 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Dubuc: A New Similarity Measure for Time Series
Nov 15, 2024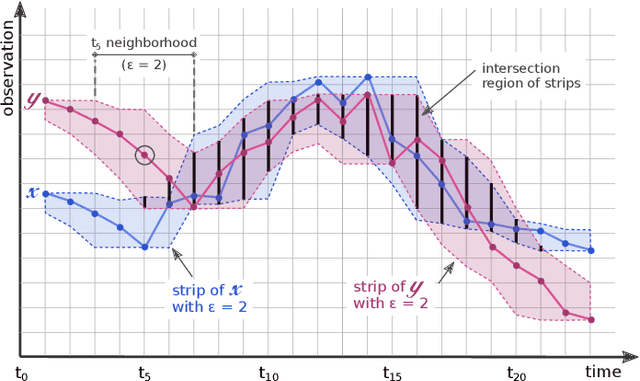
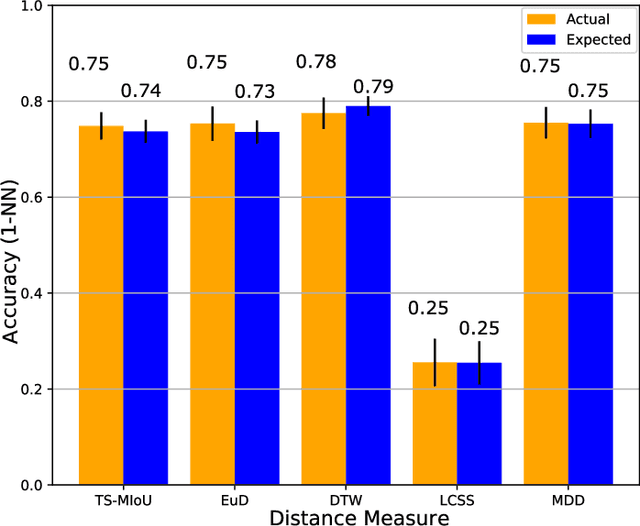
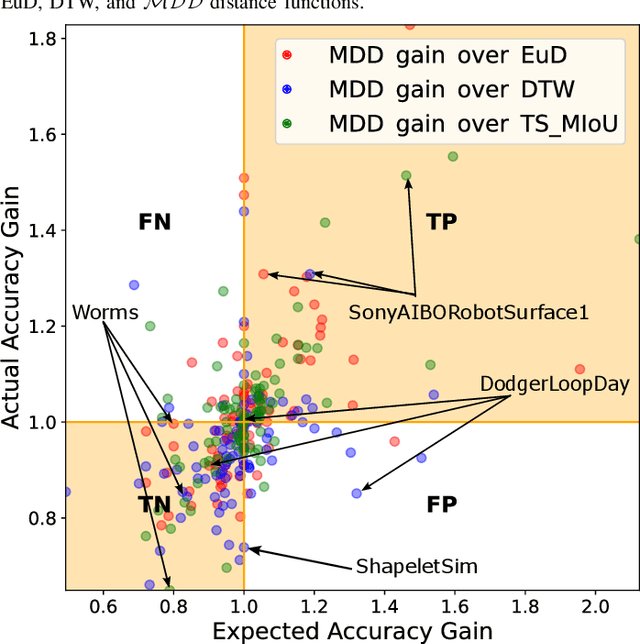
Quantifying similarities between time series in a meaningful way remains a challenge in time series analysis, despite many advances in the field. Most real-world solutions still rely on a few popular measures, such as Euclidean Distance (EuD), Longest Common Subsequence (LCSS), and Dynamic Time Warping (DTW). The strengths and weaknesses of these measures have been studied extensively, and incremental improvements have been proposed. In this study, however, we present a different similarity measure that fuses the notion of Dubuc's variation from fractal analysis with the Intersection-over-Union (IoU) measure which is widely used in object recognition (also known as the Jaccard Index). In this proof-of-concept paper, we introduce the Multiscale Dubuc Distance (MDD) measure and prove that it is a metric, possessing desirable properties such as the triangle inequality. We use 95 datasets from the UCR Time Series Classification Archive to compare MDD's performance with EuD, LCSS, and DTW. Our experiments show that MDD's overall success, without any case-specific customization, is comparable to DTW with optimized window sizes per dataset. We also highlight several datasets where MDD's performance improves significantly when its single parameter is customized. This customization serves as a powerful tool for gauging MDD's sensitivity to noise. Lastly, we show that MDD's running time is linear in the length of the time series, which is crucial for real-world applications involving very large datasets.
