 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Hierarchical Patterns for identifying MDD patients: A Multisite Study
Feb 22, 2022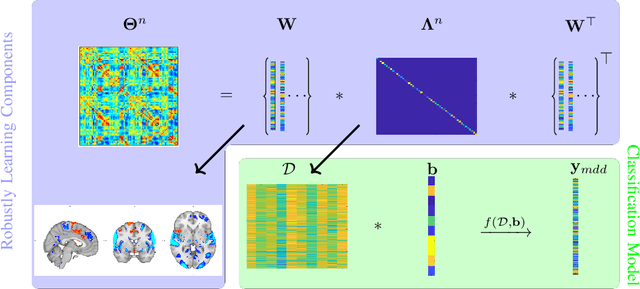

Many supervised machine learning frameworks have been proposed for disease classification using functional magnetic resonance imaging (fMRI) data, producing important biomarkers. More recently, data pooling has flourished, making the result generalizable across a large population. But, this success depends on the population diversity and variability introduced due to the pooling of the data that is not a primary research interest. Here, we look at hierarchical Sparse Connectivity Patterns (hSCPs) as biomarkers for major depressive disorder (MDD). We propose a novel model based on hSCPs to predict MDD patients from functional connectivity matrices extracted from resting-state fMRI data. Our model consists of three coupled terms. The first term decomposes connectivity matrices into hierarchical low-rank sparse components corresponding to synchronous patterns across the human brain. These components are then combined via patient-specific weights capturing heterogeneity in the data. The second term is a classification loss that uses the patient-specific weights to classify MDD patients from healthy ones. Both of these terms are combined with the third term, a robustness loss function to improve the reproducibility of hSCPs. This reduces the variability introduced due to site and population diversity (age and sex) on the predictive accuracy and pattern stability in a large dataset pooled from five different sites. Our results show the impact of diversity on prediction performance. Our model can reduce diversity and improve the predictive and generalizing capability of the components. Finally, our results show that our proposed model can robustly identify clinically relevant patterns characteristic of MDD with high reproducibility.
