 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEANUT: Perturbations by Eigenvector Alignment for Attacking Graph Neural Networks Under Topology-Driven Message Passing
Mar 30, 2026Graph Neural Networks (GNNs) have achieved remarkable performance on tasks involving relational data. However, small perturbations to the graph structure can significantly alter GNN outputs, raising concerns about their robustness in real-world deployments. In this work, we explore the core vulnerability of GNNs which explicitly consume graph topology in the form of the adjacency matrix or Laplacian as a means for message passing, and propose PEANUT, a simple, gradient-free, restricted black-box attack that injects virtual nodes to capitalize on this vulnerability. PEANUT is a injection based attack, which is widely considered to be more practical and realistic scenario than graph modification attacks, where the attacker is able to modify the original graph structure directly. Our method works at the inference phase, making it an evasion attack, and is applicable almost immediately, since it does not involve lengthy iterative optimizations or parameter learning, which add computational and time overhead, or training surrogate models, which are susceptible to failure due to differences in model priors and generalization capabilities. PEANUT also does not require any features on the injected node and consequently demonstrates that GNN performance can be significantly deteriorated even with injected nodes with zeros for features, highlighting the significance of effectively designed connectivity in such attacks. Extensive experiments on real-world datasets across three graph tasks demonstrate the effectiveness of our attack despite its simplicity.
PEANUT: Perturbations by Eigenvalue Alignment for Attacking GNNs Under Topology-Driven Message Passing
Mar 27, 2026Graph Neural Networks (GNNs) have achieved remarkable performance on tasks involving relational data. However, small perturbations to the graph structure can significantly alter GNN outputs, raising concerns about their robustness in real-world deployments. In this work, we explore the core vulnerability of GNNs which explicitly consume graph topology in the form of the adjacency matrix or Laplacian as a means for message passing, and propose PEANUT, a simple, gradient-free, restricted black-box attack that injects virtual nodes to capitalize on this vulnerability. PEANUT is a injection based attack, which is widely considered to be more practical and realistic scenario than graph modification attacks, where the attacker is able to modify the original graph structure directly. Our method works at the inference phase, making it an evasion attack, and is applicable almost immediately, since it does not involve lengthy iterative optimizations or parameter learning, which add computational and time overhead, or training surrogate models, which are susceptible to failure due to differences in model priors and generalization capabilities. PEANUT also does not require any features on the injected node and consequently demonstrates that GNN performance can be significantly deteriorated even with injected nodes with zeros for features, highlighting the significance of effectively designed connectivity in such attacks. Extensive experiments on real-world datasets across three graph tasks demonstrate the effectiveness of our attack despite its simplicity.
Fed-GAME: Personalized Federated Learning with Graph Attention Mixture-of-Experts For Time-Series Forecasting
Mar 02, 2026Federated learning (FL) on graphs shows promise for distributed time-series forecasting. Yet, existing methods rely on static topologies and struggle with client heterogeneity. We propose Fed-GAME, a framework that models personalized aggregation as message passing over a learnable dynamic implicit graph. The core is a decoupled parameter difference-based update protocol, where clients transmit parameter differences between their fine-tuned private model and a shared global model. On the server, these differences are decomposed into two streams: (1) averaged difference used to updating the global model for consensus (2) the selective difference fed into a novel Graph Attention Mixture-of-Experts (GAME) aggregator for fine-grained personalization. In this aggregator, shared experts provide scoring signals while personalized gates adaptively weight selective updates to support personalized aggregation. Experiments on two real-world electric vehicle charging datasets demonstrate that Fed-GAME outperforms state-of-the-art personalized FL baselines.
