 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Efficiency and Energy-Efficiency of Variable-Length XP-HARQ
Oct 17, 2023



A variable-length cross-packet hybrid automatic repeat request (VL-XP-HARQ) is proposed to boost the spectral efficiency (SE) and the energy efficiency (EE) of communications. The SE is firstly derived in terms of the outage probabilities, with which the SE is proved to be upper bounded by the ergodic capacity (EC). Moreover, to facilitate the maximization of the SE, the asymptotic outage probability is obtained at high signal-to-noise ratio (SNR), with which the SE is maximized by properly choosing the number of new information bits while guaranteeing outage requirement. By applying Dinkelbach's transform, the fractional objective function is transformed into a subtraction form, which can be decomposed into multiple sub-problems through alternating optimization. By noticing that the asymptotic outage probability is a convex function, each sub-problem can be easily relaxed to a convex problem by adopting successive convex approximation (SCA). Besides, the EE of VL-XP-HARQ is also investigated. An upper bound of the EE is found and proved to be attainable. Furthermore, by aiming at maximizing the EE via power allocation while confining outage within a certain constraint, the methods to the maximization of SE are invoked to solve the similar fractional problem. Finally, numerical results are presented for verification.
Deep Reinforcement Learning Empowered Rate Selection of XP-HARQ
Aug 04, 2023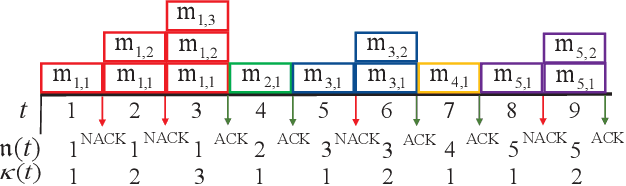

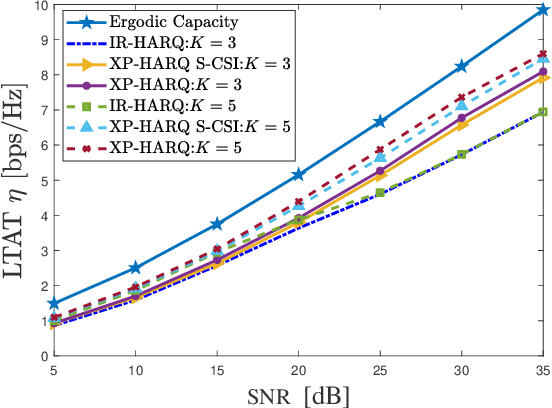
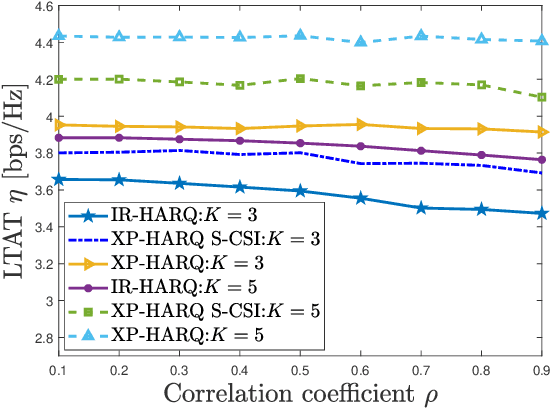
The complex transmission mechanism of cross-packet hybrid automatic repeat request (XP-HARQ) hinders its optimal system design. To overcome this difficulty, this letter attempts to use the deep reinforcement learning (DRL) to solve the rate selection problem of XP-HARQ over correlated fading channels. In particular, the long term average throughput (LTAT) is maximized by properly choosing the incremental information rate for each HARQ round on the basis of the outdated channel state information (CSI) available at the transmitter. The rate selection problem is first converted into a Markov decision process (MDP), which is then solved by capitalizing on the algorithm of deep deterministic policy gradient (DDPG) with prioritized experience replay. The simulation results finally corroborate the superiority of the proposed XP-HARQ scheme over the conventional HARQ with incremental redundancy (HARQ-IR) and the XP-HARQ with only statistical CSI.