 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Defect Geometries of Cast Metal Objects Modeled via 2d Voronoi Tessellations
Feb 05, 2026In industry, defect detection is crucial for quality control. Non-destructive testing (NDT) methods are preferred as they do not influence the functionality of the object while inspecting. Automated data evaluation for automated defect detection is a growing field of research. In particular, machine learning approaches show promising results. To provide training data in sufficient amount and quality, synthetic data can be used. Rule-based approaches enable synthetic data generation in a controllable environment. Therefore, a digital twin of the inspected object including synthetic defects is needed. We present parametric methods to model 3d mesh objects of various defect types that can then be added to the object geometry to obtain synthetic defective objects. The models are motivated by common defects in metal casting but can be transferred to other machining procedures that produce similar defect shapes. Synthetic data resembling the real inspection data can then be created by using a physically based Monte Carlo simulation of the respective testing method. Using our defect models, a variable and arbitrarily large synthetic data set can be generated with the possibility to include rarely occurring defects in sufficient quantity. Pixel-perfect annotation can be created in parallel. As an example, we will use visual surface inspection, but the procedure can be applied in combination with simulations for any other NDT method.
Simulation of microstructures and machine learning
Jan 30, 2025Machine learning offers attractive solutions to challenging image processing tasks. Tedious development and parametrization of algorithmic solutions can be replaced by training a convolutional neural network or a random forest with a high potential to generalize. However, machine learning methods rely on huge amounts of representative image data along with a ground truth, usually obtained by manual annotation. Thus, limited availability of training data is a critical bottleneck. We discuss two use cases: optical quality control in industrial production and segmenting crack structures in 3D images of concrete. For optical quality control, all defect types have to be trained but are typically not evenly represented in the training data. Additionally, manual annotation is costly and often inconsistent. It is nearly impossible in the second case: segmentation of crack systems in 3D images of concrete. Synthetic images, generated based on realizations of stochastic geometry models, offer an elegant way out. A wide variety of structure types can be generated. The within structure variation is naturally captured by the stochastic nature of the models and the ground truth is for free. Many new questions arise. In particular, which characteristics of the real image data have to be met to which degree of fidelity.
* Preprint of: K. Schladitz, C. Redenbach, T. Barisin, C. Jung, N. Jeziorski, L. Bosnar, J. Fulir, P. Gospodneti\'c: Simulation of Microstructures and Machine Learning, published in Continuum Models and Discrete Systems by F. Willot, J. Dirrenberger, S. Forest, D. Jeulin, A.V. Cherkaev (eds), 2024, Springer Cham. The final version is https://doi.org/10.1007/978-3-031-58665-1
Cracks in concrete
Jan 30, 2025Finding and properly segmenting cracks in images of concrete is a challenging task. Cracks are thin and rough and being air filled do yield a very weak contrast in 3D images obtained by computed tomography. Enhancing and segmenting dark lower-dimensional structures is already demanding. The heterogeneous concrete matrix and the size of the images further increase the complexity. ML methods have proven to solve difficult segmentation problems when trained on enough and well annotated data. However, so far, there is not much 3D image data of cracks available at all, let alone annotated. Interactive annotation is error-prone as humans can easily tell cats from dogs or roads without from roads with cars but have a hard time deciding whether a thin and dark structure seen in a 2D slice continues in the next one. Training networks by synthetic, simulated images is an elegant way out, bears however its own challenges. In this contribution, we describe how to generate semi-synthetic image data to train CNN like the well known 3D U-Net or random forests for segmenting cracks in 3D images of concrete. The thickness of real cracks varies widely, both, within one crack as well as from crack to crack in the same sample. The segmentation method should therefore be invariant with respect to scale changes. We introduce the so-called RieszNet, designed for exactly this purpose. Finally, we discuss how to generalize the ML crack segmentation methods to other concrete types.
* This is a preprint of the chapter: T. Barisin, C. Jung, A. Nowacka, C. Redenbach, K. Schladitz: Cracks in concrete, published in Statistical Machine Learning for Engineering with Applications (LNCS), edited by J. Franke, A. Sch\"obel, reproduced with permission of Springer Nature Switzerland AG 2024. The final authenticated version is available online at: https://doi.org/10.1007/978-3-031-66253-9
SYNOSIS: Image synthesis pipeline for machine vision in metal surface inspection
Oct 18, 2024

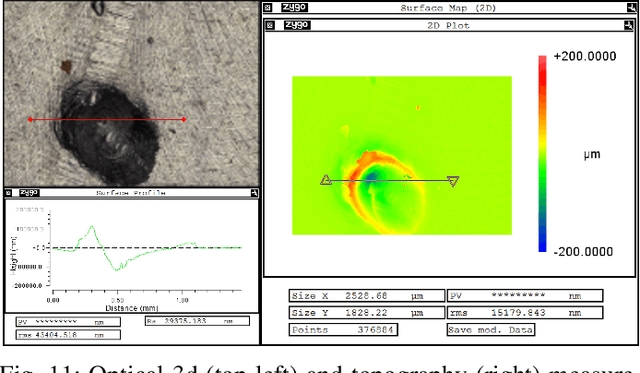
The use of machine learning (ML) methods for development of robust and flexible visual inspection system has shown promising. However their performance is highly dependent on the amount and diversity of training data. This is often restricted not only due to costs but also due to a wide variety of defects and product surfaces which occur with varying frequency. As such, one can not guarantee that the acquired dataset contains enough defect and product surface occurrences which are needed to develop a robust model. Using parametric synthetic dataset generation, it is possible to avoid these issues. In this work, we introduce a complete pipeline which describes in detail how to approach image synthesis for surface inspection - from first acquisition, to texture and defect modeling, data generation, comparison to real data and finally use of the synthetic data to train a defect segmentation model. The pipeline is in detail evaluated for milled and sandblasted aluminum surfaces. In addition to providing an in-depth view into each step, discussion of chosen methods, and presentation of ML results, we provide a comprehensive dual dataset containing both real and synthetic images.