Measuring Class-Imbalance Sensitivity of Deterministic Performance Evaluation Metrics
Jun 20, 2022



The class-imbalance issue is intrinsic to many real-world machine learning tasks, particularly to the rare-event classification problems. Although the impact and treatment of imbalanced data is widely known, the magnitude of a metric's sensitivity to class imbalance has attracted little attention. As a result, often the sensitive metrics are dismissed while their sensitivity may only be marginal. In this paper, we introduce an intuitive evaluation framework that quantifies metrics' sensitivity to the class imbalance. Moreover, we reveal an interesting fact that there is a logarithmic behavior in metrics' sensitivity meaning that the higher imbalance ratios are associated with the lower sensitivity of metrics. Our framework builds an intuitive understanding of the class-imbalance impact on metrics. We believe this can help avoid many common mistakes, specially the less-emphasized and incorrect assumption that all metrics' quantities are comparable under different class-imbalance ratios.
Improving Solar Flare Prediction by Time Series Outlier Detection
Jun 14, 2022


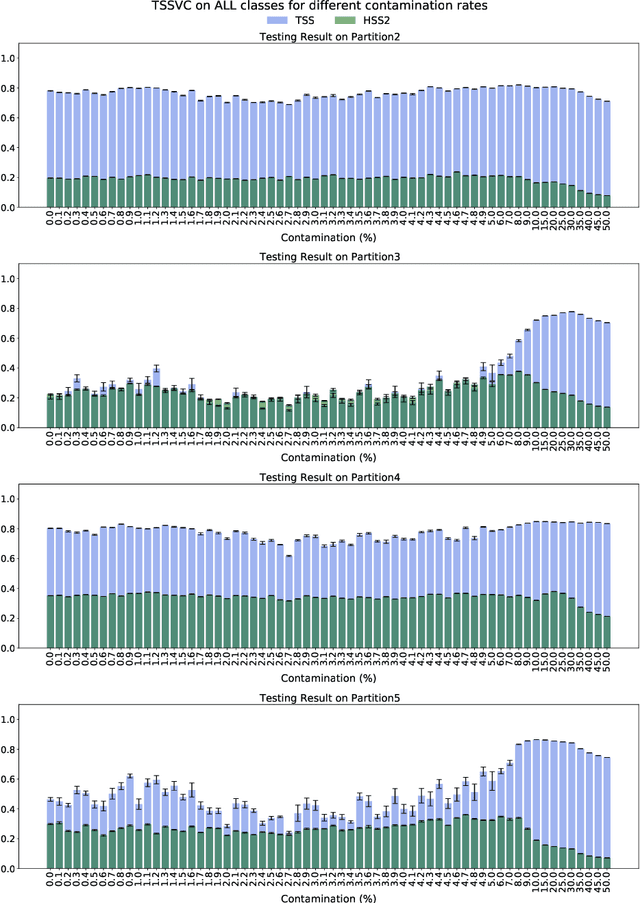
Solar flares not only pose risks to outer space technologies and astronauts' well being, but also cause disruptions on earth to our hight-tech, interconnected infrastructure our lives highly depend on. While a number of machine-learning methods have been proposed to improve flare prediction, none of them, to the best of our knowledge, have investigated the impact of outliers on the reliability and those models' performance. In this study, we investigate the impact of outliers in a multivariate time series benchmark dataset, namely SWAN-SF, on flare prediction models, and test our hypothesis. That is, there exist outliers in SWAN-SF, removal of which enhances the performance of the prediction models on unseen datasets. We employ Isolation Forest to detect the outliers among the weaker flare instances. Several experiments are carried out using a large range of contamination rates which determine the percentage of present outliers. We asses the quality of each dataset in terms of its actual contamination using TimeSeriesSVC. In our best finding, we achieve a 279% increase in True Skill Statistic and 68% increase in Heidke Skill Score. The results show that overall a significant improvement can be achieved to flare prediction if outliers are detected and removed properly.
