 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Dubuc: A New Similarity Measure for Time Series
Nov 15, 2024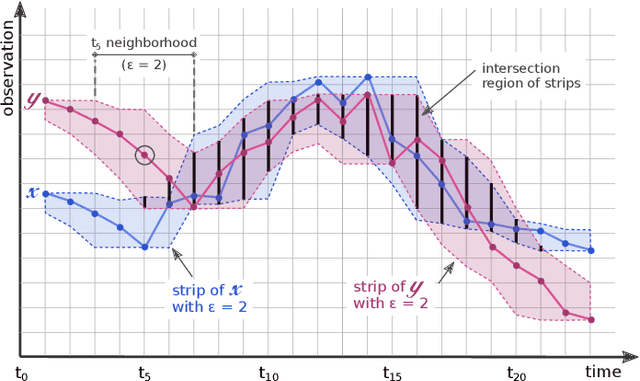
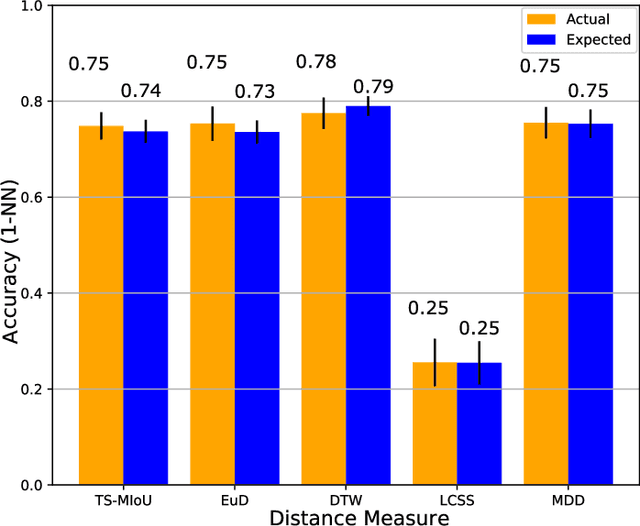
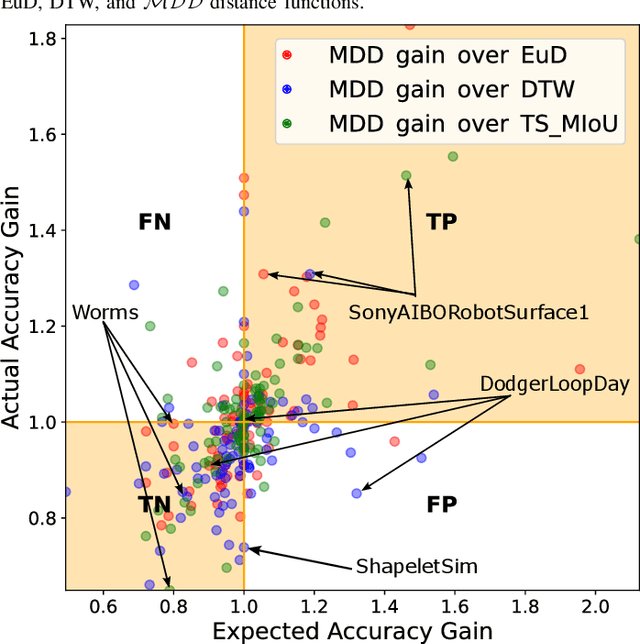
Quantifying similarities between time series in a meaningful way remains a challenge in time series analysis, despite many advances in the field. Most real-world solutions still rely on a few popular measures, such as Euclidean Distance (EuD), Longest Common Subsequence (LCSS), and Dynamic Time Warping (DTW). The strengths and weaknesses of these measures have been studied extensively, and incremental improvements have been proposed. In this study, however, we present a different similarity measure that fuses the notion of Dubuc's variation from fractal analysis with the Intersection-over-Union (IoU) measure which is widely used in object recognition (also known as the Jaccard Index). In this proof-of-concept paper, we introduce the Multiscale Dubuc Distance (MDD) measure and prove that it is a metric, possessing desirable properties such as the triangle inequality. We use 95 datasets from the UCR Time Series Classification Archive to compare MDD's performance with EuD, LCSS, and DTW. Our experiments show that MDD's overall success, without any case-specific customization, is comparable to DTW with optimized window sizes per dataset. We also highlight several datasets where MDD's performance improves significantly when its single parameter is customized. This customization serves as a powerful tool for gauging MDD's sensitivity to noise. Lastly, we show that MDD's running time is linear in the length of the time series, which is crucial for real-world applications involving very large datasets.