VulCPE: Context-Aware Cybersecurity Vulnerability Retrieval and Management
May 20, 2025The dynamic landscape of cybersecurity demands precise and scalable solutions for vulnerability management in heterogeneous systems, where configuration-specific vulnerabilities are often misidentified due to inconsistent data in databases like the National Vulnerability Database (NVD). Inaccurate Common Platform Enumeration (CPE) data in NVD further leads to false positives and incomplete vulnerability retrieval. Informed by our systematic analysis of CPE and CVEdeails data, revealing more than 50% vendor name inconsistencies, we propose VulCPE, a framework that standardizes data and models configuration dependencies using a unified CPE schema (uCPE), entity recognition, relation extraction, and graph-based modeling. VulCPE achieves superior retrieval precision (0.766) and coverage (0.926) over existing tools. VulCPE ensures precise, context-aware vulnerability management, enhancing cyber resilience.
TabTreeFormer: Tabular Data Generation Using Hybrid Tree-Transformer
Jan 07, 2025



Transformers have achieved remarkable success in tabular data generation. However, they lack domain-specific inductive biases which are critical to preserving the intrinsic characteristics of tabular data. Meanwhile, they suffer from poor scalability and efficiency due to quadratic computational complexity. In this paper, we propose TabTreeFormer, a hybrid transformer architecture that incorporates a tree-based model that retains tabular-specific inductive biases of non-smooth and potentially low-correlated patterns caused by discreteness and non-rotational invariance, and hence enhances the fidelity and utility of synthetic data. In addition, we devise a dual-quantization tokenizer to capture the multimodal continuous distribution and further facilitate the learning of numerical value distribution. Moreover, our proposed tokenizer reduces the vocabulary size and sequence length due to the limited complexity (e.g., dimension-wise semantic meaning) of tabular data, rendering a significant model size shrink without sacrificing the capability of the transformer model. We evaluate TabTreeFormer on 10 datasets against multiple generative models on various metrics; our experimental results show that TabTreeFormer achieves superior fidelity, utility, privacy, and efficiency. Our best model yields a 40% utility improvement with 1/16 of the baseline model size.
UIBDiffusion: Universal Imperceptible Backdoor Attack for Diffusion Models
Dec 16, 2024Recent studies show that diffusion models (DMs) are vulnerable to backdoor attacks. Existing backdoor attacks impose unconcealed triggers (e.g., a gray box and eyeglasses) that contain evident patterns, rendering remarkable attack effects yet easy detection upon human inspection and defensive algorithms. While it is possible to improve stealthiness by reducing the strength of the backdoor, doing so can significantly compromise its generality and effectiveness. In this paper, we propose UIBDiffusion, the universal imperceptible backdoor attack for diffusion models, which allows us to achieve superior attack and generation performance while evading state-of-the-art defenses. We propose a novel trigger generation approach based on universal adversarial perturbations (UAPs) and reveal that such perturbations, which are initially devised for fooling pre-trained discriminative models, can be adapted as potent imperceptible backdoor triggers for DMs. We evaluate UIBDiffusion on multiple types of DMs with different kinds of samplers across various datasets and targets. Experimental results demonstrate that UIBDiffusion brings three advantages: 1) Universality, the imperceptible trigger is universal (i.e., image and model agnostic) where a single trigger is effective to any images and all diffusion models with different samplers; 2) Utility, it achieves comparable generation quality (e.g., FID) and even better attack success rate (i.e., ASR) at low poison rates compared to the prior works; and 3) Undetectability, UIBDiffusion is plausible to human perception and can bypass Elijah and TERD, the SOTA defenses against backdoors for DMs. We will release our backdoor triggers and code.