Feature Selection on a Flare Forecasting Testbed: A Comparative Study of 24 Methods
Sep 30, 2021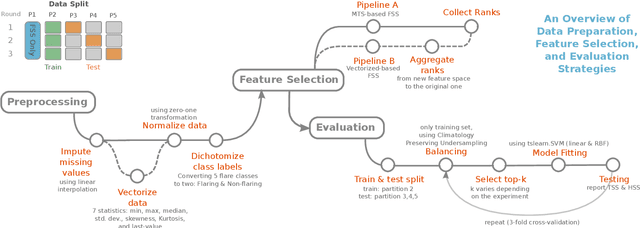
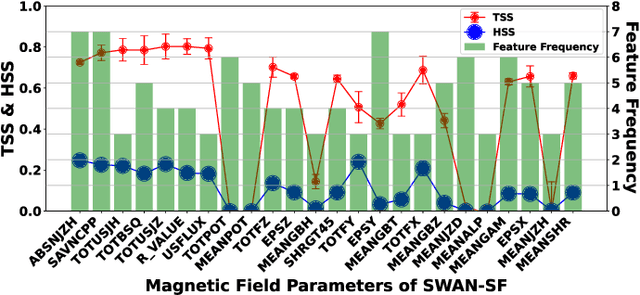
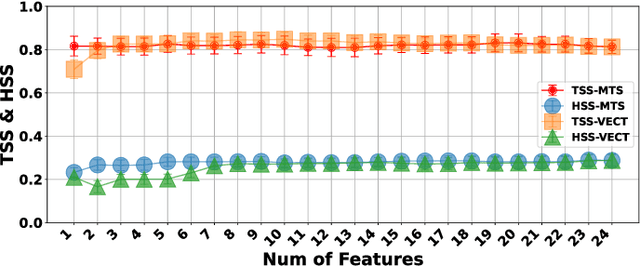
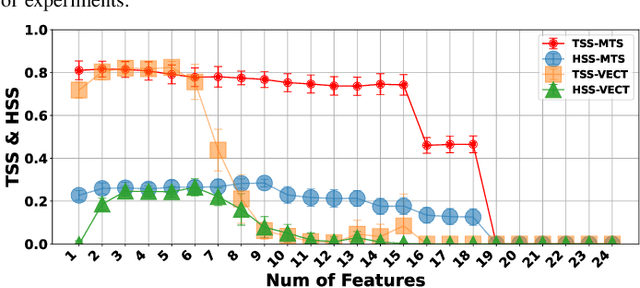
The Space-Weather ANalytics for Solar Flares (SWAN-SF) is a multivariate time series benchmark dataset recently created to serve the heliophysics community as a testbed for solar flare forecasting models. SWAN-SF contains 54 unique features, with 24 quantitative features computed from the photospheric magnetic field maps of active regions, describing their precedent flare activity. In this study, for the first time, we systematically attacked the problem of quantifying the relevance of these features to the ambitious task of flare forecasting. We implemented an end-to-end pipeline for preprocessing, feature selection, and evaluation phases. We incorporated 24 Feature Subset Selection (FSS) algorithms, including multivariate and univariate, supervised and unsupervised, wrappers and filters. We methodologically compared the results of different FSS algorithms, both on the multivariate time series and vectorized formats, and tested their correlation and reliability, to the extent possible, by using the selected features for flare forecasting on unseen data, in univariate and multivariate fashions. We concluded our investigation with a report of the best FSS methods in terms of their top-k features, and the analysis of the findings. We wish the reproducibility of our study and the availability of the data allow the future attempts be comparable with our findings and themselves.
