 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabTreeFormer: Tabular Data Generation Using Hybrid Tree-Transformer
Jan 07, 2025



Transformers have achieved remarkable success in tabular data generation. However, they lack domain-specific inductive biases which are critical to preserving the intrinsic characteristics of tabular data. Meanwhile, they suffer from poor scalability and efficiency due to quadratic computational complexity. In this paper, we propose TabTreeFormer, a hybrid transformer architecture that incorporates a tree-based model that retains tabular-specific inductive biases of non-smooth and potentially low-correlated patterns caused by discreteness and non-rotational invariance, and hence enhances the fidelity and utility of synthetic data. In addition, we devise a dual-quantization tokenizer to capture the multimodal continuous distribution and further facilitate the learning of numerical value distribution. Moreover, our proposed tokenizer reduces the vocabulary size and sequence length due to the limited complexity (e.g., dimension-wise semantic meaning) of tabular data, rendering a significant model size shrink without sacrificing the capability of the transformer model. We evaluate TabTreeFormer on 10 datasets against multiple generative models on various metrics; our experimental results show that TabTreeFormer achieves superior fidelity, utility, privacy, and efficiency. Our best model yields a 40% utility improvement with 1/16 of the baseline model size.
Laplace Transform Interpretation of Differential Privacy
Nov 14, 2024


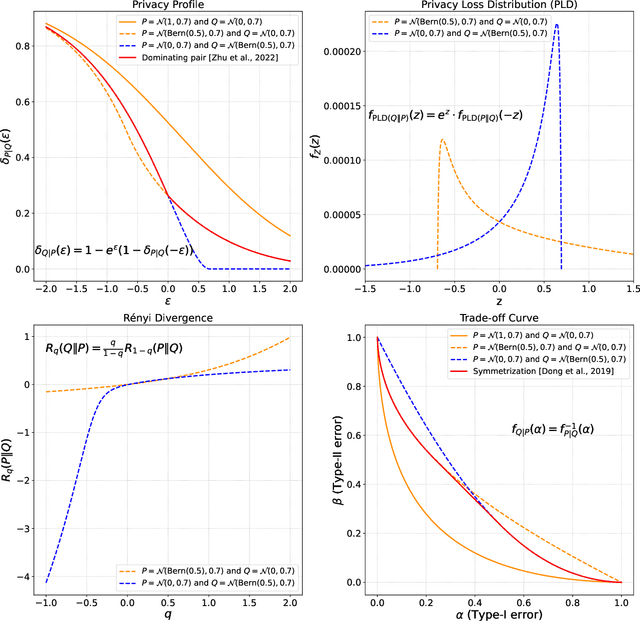
We introduce a set of useful expressions of Differential Privacy (DP) notions in terms of the Laplace transform of the privacy loss distribution. Its bare form expression appears in several related works on analyzing DP, either as an integral or an expectation. We show that recognizing the expression as a Laplace transform unlocks a new way to reason about DP properties by exploiting the duality between time and frequency domains. Leveraging our interpretation, we connect the $(q, \rho(q))$-R\'enyi DP curve and the $(\epsilon, \delta(\epsilon))$-DP curve as being the Laplace and inverse-Laplace transforms of one another. This connection shows that the R\'enyi divergence is well-defined for complex orders $q = \gamma + i \omega$. Using our Laplace transform-based analysis, we also prove an adaptive composition theorem for $(\epsilon, \delta)$-DP guarantees that is exactly tight (i.e., matches even in constants) for all values of $\epsilon$. Additionally, we resolve an issue regarding symmetry of $f$-DP on subsampling that prevented equivalence across all functional DP notions.
TAEGAN: Generating Synthetic Tabular Data For Data Augmentation
Oct 02, 2024



Synthetic tabular data generation has gained significant attention for its potential in data augmentation, software testing and privacy-preserving data sharing. However, most research has primarily focused on larger datasets and evaluating their quality in terms of metrics like column-wise statistical distributions and inter-feature correlations, while often overlooking its utility for data augmentation, particularly for datasets whose data is scarce. In this paper, we propose Tabular Auto-Encoder Generative Adversarial Network (TAEGAN), an improved GAN-based framework for generating high-quality tabular data. Although large language models (LLMs)-based methods represent the state-of-the-art in synthetic tabular data generation, they are often overkill for small datasets due to their extensive size and complexity. TAEGAN employs a masked auto-encoder as the generator, which for the first time introduces the power of self-supervised pre-training in tabular data generation so that essentially exposes the networks to more information. We extensively evaluate TAEGAN against five state-of-the-art synthetic tabular data generation algorithms. Results from 10 datasets show that TAEGAN outperforms existing deep-learning-based tabular data generation models on 9 out of 10 datasets on the machine learning efficacy and achieves superior data augmentation performance on 7 out of 8 smaller datasets.
CombU: A Combined Unit Activation for Fitting Mathematical Expressions with Neural Networks
Sep 25, 2024



The activation functions are fundamental to neural networks as they introduce non-linearity into data relationships, thereby enabling deep networks to approximate complex data relations. Existing efforts to enhance neural network performance have predominantly focused on developing new mathematical functions. However, we find that a well-designed combination of existing activation functions within a neural network can also achieve this objective. In this paper, we introduce the Combined Units activation (CombU), which employs different activation functions at various dimensions across different layers. This approach can be theoretically proven to fit most mathematical expressions accurately. The experiments conducted on four mathematical expression datasets, compared against six State-Of-The-Art (SOTA) activation function algorithms, demonstrate that CombU outperforms all SOTA algorithms in 10 out of 16 metrics and ranks in the top three for the remaining six metrics.