Generative AI for Data Augmentation in Wireless Networks: Analysis, Applications, and Case Study
Nov 13, 2024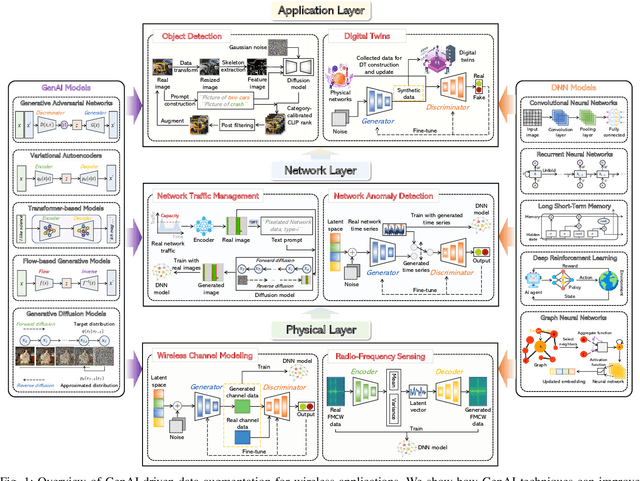
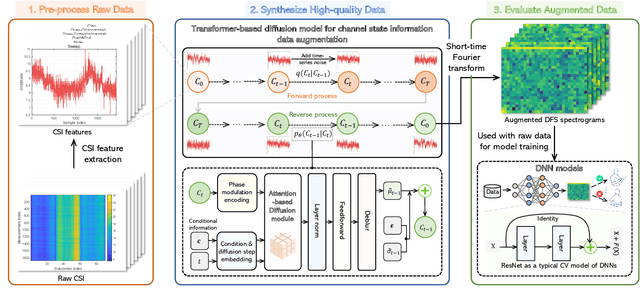
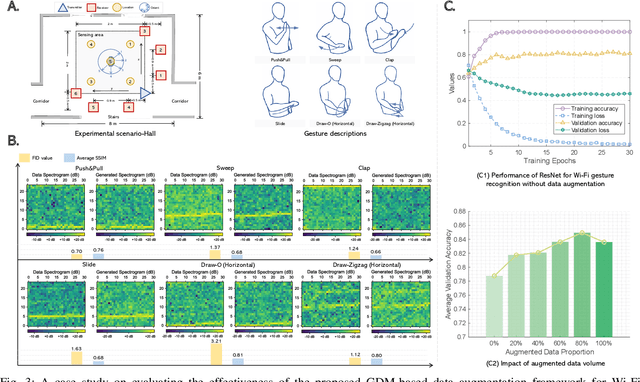
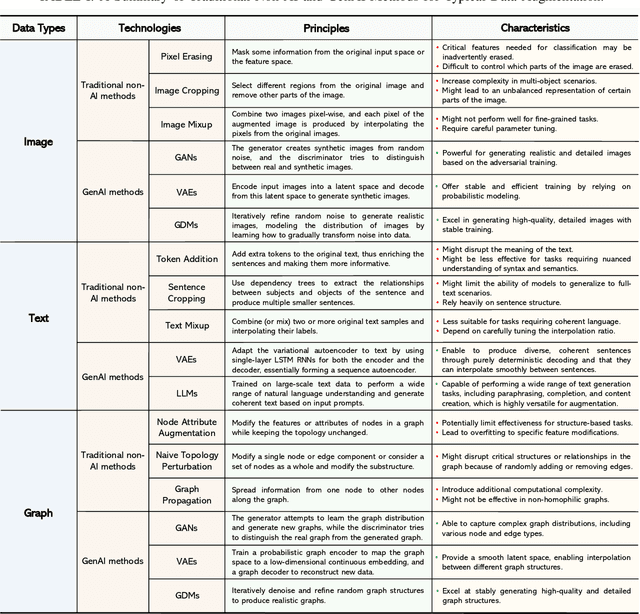
Data augmentation is a powerful technique to mitigate data scarcity. However, owing to fundamental differences in wireless data structures, traditional data augmentation techniques may not be suitable for wireless data. Fortunately, Generative Artificial Intelligence (GenAI) can be an effective alternative to wireless data augmentation due to its excellent data generation capability. This article systemically explores the potential and effectiveness of GenAI-driven data augmentation in wireless networks. We first briefly review data augmentation techniques, discuss their limitations in wireless networks, and introduce generative data augmentation, including reviewing GenAI models and their applications in data augmentation. We then explore the application prospects of GenAI-driven data augmentation in wireless networks from the physical, network, and application layers, which provides a GenAI-driven data augmentation architecture for each application. Subsequently, we propose a general generative diffusion model-based data augmentation framework for Wi-Fi gesture recognition, which uses transformer-based diffusion models to generate high-quality channel state information data. Furthermore, we develop residual neural network models for Wi-Fi gesture recognition to evaluate the role of augmented data and conduct a case study based on a real dataset. Simulation results demonstrate the effectiveness of the proposed framework. Finally, we discuss research directions for generative data augmentation.