Multidimensional representations in late-life depression: convergence in neuroimaging, cognition, clinical symptomatology and genetics
Oct 25, 2021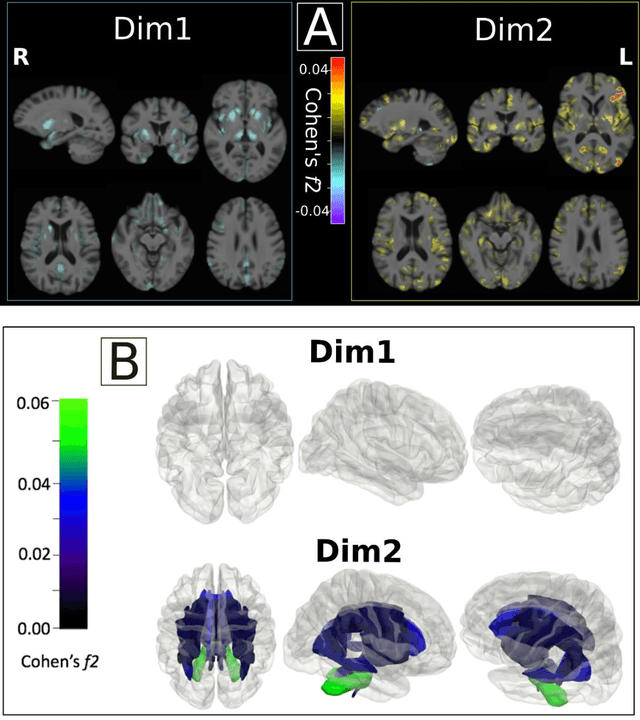
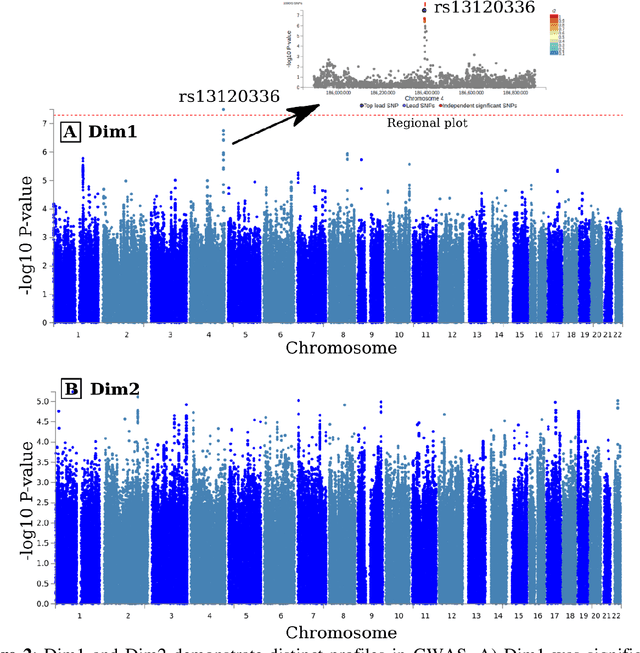
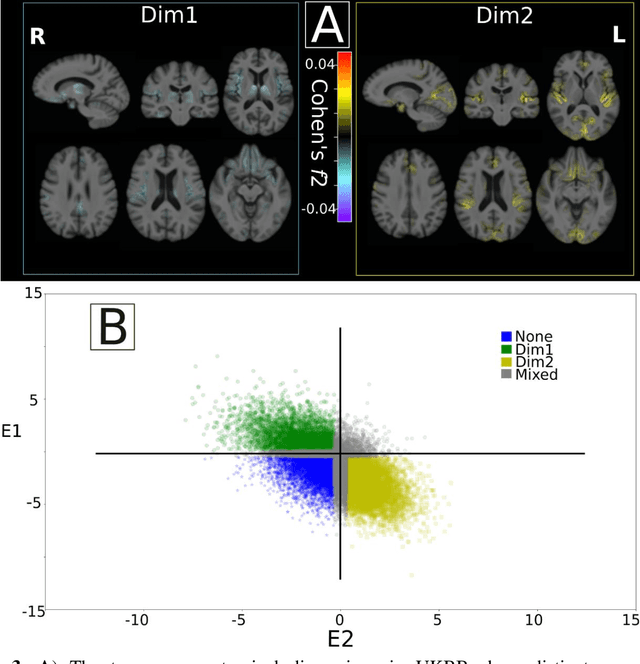
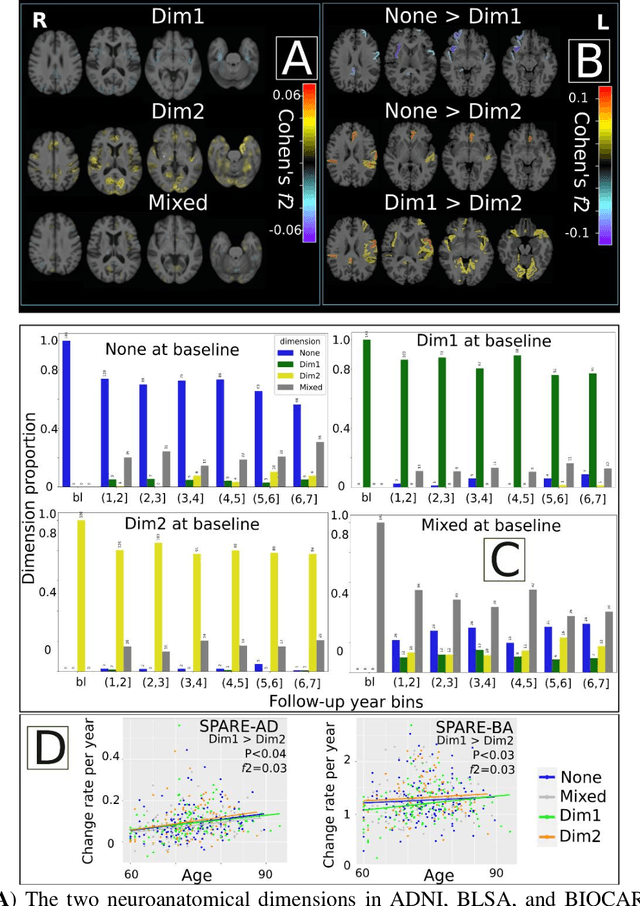
Late-life depression (LLD) is characterized by considerable heterogeneity in clinical manifestation. Unraveling such heterogeneity would aid in elucidating etiological mechanisms and pave the road to precision and individualized medicine. We sought to delineate, cross-sectionally and longitudinally, disease-related heterogeneity in LLD linked to neuroanatomy, cognitive functioning, clinical symptomatology, and genetic profiles. Multimodal data from a multicentre sample (N=996) were analyzed. A semi-supervised clustering method (HYDRA) was applied to regional grey matter (GM) brain volumes to derive dimensional representations. Two dimensions were identified, which accounted for the LLD-related heterogeneity in voxel-wise GM maps, white matter (WM) fractional anisotropy (FA), neurocognitive functioning, clinical phenotype, and genetics. Dimension one (Dim1) demonstrated relatively preserved brain anatomy without WM disruptions relative to healthy controls. In contrast, dimension two (Dim2) showed widespread brain atrophy and WM integrity disruptions, along with cognitive impairment and higher depression severity. Moreover, one de novo independent genetic variant (rs13120336) was significantly associated with Dim 1 but not with Dim 2. Notably, the two dimensions demonstrated significant SNP-based heritability of 18-27% within the