Feature Selection on a Flare Forecasting Testbed: A Comparative Study of 24 Methods
Sep 30, 2021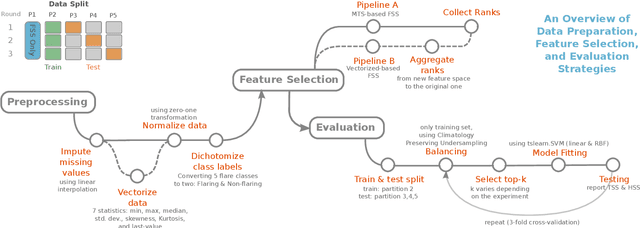
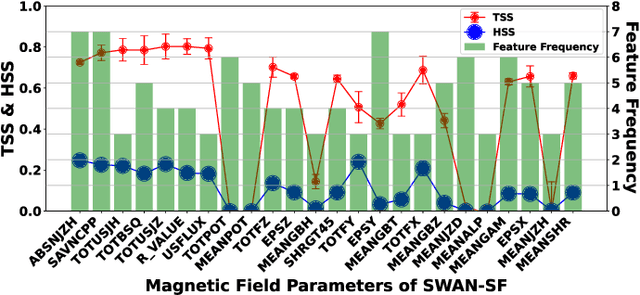
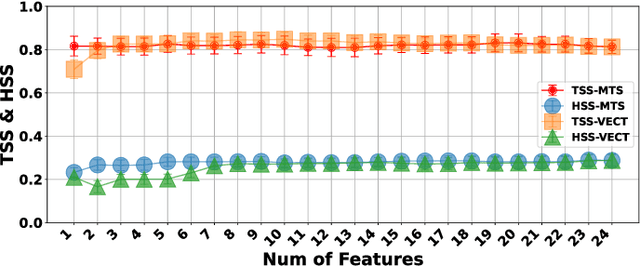
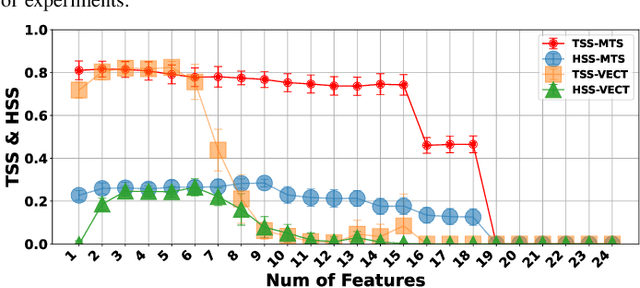
The Space-Weather ANalytics for Solar Flares (SWAN-SF) is a multivariate time series benchmark dataset recently created to serve the heliophysics community as a testbed for solar flare forecasting models. SWAN-SF contains 54 unique features, with 24 quantitative features computed from the photospheric magnetic field maps of active regions, describing their precedent flare activity. In this study, for the first time, we systematically attacked the problem of quantifying the relevance of these features to the ambitious task of flare forecasting. We implemented an end-to-end pipeline for preprocessing, feature selection, and evaluation phases. We incorporated 24 Feature Subset Selection (FSS) algorithms, including multivariate and univariate, supervised and unsupervised, wrappers and filters. We methodologically compared the results of different FSS algorithms, both on the multivariate time series and vectorized formats, and tested their correlation and reliability, to the extent possible, by using the selected features for flare forecasting on unseen data, in univariate and multivariate fashions. We concluded our investigation with a report of the best FSS methods in terms of their top-k features, and the analysis of the findings. We wish the reproducibility of our study and the availability of the data allow the future attempts be comparable with our findings and themselves.