 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI for Point Cloud Data using Perturbations based on Meaningful Segmentation
Jul 29, 2025We propose a novel segmentation-based explainable artificial intelligence (XAI) method for neural networks working on point cloud classification. As one building block of this method, we propose a novel point-shifting mechanism to introduce perturbations in point cloud data. Recently, AI has seen an exponential growth. Hence, it is important to understand the decision-making process of AI algorithms when they are applied in critical areas. Our work focuses on explaining AI algorithms that classify point cloud data. An important aspect of the methods used for explaining AI algorithms is their ability to produce explanations that are easy for humans to understand. This allows them to analyze the AI algorithms better and make appropriate decisions based on that analysis. Therefore, in this work, we intend to generate meaningful explanations that can be easily interpreted by humans. The point cloud data we consider represents 3D objects such as cars, guitars, and laptops. We make use of point cloud segmentation models to generate explanations for the working of classification models. The segments are used to introduce perturbations into the input point cloud data and generate saliency maps. The perturbations are introduced using the novel point-shifting mechanism proposed in this work which ensures that the shifted points no longer influence the output of the classification algorithm. In contrast to previous methods, the segments used by our method are meaningful, i.e. humans can easily interpret the meaning of the segments. Thus, the benefit of our method over other methods is its ability to produce more meaningful saliency maps. We compare our method with the use of classical clustering algorithms to generate explanations. We also analyze the saliency maps generated for example inputs using our method to demonstrate the usefulness of the method in generating meaningful explanations.
Sequential PatchCore: Anomaly Detection for Surface Inspection using Synthetic Impurities
Jan 16, 2025



The appearance of surface impurities (e.g., water stains, fingerprints, stickers) is an often-mentioned issue that causes degradation of automated visual inspection systems. At the same time, synthetic data generation techniques for visual surface inspection have focused primarily on generating perfect examples and defects, disregarding impurities. This study highlights the importance of considering impurities when generating synthetic data. We introduce a procedural method to include photorealistic water stains in synthetic data. The synthetic datasets are generated to correspond to real datasets and are further used to train an anomaly detection model and investigate the influence of water stains. The high-resolution images used for surface inspection lead to memory bottlenecks during anomaly detection training. To address this, we introduce Sequential PatchCore - a method to build coresets sequentially and make training on large images using consumer-grade hardware tractable. This allows us to perform transfer learning using coresets pre-trained on different dataset versions. Our results show the benefits of using synthetic data for pre-training an explicit coreset anomaly model and the extended performance benefits of finetuning the coreset using real data. We observed how the impurities and labelling ambiguity lower the model performance and have additionally reported the defect-wise recall to provide an industrially relevant perspective on model performance.
A Generic Software Framework for Distributed Topological Analysis Pipelines
Oct 12, 2023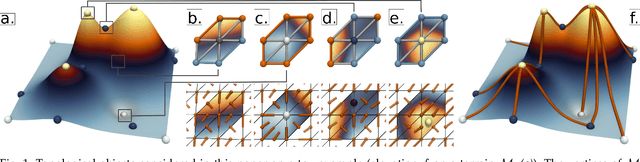
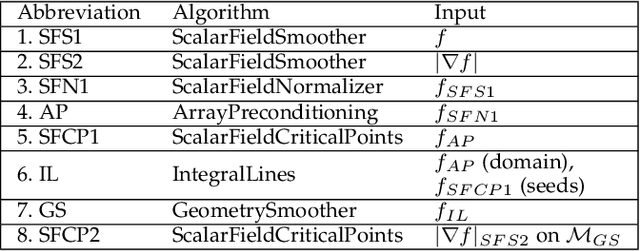
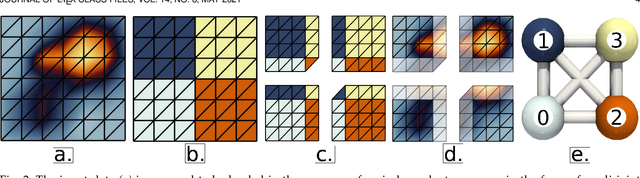
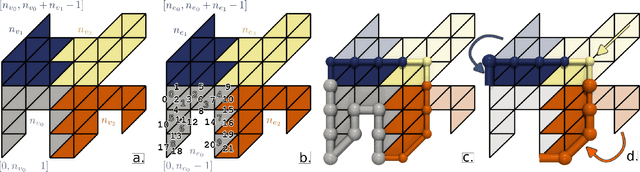
This system paper presents a software framework for the support of topological analysis pipelines in a distributed-memory model. While several recent papers introduced topology-based approaches for distributed-memory environments, these were reporting experiments obtained with tailored, mono-algorithm implementations. In contrast, we describe in this paper a general-purpose, generic framework for topological analysis pipelines, i.e. a sequence of topological algorithms interacting together, possibly on distinct numbers of processes. Specifically, we instantiated our framework with the MPI model, within the Topology ToolKit (TTK). While developing this framework, we faced several algorithmic and software engineering challenges, which we document in this paper. We provide a taxonomy for the distributed-memory topological algorithms supported by TTK, depending on their communication needs and provide examples of hybrid MPI+thread parallelizations. Detailed performance analyses show that parallel efficiencies range from $20\%$ to $80\%$ (depending on the algorithms), and that the MPI-specific preconditioning introduced by our framework induces a negligible computation time overhead. We illustrate the new distributed-memory capabilities of TTK with an example of advanced analysis pipeline, combining multiple algorithms, run on the largest publicly available dataset we have found (120 billion vertices) on a standard cluster with 64 nodes (for a total of 1,536 cores). Finally, we provide a roadmap for the completion of TTK's MPI extension, along with generic recommendations for each algorithm communication category.
PREVIS -- A Combined Machine Learning and Visual Interpolation Approach for Interactive Reverse Engineering in Assembly Quality Control
Jan 25, 2022
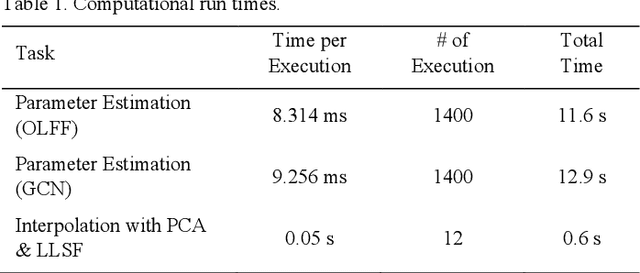


We present PREVIS, a visual analytics tool, enhancing machine learning performance analysis in engineering applications. The presented toolchain allows for a direct comparison of regression models. In addition, we provide a methodology to visualize the impact of regression errors on the underlying field of interest in the original domain, the part geometry, via exploiting standard interpolation methods. Further, we allow a real-time preview of user-driven parameter changes in the displacement field via visual interpolation. This allows for fast and accountable online change management. We demonstrate the effectiveness with an ex-ante optimization of an automotive engine hood.