 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiving Deep into the Motion Representation of Video-Text Models
Jun 07, 2024Videos are more informative than images because they capture the dynamics of the scene. By representing motion in videos, we can capture dynamic activities. In this work, we introduce GPT-4 generated motion descriptions that capture fine-grained motion descriptions of activities and apply them to three action datasets. We evaluated several video-text models on the task of retrieval of motion descriptions. We found that they fall far behind human expert performance on two action datasets, raising the question of whether video-text models understand motion in videos. To address it, we introduce a method of improving motion understanding in video-text models by utilizing motion descriptions. This method proves to be effective on two action datasets for the motion description retrieval task. The results draw attention to the need for quality captions involving fine-grained motion information in existing datasets and demonstrate the effectiveness of the proposed pipeline in understanding fine-grained motion during video-text retrieval.
Forecasting Action through Contact Representations from First Person Video
Feb 01, 2021



Human actions involving hand manipulations are structured according to the making and breaking of hand-object contact, and human visual understanding of action is reliant on anticipation of contact as is demonstrated by pioneering work in cognitive science. Taking inspiration from this, we introduce representations and models centered on contact, which we then use in action prediction and anticipation. We annotate a subset of the EPIC Kitchens dataset to include time-to-contact between hands and objects, as well as segmentations of hands and objects. Using these annotations we train the Anticipation Module, a module producing Contact Anticipation Maps and Next Active Object Segmentations - novel low-level representations providing temporal and spatial characteristics of anticipated near future action. On top of the Anticipation Module we apply Egocentric Object Manipulation Graphs (Ego-OMG), a framework for action anticipation and prediction. Ego-OMG models longer term temporal semantic relations through the use of a graph modeling transitions between contact delineated action states. Use of the Anticipation Module within Ego-OMG produces state-of-the-art results, achieving 1st and 2nd place on the unseen and seen test sets, respectively, of the EPIC Kitchens Action Anticipation Challenge, and achieving state-of-the-art results on the tasks of action anticipation and action prediction over EPIC Kitchens. We perform ablation studies over characteristics of the Anticipation Module to evaluate their utility.
Egocentric Object Manipulation Graphs
Jun 05, 2020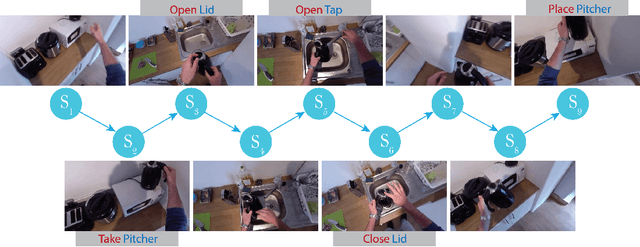
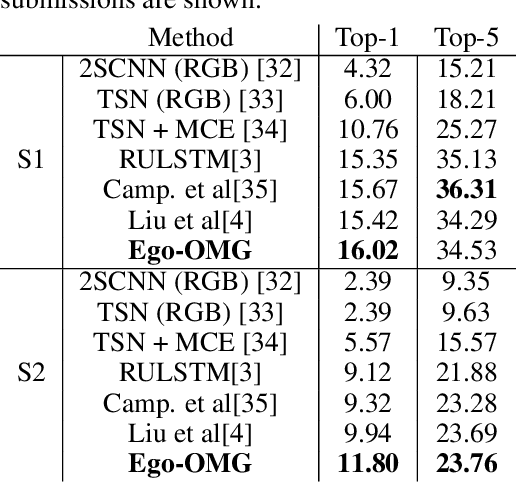


We introduce Egocentric Object Manipulation Graphs (Ego-OMG) - a novel representation for activity modeling and anticipation of near future actions integrating three components: 1) semantic temporal structure of activities, 2) short-term dynamics, and 3) representations for appearance. Semantic temporal structure is modeled through a graph, embedded through a Graph Convolutional Network, whose states model characteristics of and relations between hands and objects. These state representations derive from all three levels of abstraction, and span segments delimited by the making and breaking of hand-object contact. Short-term dynamics are modeled in two ways: A) through 3D convolutions, and B) through anticipating the spatiotemporal end points of hand trajectories, where hands come into contact with objects. Appearance is modeled through deep spatiotemporal features produced through existing methods. We note that in Ego-OMG it is simple to swap these appearance features, and thus Ego-OMG is complementary to most existing action anticipation methods. We evaluate Ego-OMG on the EPIC Kitchens Action Anticipation Challenge. The consistency of the egocentric perspective of EPIC Kitchens allows for the utilization of the hand-centric cues upon which Ego-OMG relies. We demonstrate state-of-the-art performance, outranking all other previous published methods by large margins and ranking first on the unseen test set and second on the seen test set of the EPIC Kitchens Action Anticipation Challenge. We attribute the success of Ego-OMG to the modeling of semantic structure captured over long timespans. We evaluate the design choices made through several ablation studies. Code will be released upon acceptance
Evenly Cascaded Convolutional Networks
Jul 27, 2018



We introduce Evenly Cascaded convolutional Network (ECN), a neural network taking inspiration from the cascade algorithm of wavelet analysis. ECN employs two feature streams - a low-level and high-level steam. At each layer these streams interact, such that low-level features are modulated using advanced perspectives from the high-level stream. ECN is evenly structured through resizing feature map dimensions by a consistent ratio, which removes the burden of ad-hoc specification of feature map dimensions. ECN produces easily interpretable features maps, a result whose intuition can be understood in the context of scale-space theory. We demonstrate that ECN's design facilitates the training process through providing easily trainable shortcuts. We report new state-of-the-art results for small networks, without the need for additional treatment such as pruning or compression - a consequence of ECN's simple structure and direct training. A 6-layered ECN design with under 500k parameters achieves 95.24% and 78.99% accuracy on CIFAR-10 and CIFAR-100 datasets, respectively, outperforming the current state-of-the-art on small parameter networks, and a 3 million parameter ECN produces results competitive to the state-of-the-art.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015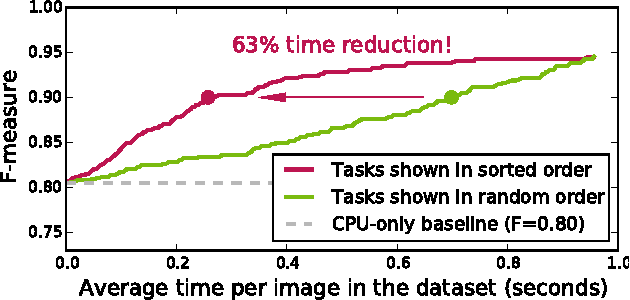
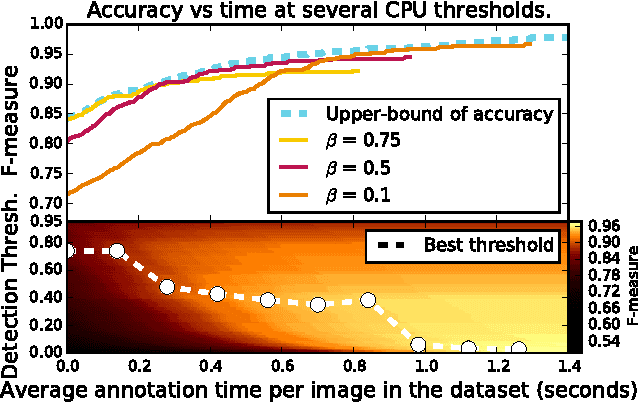
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.