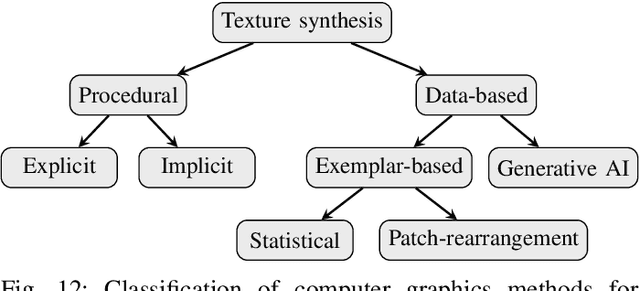
Stochastic Geometry Models for Texture Synthesis of Machined Metallic Surfaces: Sandblasting and Milling
Mar 20, 2024Training defect detection algorithms for visual surface inspection systems requires a large and representative set of training data. Often there is not enough real data available which additionally cannot cover the variety of possible defects. Synthetic data generated by a synthetic visual surface inspection environment can overcome this problem. Therefore, a digital twin of the object is needed, whose micro-scale surface topography is modeled by texture synthesis models. We develop stochastic texture models for sandblasted and milled surfaces based on topography measurements of such surfaces. As the surface patterns differ significantly, we use separate modeling approaches for the two cases. Sandblasted surfaces are modeled by a combination of data-based texture synthesis methods that rely entirely on the measurements. In contrast, the model for milled surfaces is procedural and includes all process-related parameters known from the machine settings.
Efficient stripe artefact removal by a variational method: application to light-sheet microscopy, FIB-SEM and remote sensing images
Jan 25, 2024Light-sheet fluorescence microscopy (LSFM) is used to capture volume images of biological specimens. It offers high contrast deep inside densely fluorescence labelled samples, fast acquisition speed and minimal harmful effects on the sample. However, the resulting images often show strong stripe artifacts originating from light-matter interactions. We propose a robust variational method suitable for removing stripes which outperforms existing methods and offers flexibility through two adjustable parameters. This tool is widely applicable to improve visual quality as well as facilitate downstream processing and analysis of images acquired on systems that do not provide hardware-based destriping methods. An evaluation of methods is performed on LSFM, FIB-SEM and remote sensing data, supplemented by synthetic LSFM images. The latter is obtained by simulating the imaging process on virtual samples.
MorphFlow: Estimating Motion in In Situ Tests of Concrete
Oct 17, 2023

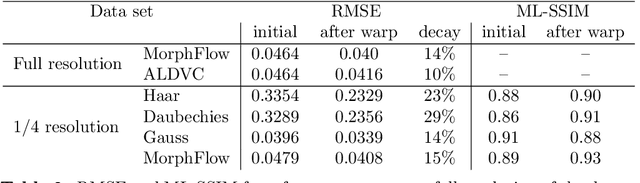
We present a novel algorithm explicitly tailored to estimate motion from time series of 3D images of concrete. Such volumetric images are usually acquired by Computed Tomography and can contain for example in situ tests, or more complex procedures like self-healing. Our algorithm is specifically designed to tackle the challenge of large scale in situ investigations of concrete. That means it cannot only cope with big images, but also with discontinuous displacement fields that often occur in in situ tests of concrete. We show the superior performance of our algorithm, especially regarding plausibility and time efficient processing. Core of the algorithm is a novel multiscale representation based on morphological wavelets. We use two examples for validation: A classical in situ test on refractory concrete and and a three point bending test on normal concrete. We show that for both applications structural changes like crack initiation can be already found at low scales -- a central achievement of our algorithm.
Hybrid quantum transfer learning for crack image classification on NISQ hardware
Jul 31, 2023Quantum computers possess the potential to process data using a remarkably reduced number of qubits compared to conventional bits, as per theoretical foundations. However, recent experiments have indicated that the practical feasibility of retrieving an image from its quantum encoded version is currently limited to very small image sizes. Despite this constraint, variational quantum machine learning algorithms can still be employed in the current noisy intermediate scale quantum (NISQ) era. An example is a hybrid quantum machine learning approach for edge detection. In our study, we present an application of quantum transfer learning for detecting cracks in gray value images. We compare the performance and training time of PennyLane's standard qubits with IBM's qasm\_simulator and real backends, offering insights into their execution efficiency.
