 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFAD: A Novel Metric for Assessing Generated Time Series Data Utilizing Fourier Transform and Auto-encoder
Mar 11, 2024The success of deep learning-based generative models in producing realistic images, videos, and audios has led to a crucial consideration: how to effectively assess the quality of synthetic samples. While the Fr\'{e}chet Inception Distance (FID) serves as the standard metric for evaluating generative models in image synthesis, a comparable metric for time series data is notably absent. This gap in assessment capabilities stems from the absence of a widely accepted feature vector extractor pre-trained on benchmark time series datasets. In addressing these challenges related to assessing the quality of time series, particularly in the context of Fr\'echet Distance, this work proposes a novel solution leveraging the Fourier transform and Auto-encoder, termed the Fr\'{e}chet Fourier-transform Auto-encoder Distance (FFAD). Through our experimental results, we showcase the potential of FFAD for effectively distinguishing samples from different classes. This novel metric emerges as a fundamental tool for the evaluation of generative time series data, contributing to the ongoing efforts of enhancing assessment methodologies in the realm of deep learning-based generative models.
Multiscale IoU: A Metric for Evaluation of Salient Object Detection with Fine Structures
May 30, 2021
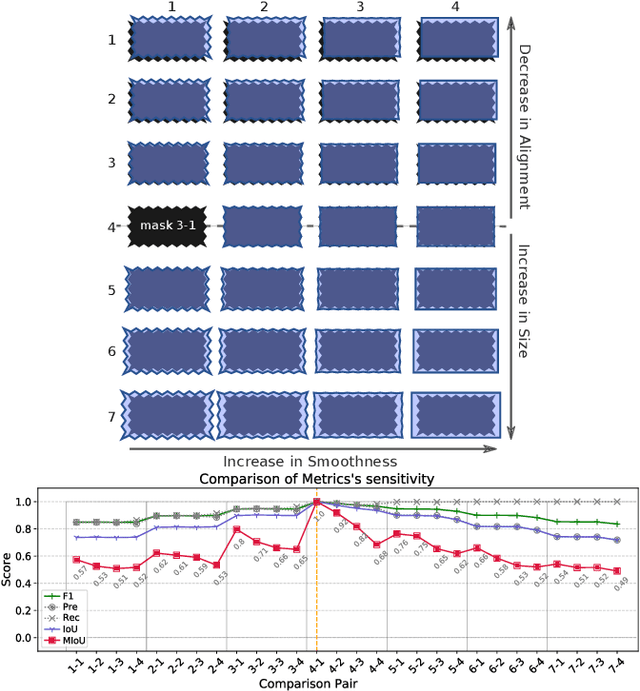

General-purpose object-detection algorithms often dismiss the fine structure of detected objects. This can be traced back to how their proposed regions are evaluated. Our goal is to renegotiate the trade-off between the generality of these algorithms and their coarse detections. In this work, we present a new metric that is a marriage of a popular evaluation metric, namely Intersection over Union (IoU), and a geometrical concept, called fractal dimension. We propose Multiscale IoU (MIoU) which allows comparison between the detected and ground-truth regions at multiple resolution levels. Through several reproducible examples, we show that MIoU is indeed sensitive to the fine boundary structures which are completely overlooked by IoU and f1-score. We further examine the overall reliability of MIoU by comparing its distribution with that of IoU on synthetic and real-world datasets of objects. We intend this work to re-initiate exploration of new evaluation methods for object-detection algorithms.