Multiscale IoU: A Metric for Evaluation of Salient Object Detection with Fine Structures
May 30, 2021
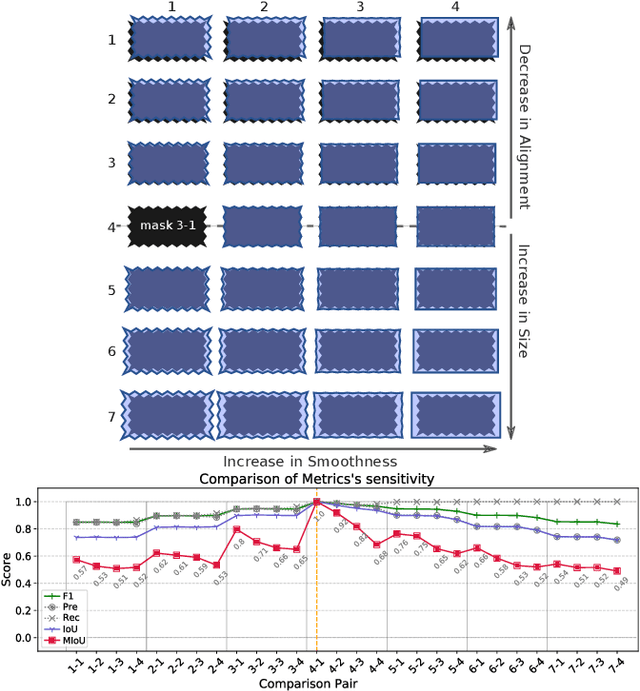

General-purpose object-detection algorithms often dismiss the fine structure of detected objects. This can be traced back to how their proposed regions are evaluated. Our goal is to renegotiate the trade-off between the generality of these algorithms and their coarse detections. In this work, we present a new metric that is a marriage of a popular evaluation metric, namely Intersection over Union (IoU), and a geometrical concept, called fractal dimension. We propose Multiscale IoU (MIoU) which allows comparison between the detected and ground-truth regions at multiple resolution levels. Through several reproducible examples, we show that MIoU is indeed sensitive to the fine boundary structures which are completely overlooked by IoU and f1-score. We further examine the overall reliability of MIoU by comparing its distribution with that of IoU on synthetic and real-world datasets of objects. We intend this work to re-initiate exploration of new evaluation methods for object-detection algorithms.
Towards Synthetic Multivariate Time Series Generation for Flare Forecasting
May 16, 2021
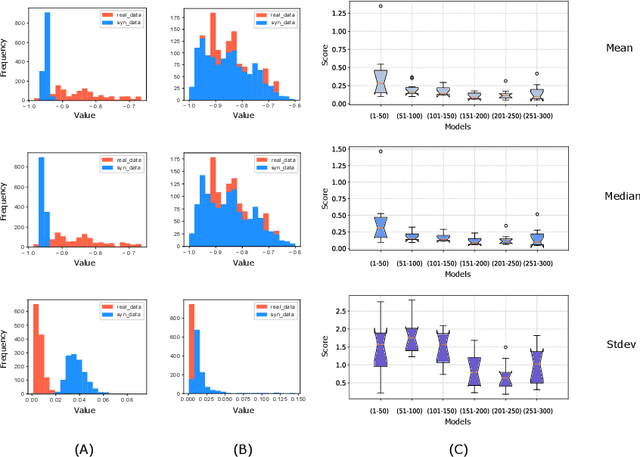


One of the limiting factors in training data-driven, rare-event prediction algorithms is the scarcity of the events of interest resulting in an extreme imbalance in the data. There have been many methods introduced in the literature for overcoming this issue; simple data manipulation through undersampling and oversampling, utilizing cost-sensitive learning algorithms, or by generating synthetic data points following the distribution of the existing data. While synthetic data generation has recently received a great deal of attention, there are real challenges involved in doing so for high-dimensional data such as multivariate time series. In this study, we explore the usefulness of the conditional generative adversarial network (CGAN) as a means to perform data-informed oversampling in order to balance a large dataset of multivariate time series. We utilize a flare forecasting benchmark dataset, named SWAN-SF, and design two verification methods to both quantitatively and qualitatively evaluate the similarity between the generated minority and the ground-truth samples. We further assess the quality of the generated samples by training a classical, supervised machine learning algorithm on synthetic data, and testing the trained model on the unseen, real data. The results show that the classifier trained on the data augmented with the synthetic multivariate time series achieves a significant improvement compared with the case where no augmentation is used. The popular flare forecasting evaluation metrics, TSS and HSS, report 20-fold and 5-fold improvements, respectively, indicating the remarkable statistical similarities, and the usefulness of CGAN-based data generation for complicated tasks such as flare forecasting.