Riesz feature representation: scale equivariant scattering network for classification tasks
Jul 17, 2023
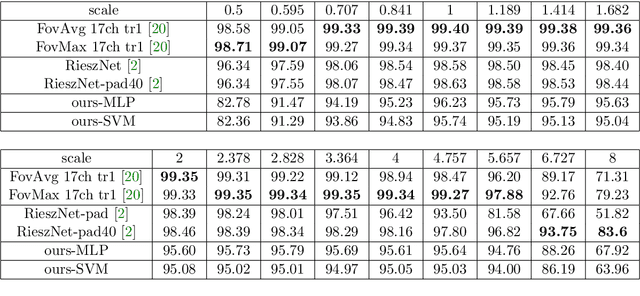

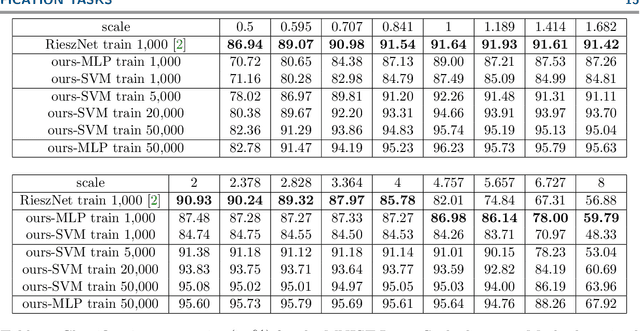
Scattering networks yield powerful and robust hierarchical image descriptors which do not require lengthy training and which work well with very few training data. However, they rely on sampling the scale dimension. Hence, they become sensitive to scale variations and are unable to generalize to unseen scales. In this work, we define an alternative feature representation based on the Riesz transform. We detail and analyze the mathematical foundations behind this representation. In particular, it inherits scale equivariance from the Riesz transform and completely avoids sampling of the scale dimension. Additionally, the number of features in the representation is reduced by a factor four compared to scattering networks. Nevertheless, our representation performs comparably well for texture classification with an interesting addition: scale equivariance. Our method yields superior performance when dealing with scales outside of those covered by the training dataset. The usefulness of the equivariance property is demonstrated on the digit classification task, where accuracy remains stable even for scales four times larger than the one chosen for training. As a second example, we consider classification of textures.
Riesz networks: scale invariant neural networks in a single forward pass
May 08, 2023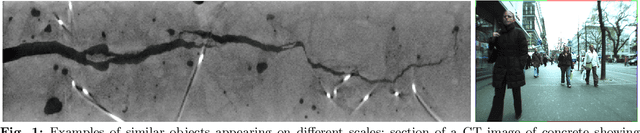
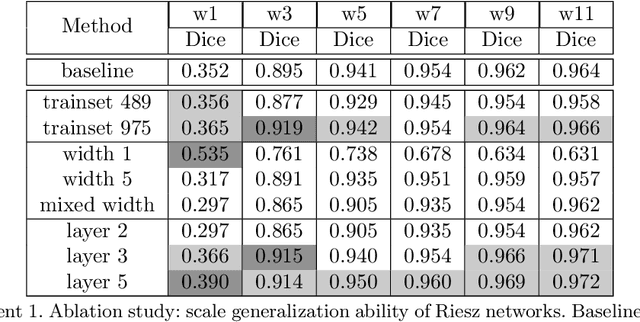

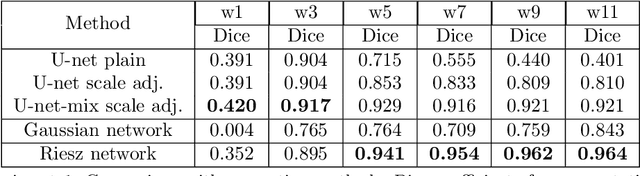
Scale invariance of an algorithm refers to its ability to treat objects equally independently of their size. For neural networks, scale invariance is typically achieved by data augmentation. However, when presented with a scale far outside the range covered by the training set, neural networks may fail to generalize. Here, we introduce the Riesz network, a novel scale invariant neural network. Instead of standard 2d or 3d convolutions for combining spatial information, the Riesz network is based on the Riesz transform which is a scale equivariant operation. As a consequence, this network naturally generalizes to unseen or even arbitrary scales in a single forward pass. As an application example, we consider detecting and segmenting cracks in tomographic images of concrete. In this context, 'scale' refers to the crack thickness which may vary strongly even within the same sample. To prove its scale invariance, the Riesz network is trained on one fixed crack width. We then validate its performance in segmenting simulated and real tomographic images featuring a wide range of crack widths. An additional experiment is carried out on the MNIST Large Scale data set.