TAEGAN: Generating Synthetic Tabular Data For Data Augmentation
Oct 02, 2024



Synthetic tabular data generation has gained significant attention for its potential in data augmentation, software testing and privacy-preserving data sharing. However, most research has primarily focused on larger datasets and evaluating their quality in terms of metrics like column-wise statistical distributions and inter-feature correlations, while often overlooking its utility for data augmentation, particularly for datasets whose data is scarce. In this paper, we propose Tabular Auto-Encoder Generative Adversarial Network (TAEGAN), an improved GAN-based framework for generating high-quality tabular data. Although large language models (LLMs)-based methods represent the state-of-the-art in synthetic tabular data generation, they are often overkill for small datasets due to their extensive size and complexity. TAEGAN employs a masked auto-encoder as the generator, which for the first time introduces the power of self-supervised pre-training in tabular data generation so that essentially exposes the networks to more information. We extensively evaluate TAEGAN against five state-of-the-art synthetic tabular data generation algorithms. Results from 10 datasets show that TAEGAN outperforms existing deep-learning-based tabular data generation models on 9 out of 10 datasets on the machine learning efficacy and achieves superior data augmentation performance on 7 out of 8 smaller datasets.
CombU: A Combined Unit Activation for Fitting Mathematical Expressions with Neural Networks
Sep 25, 2024



The activation functions are fundamental to neural networks as they introduce non-linearity into data relationships, thereby enabling deep networks to approximate complex data relations. Existing efforts to enhance neural network performance have predominantly focused on developing new mathematical functions. However, we find that a well-designed combination of existing activation functions within a neural network can also achieve this objective. In this paper, we introduce the Combined Units activation (CombU), which employs different activation functions at various dimensions across different layers. This approach can be theoretically proven to fit most mathematical expressions accurately. The experiments conducted on four mathematical expression datasets, compared against six State-Of-The-Art (SOTA) activation function algorithms, demonstrate that CombU outperforms all SOTA algorithms in 10 out of 16 metrics and ranks in the top three for the remaining six metrics.
VFLGAN-TS: Vertical Federated Learning-based Generative Adversarial Networks for Publication of Vertically Partitioned Time-Series Data
Sep 05, 2024



In the current artificial intelligence (AI) era, the scale and quality of the dataset play a crucial role in training a high-quality AI model. However, often original data cannot be shared due to privacy concerns and regulations. A potential solution is to release a synthetic dataset with a similar distribution to the private dataset. Nevertheless, in some scenarios, the attributes required to train an AI model are distributed among different parties, and the parties cannot share the local data for synthetic data construction due to privacy regulations. In PETS 2024, we recently introduced the first Vertical Federated Learning-based Generative Adversarial Network (VFLGAN) for publishing vertically partitioned static data. However, VFLGAN cannot effectively handle time-series data, presenting both temporal and attribute dimensions. In this article, we proposed VFLGAN-TS, which combines the ideas of attribute discriminator and vertical federated learning to generate synthetic time-series data in the vertically partitioned scenario. The performance of VFLGAN-TS is close to that of its counterpart, which is trained in a centralized manner and represents the upper limit for VFLGAN-TS. To further protect privacy, we apply a Gaussian mechanism to make VFLGAN-TS satisfy an $(\epsilon,\delta)$-differential privacy. Besides, we develop an enhanced privacy auditing scheme to evaluate the potential privacy breach through the framework of VFLGAN-TS and synthetic datasets.