Towards Synthetic Multivariate Time Series Generation for Flare Forecasting
May 16, 2021
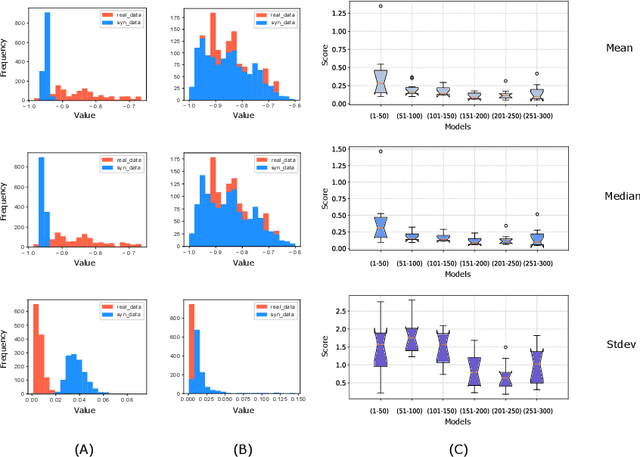


One of the limiting factors in training data-driven, rare-event prediction algorithms is the scarcity of the events of interest resulting in an extreme imbalance in the data. There have been many methods introduced in the literature for overcoming this issue; simple data manipulation through undersampling and oversampling, utilizing cost-sensitive learning algorithms, or by generating synthetic data points following the distribution of the existing data. While synthetic data generation has recently received a great deal of attention, there are real challenges involved in doing so for high-dimensional data such as multivariate time series. In this study, we explore the usefulness of the conditional generative adversarial network (CGAN) as a means to perform data-informed oversampling in order to balance a large dataset of multivariate time series. We utilize a flare forecasting benchmark dataset, named SWAN-SF, and design two verification methods to both quantitatively and qualitatively evaluate the similarity between the generated minority and the ground-truth samples. We further assess the quality of the generated samples by training a classical, supervised machine learning algorithm on synthetic data, and testing the trained model on the unseen, real data. The results show that the classifier trained on the data augmented with the synthetic multivariate time series achieves a significant improvement compared with the case where no augmentation is used. The popular flare forecasting evaluation metrics, TSS and HSS, report 20-fold and 5-fold improvements, respectively, indicating the remarkable statistical similarities, and the usefulness of CGAN-based data generation for complicated tasks such as flare forecasting.
How to Train Your Flare Prediction Model: Revisiting Robust Sampling of Rare Events
Mar 12, 2021
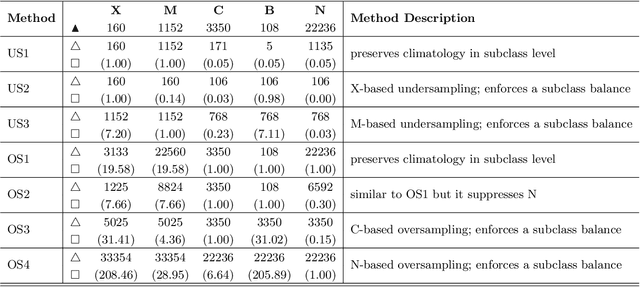
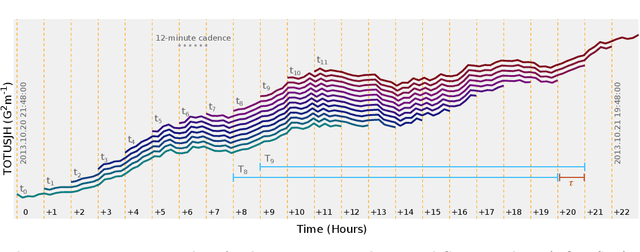
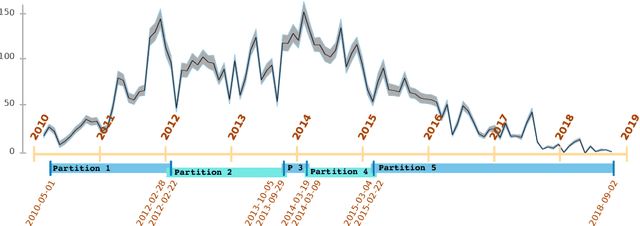
We present a case study of solar flare forecasting by means of metadata feature time series, by treating it as a prominent class-imbalance and temporally coherent problem. Taking full advantage of pre-flare time series in solar active regions is made possible via the Space Weather Analytics for Solar Flares (SWAN-SF) benchmark dataset; a partitioned collection of multivariate time series of active region