How to Train Your Flare Prediction Model: Revisiting Robust Sampling of Rare Events
Mar 12, 2021
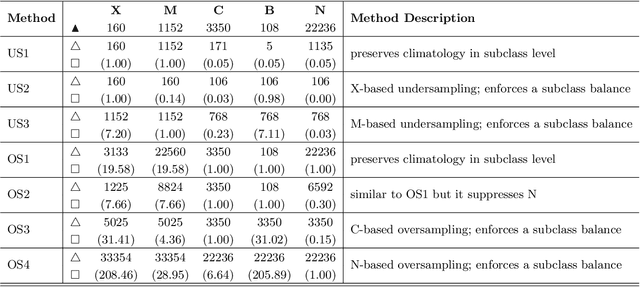
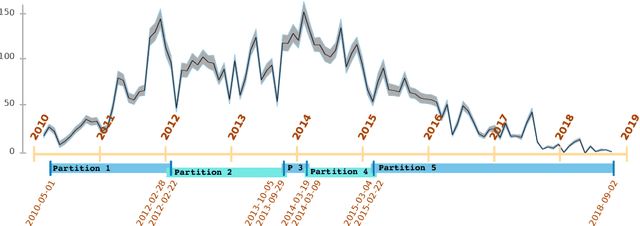
We present a case study of solar flare forecasting by means of metadata feature time series, by treating it as a prominent class-imbalance and temporally coherent problem. Taking full advantage of pre-flare time series in solar active regions is made possible via the Space Weather Analytics for Solar Flares (SWAN-SF) benchmark dataset; a partitioned collection of multivariate time series of active region properties comprising 4075 regions and spanning over 9 years of the Solar Dynamics Observatory (SDO) period of operations. We showcase the general concept of temporal coherence triggered by the demand of continuity in time series forecasting and show that lack of proper understanding of this effect may spuriously enhance models' performance. We further address another well-known challenge in rare event prediction, namely, the class-imbalance issue. The SWAN-SF is an appropriate dataset for this, with a 60:1 imbalance ratio for GOES M- and X-class flares and a 800:1 for X-class flares against flare-quiet instances. We revisit the main remedies for these challenges and present several experiments to illustrate the exact impact that each of these remedies may have on performance. Moreover, we acknowledge that some basic data manipulation tasks such as data normalization and cross validation may also impact the performance -- we discuss these problems as well. In this framework we also review the primary advantages and disadvantages of using true skill statistic and Heidke skill score, as two widely used performance verification metrics for the flare forecasting task. In conclusion, we show and advocate for the benefits of time series vs. point-in-time forecasting, provided that the above challenges are measurably and quantitatively addressed.
Machine Learning in Heliophysics and Space Weather Forecasting: A White Paper of Findings and Recommendations
Jun 22, 2020The authors of this white paper met on 16-17 January 2020 at the New Jersey Institute of Technology, Newark, NJ, for a 2-day workshop that brought together a group of heliophysicists, data providers, expert modelers, and computer/data scientists. Their objective was to discuss critical developments and prospects of the application of machine and/or deep learning techniques for data analysis, modeling and forecasting in Heliophysics, and to shape a strategy for further developments in the field. The workshop combined a set of plenary sessions featuring invited introductory talks interleaved with a set of open discussion sessions. The outcome of the discussion is encapsulated in this white paper that also features a top-level list of recommendations agreed by participants.