general population (N=12,518 in UKBB). Lastly, in a subset of individuals having longitudinal measurements, Dim2 demonstrated a more rapid longitudinal decrease in GM and brain age, and was more likely to progress to Alzheimers disease, compared to Dim1 (N=1,413 participants and 7,225 scans from ADNI, BLSA, and BIOCARD datasets).
Classification of Major Depressive Disorder via Multi-Site Weighted LASSO Model
Jun 03, 2017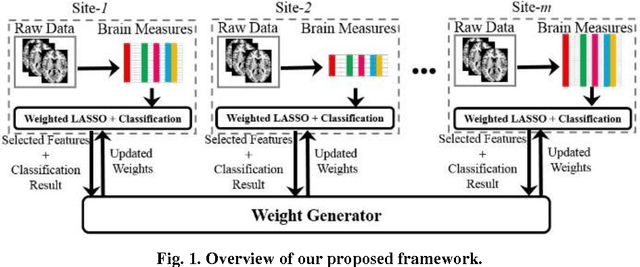
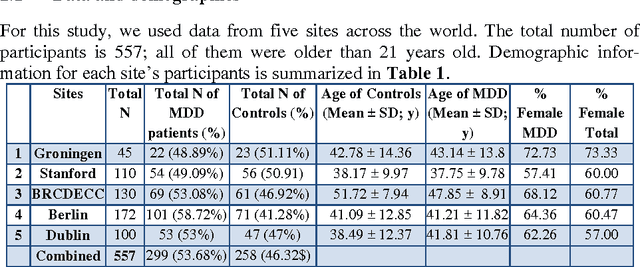

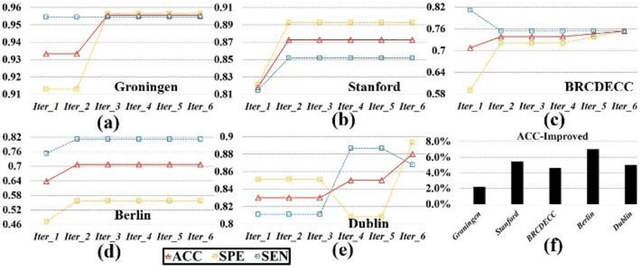
Large-scale collaborative analysis of brain imaging data, in psychiatry and neu-rology, offers a new source of statistical power to discover features that boost ac-curacy in disease classification, differential diagnosis, and outcome prediction. However, due to data privacy regulations or limited accessibility to large datasets across the world, it is challenging to efficiently integrate distributed information. Here we propose a novel classification framework through multi-site weighted LASSO: each site performs an iterative weighted LASSO for feature selection separately. Within each iteration, the classification result and the selected features are collected to update the weighting parameters for each feature. This new weight is used to guide the LASSO process at the next iteration. Only the fea-tures that help to improve the classification accuracy are preserved. In tests on da-ta from five sites (299 patients with major depressive disorder (MDD) and 258 normal controls), our method boosted classification accuracy for MDD by 4.9% on average. This result shows the potential of the proposed new strategy as an ef-fective and practical collaborative platform for machine learning on large scale distributed imaging and biobank data.