 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Defect Geometries of Cast Metal Objects Modeled via 2d Voronoi Tessellations
Feb 05, 2026In industry, defect detection is crucial for quality control. Non-destructive testing (NDT) methods are preferred as they do not influence the functionality of the object while inspecting. Automated data evaluation for automated defect detection is a growing field of research. In particular, machine learning approaches show promising results. To provide training data in sufficient amount and quality, synthetic data can be used. Rule-based approaches enable synthetic data generation in a controllable environment. Therefore, a digital twin of the inspected object including synthetic defects is needed. We present parametric methods to model 3d mesh objects of various defect types that can then be added to the object geometry to obtain synthetic defective objects. The models are motivated by common defects in metal casting but can be transferred to other machining procedures that produce similar defect shapes. Synthetic data resembling the real inspection data can then be created by using a physically based Monte Carlo simulation of the respective testing method. Using our defect models, a variable and arbitrarily large synthetic data set can be generated with the possibility to include rarely occurring defects in sufficient quantity. Pixel-perfect annotation can be created in parallel. As an example, we will use visual surface inspection, but the procedure can be applied in combination with simulations for any other NDT method.
Simulation of microstructures and machine learning
Jan 30, 2025Machine learning offers attractive solutions to challenging image processing tasks. Tedious development and parametrization of algorithmic solutions can be replaced by training a convolutional neural network or a random forest with a high potential to generalize. However, machine learning methods rely on huge amounts of representative image data along with a ground truth, usually obtained by manual annotation. Thus, limited availability of training data is a critical bottleneck. We discuss two use cases: optical quality control in industrial production and segmenting crack structures in 3D images of concrete. For optical quality control, all defect types have to be trained but are typically not evenly represented in the training data. Additionally, manual annotation is costly and often inconsistent. It is nearly impossible in the second case: segmentation of crack systems in 3D images of concrete. Synthetic images, generated based on realizations of stochastic geometry models, offer an elegant way out. A wide variety of structure types can be generated. The within structure variation is naturally captured by the stochastic nature of the models and the ground truth is for free. Many new questions arise. In particular, which characteristics of the real image data have to be met to which degree of fidelity.
* Preprint of: K. Schladitz, C. Redenbach, T. Barisin, C. Jung, N. Jeziorski, L. Bosnar, J. Fulir, P. Gospodneti\'c: Simulation of Microstructures and Machine Learning, published in Continuum Models and Discrete Systems by F. Willot, J. Dirrenberger, S. Forest, D. Jeulin, A.V. Cherkaev (eds), 2024, Springer Cham. The final version is https://doi.org/10.1007/978-3-031-58665-1
Sequential PatchCore: Anomaly Detection for Surface Inspection using Synthetic Impurities
Jan 16, 2025



The appearance of surface impurities (e.g., water stains, fingerprints, stickers) is an often-mentioned issue that causes degradation of automated visual inspection systems. At the same time, synthetic data generation techniques for visual surface inspection have focused primarily on generating perfect examples and defects, disregarding impurities. This study highlights the importance of considering impurities when generating synthetic data. We introduce a procedural method to include photorealistic water stains in synthetic data. The synthetic datasets are generated to correspond to real datasets and are further used to train an anomaly detection model and investigate the influence of water stains. The high-resolution images used for surface inspection lead to memory bottlenecks during anomaly detection training. To address this, we introduce Sequential PatchCore - a method to build coresets sequentially and make training on large images using consumer-grade hardware tractable. This allows us to perform transfer learning using coresets pre-trained on different dataset versions. Our results show the benefits of using synthetic data for pre-training an explicit coreset anomaly model and the extended performance benefits of finetuning the coreset using real data. We observed how the impurities and labelling ambiguity lower the model performance and have additionally reported the defect-wise recall to provide an industrially relevant perspective on model performance.
SYNOSIS: Image synthesis pipeline for machine vision in metal surface inspection
Oct 18, 2024

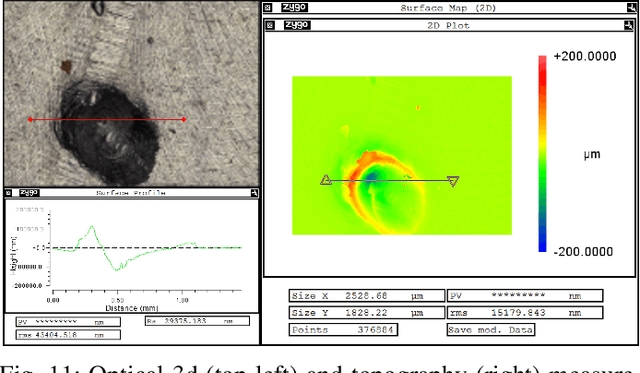
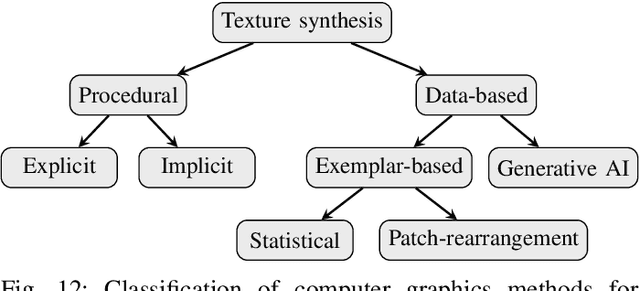
The use of machine learning (ML) methods for development of robust and flexible visual inspection system has shown promising. However their performance is highly dependent on the amount and diversity of training data. This is often restricted not only due to costs but also due to a wide variety of defects and product surfaces which occur with varying frequency. As such, one can not guarantee that the acquired dataset contains enough defect and product surface occurrences which are needed to develop a robust model. Using parametric synthetic dataset generation, it is possible to avoid these issues. In this work, we introduce a complete pipeline which describes in detail how to approach image synthesis for surface inspection - from first acquisition, to texture and defect modeling, data generation, comparison to real data and finally use of the synthetic data to train a defect segmentation model. The pipeline is in detail evaluated for milled and sandblasted aluminum surfaces. In addition to providing an in-depth view into each step, discussion of chosen methods, and presentation of ML results, we provide a comprehensive dual dataset containing both real and synthetic images.