Challenges with Extreme Class-Imbalance and Temporal Coherence: A Study on Solar Flare Data
Nov 20, 2019
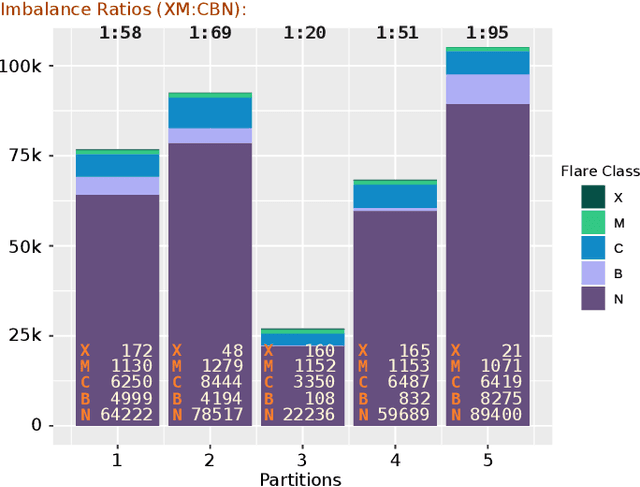
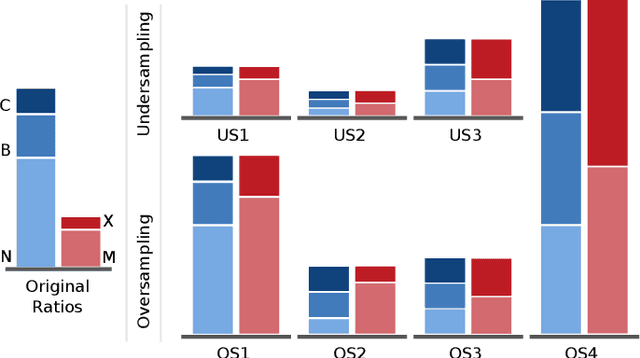
In analyses of rare-events, regardless of the domain of application, class-imbalance issue is intrinsic. Although the challenges are known to data experts, their explicit impact on the analytic and the decisions made based on the findings are often overlooked. This is in particular prevalent in interdisciplinary research where the theoretical aspects are sometimes overshadowed by the challenges of the application. To show-case these undesirable impacts, we conduct a series of experiments on a recently created benchmark data, named Space Weather ANalytics for Solar Flares (SWAN-SF). This is a multivariate time series dataset of magnetic parameters of active regions. As a remedy for the imbalance issue, we study the impact of data manipulation (undersampling and oversampling) and model manipulation (using class weights). Furthermore, we bring to focus the auto-correlation of time series that is inherited from the use of sliding window for monitoring flares' history. Temporal coherence, as we call this phenomenon, invalidates the randomness assumption, thus impacting all sampling practices including different cross-validation techniques. We illustrate how failing to notice this concept could give an artificial boost in the forecast performance and result in misleading findings. Throughout this study we utilized Support Vector Machine as a classifier, and True Skill Statistics as a verification metric for comparison of experiments. We conclude our work by specifying the correct practice in each case, and we hope that this study could benefit researchers in other domains where time series of rare events are of interest.
Toward Filament Segmentation Using Deep Neural Networks
Nov 20, 2019



We use a well-known deep neural network framework, called Mask R-CNN, for identification of solar filaments in full-disk H-alpha images from Big Bear Solar Observatory (BBSO). The image data, collected from BBSO's archive, are integrated with the spatiotemporal metadata of filaments retrieved from the Heliophysics Events Knowledgebase (HEK) system. This integrated data is then treated as the ground-truth in the training process of the model. The available spatial metadata are the output of a currently running filament-detection module developed and maintained by the Feature Finding Team; an international consortium selected by NASA. Despite the known challenges in the identification and characterization of filaments by the existing module, which in turn are inherited into any other module that intends to learn from such outputs, Mask R-CNN shows promising results. Trained and validated on two years worth of BBSO data, this model is then tested on the three following years. Our case-by-case and overall analyses show that Mask R-CNN can clearly compete with the existing module and in some cases even perform better. Several cases of false positives and false negatives, that are correctly segmented by this model are also shown. The overall advantages of using the proposed model are two-fold: First, deep neural networks' performance generally improves as more annotated data, or better annotations are provided. Second, such a model can be scaled up to detect other solar events, as well as a single multi-purpose module. The results presented in this study introduce a proof of concept in benefits of employing deep neural networks for detection of solar events, and in particular, filaments.