 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAP: LLM-Generation of Egocentric Action Programs
Nov 29, 2023



We introduce LEAP (illustrated in Figure 1), a novel method for generating video-grounded action programs through use of a Large Language Model (LLM). These action programs represent the motoric, perceptual, and structural aspects of action, and consist of sub-actions, pre- and post-conditions, and control flows. LEAP's action programs are centered on egocentric video and employ recent developments in LLMs both as a source for program knowledge and as an aggregator and assessor of multimodal video information. We apply LEAP over a majority (87\%) of the training set of the EPIC Kitchens dataset, and release the resulting action programs as a publicly available dataset here (https://drive.google.com/drive/folders/1Cpkw_TI1IIxXdzor0pOXG3rWJWuKU5Ex?usp=drive_link). We employ LEAP as a secondary source of supervision, using its action programs in a loss term applied to action recognition and anticipation networks. We demonstrate sizable improvements in performance in both tasks due to training with the LEAP dataset. Our method achieves 1st place on the EPIC Kitchens Action Recognition leaderboard as of November 17 among the networks restricted to RGB-input (see Supplementary Materials).
Therbligs in Action: Video Understanding through Motion Primitives
Apr 06, 2023In this paper we introduce a rule-based, compositional, and hierarchical modeling of action using Therbligs as our atoms. Introducing these atoms provides us with a consistent, expressive, contact-centered representation of action. Over the atoms we introduce a differentiable method of rule-based reasoning to regularize for logical consistency. Our approach is complementary to other approaches in that the Therblig-based representations produced by our architecture augment rather than replace existing architectures' representations. We release the first Therblig-centered annotations over two popular video datasets - EPIC Kitchens 100 and 50-Salads. We also broadly demonstrate benefits to adopting Therblig representations through evaluation on the following tasks: action segmentation, action anticipation, and action recognition - observing an average 10.5\%/7.53\%/6.5\% relative improvement, respectively, over EPIC Kitchens and an average 8.9\%/6.63\%/4.8\% relative improvement, respectively, over 50 Salads. Code and data will be made publicly available.
Forecasting Action through Contact Representations from First Person Video
Feb 01, 2021



Human actions involving hand manipulations are structured according to the making and breaking of hand-object contact, and human visual understanding of action is reliant on anticipation of contact as is demonstrated by pioneering work in cognitive science. Taking inspiration from this, we introduce representations and models centered on contact, which we then use in action prediction and anticipation. We annotate a subset of the EPIC Kitchens dataset to include time-to-contact between hands and objects, as well as segmentations of hands and objects. Using these annotations we train the Anticipation Module, a module producing Contact Anticipation Maps and Next Active Object Segmentations - novel low-level representations providing temporal and spatial characteristics of anticipated near future action. On top of the Anticipation Module we apply Egocentric Object Manipulation Graphs (Ego-OMG), a framework for action anticipation and prediction. Ego-OMG models longer term temporal semantic relations through the use of a graph modeling transitions between contact delineated action states. Use of the Anticipation Module within Ego-OMG produces state-of-the-art results, achieving 1st and 2nd place on the unseen and seen test sets, respectively, of the EPIC Kitchens Action Anticipation Challenge, and achieving state-of-the-art results on the tasks of action anticipation and action prediction over EPIC Kitchens. We perform ablation studies over characteristics of the Anticipation Module to evaluate their utility.
Egocentric Object Manipulation Graphs
Jun 05, 2020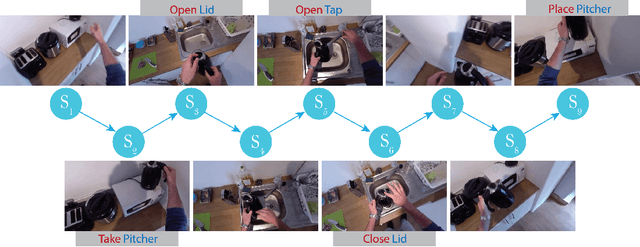
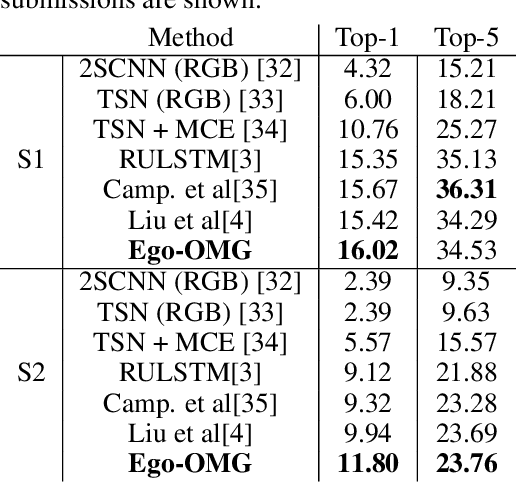


