large finite integers (up to $2^{32}$) by small prime numbers. It turns out that, regardless of the network frameworks or the complexity of the network structures (CNN, RNN, Transformer, etc.), the ability to predict the prime number divisibility critically depends on the feature space fed into the deep learning models. We also evaluated commercially available Automated Machine Learning (AutoML) pipelines from Amazon, Google and Microsoft, and demonstrated that they failed to address this issue unless appropriately engineered features were provided. We further proposed a closed form solution to the problem using the ordinary linear regression on Fourier series basis vectors, and showed its success. Finally, we evaluated prompt-based learning using ChatGPT and demonstrated its success on small primes and apparent failures on larger primes. We conclude that feature engineering remains an important task to improve the performance, increase the interpretability, and reduce the complexity of machine learning/deep learning models, even in the era of AutoML and large-language models (LLMs).