We introduce Egocentric Object Manipulation Graphs (Ego-OMG) - a novel representation for activity modeling and anticipation of near future actions integrating three components: 1) semantic temporal structure of activities, 2) short-term dynamics, and 3) representations for appearance. Semantic temporal structure is modeled through a graph, embedded through a Graph Convolutional Network, whose states model characteristics of and relations between hands and objects. These state representations derive from all three levels of abstraction, and span segments delimited by the making and breaking of hand-object contact. Short-term dynamics are modeled in two ways: A) through 3D convolutions, and B) through anticipating the spatiotemporal end points of hand trajectories, where hands come into contact with objects. Appearance is modeled through deep spatiotemporal features produced through existing methods. We note that in Ego-OMG it is simple to swap these appearance features, and thus Ego-OMG is complementary to most existing action anticipation methods. We evaluate Ego-OMG on the EPIC Kitchens Action Anticipation Challenge. The consistency of the egocentric perspective of EPIC Kitchens allows for the utilization of the hand-centric cues upon which Ego-OMG relies. We demonstrate state-of-the-art performance, outranking all other previous published methods by large margins and ranking first on the unseen test set and second on the seen test set of the EPIC Kitchens Action Anticipation Challenge. We attribute the success of Ego-OMG to the modeling of semantic structure captured over long timespans. We evaluate the design choices made through several ablation studies. Code will be released upon acceptance
Following Instructions by Imagining and Reaching Visual Goals
Jan 25, 2020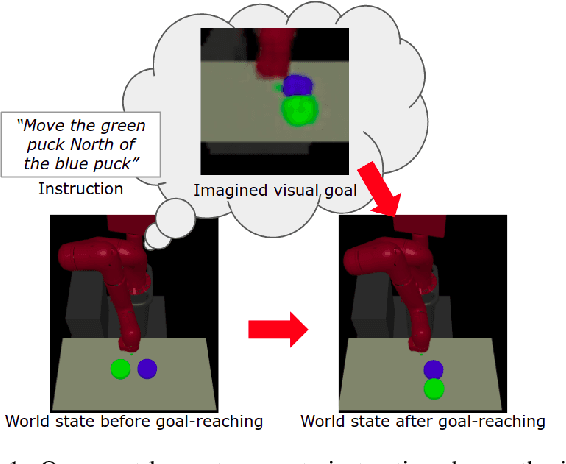
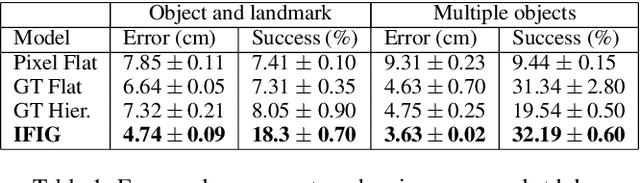
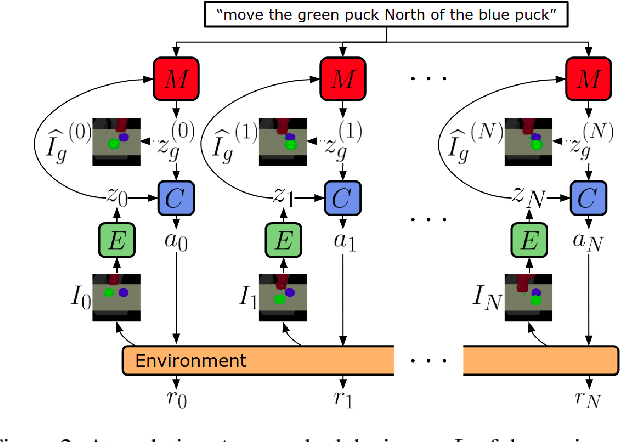
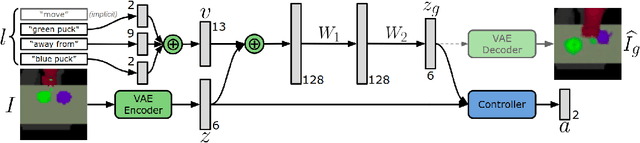
While traditional methods for instruction-following typically assume prior linguistic and perceptual knowledge, many recent works in reinforcement learning (RL) have proposed learning policies end-to-end, typically by training neural networks to map joint representations of observations and instructions directly to actions. In this work, we present a novel framework for learning to perform temporally extended tasks using spatial reasoning in the RL framework, by sequentially imagining visual goals and choosing appropriate actions to fulfill imagined goals. Our framework operates on raw pixel images, assumes no prior linguistic or perceptual knowledge, and learns via intrinsic motivation and a single extrinsic reward signal measuring task completion. We validate our method in two environments with a robot arm in a simulated interactive 3D environment. Our method outperforms two flat architectures with raw-pixel and ground-truth states, and a hierarchical architecture with ground-truth states on object arrangement tasks.