properties comprising 4075 regions and spanning over 9 years of the Solar Dynamics Observatory (SDO) period of operations. We showcase the general concept of temporal coherence triggered by the demand of continuity in time series forecasting and show that lack of proper understanding of this effect may spuriously enhance models' performance. We further address another well-known challenge in rare event prediction, namely, the class-imbalance issue. The SWAN-SF is an appropriate dataset for this, with a 60:1 imbalance ratio for GOES M- and X-class flares and a 800:1 for X-class flares against flare-quiet instances. We revisit the main remedies for these challenges and present several experiments to illustrate the exact impact that each of these remedies may have on performance. Moreover, we acknowledge that some basic data manipulation tasks such as data normalization and cross validation may also impact the performance -- we discuss these problems as well. In this framework we also review the primary advantages and disadvantages of using true skill statistic and Heidke skill score, as two widely used performance verification metrics for the flare forecasting task. In conclusion, we show and advocate for the benefits of time series vs. point-in-time forecasting, provided that the above challenges are measurably and quantitatively addressed.
Challenges with Extreme Class-Imbalance and Temporal Coherence: A Study on Solar Flare Data
Nov 20, 2019
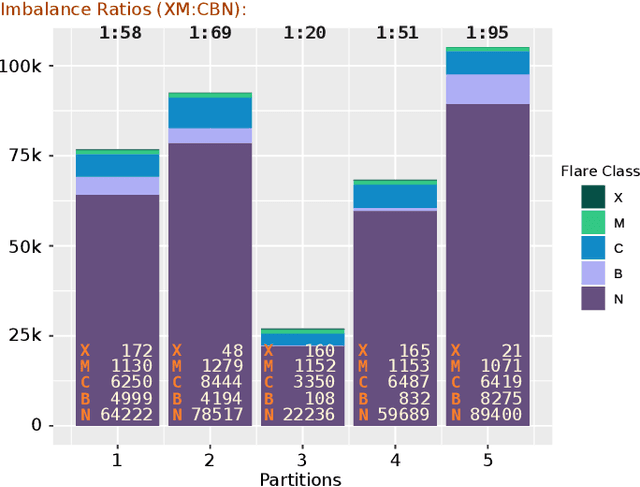
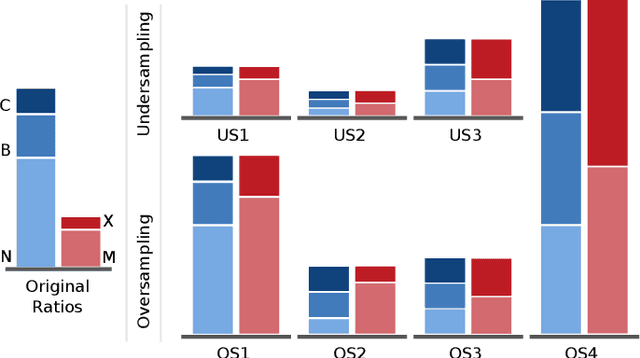
In analyses of rare-events, regardless of the domain of application, class-imbalance issue is intrinsic. Although the challenges are known to data experts, their explicit impact on the analytic and the decisions made based on the findings are often overlooked. This is in particular prevalent in interdisciplinary research where the theoretical aspects are sometimes overshadowed by the challenges of the application. To show-case these undesirable impacts, we conduct a series of experiments on a recently created benchmark data, named Space Weather ANalytics for Solar Flares (SWAN-SF). This is a multivariate time series dataset of magnetic parameters of active regions. As a remedy for the imbalance issue, we study the impact of data manipulation (undersampling and oversampling) and model manipulation (using class weights). Furthermore, we bring to focus the auto-correlation of time series that is inherited from the use of sliding window for monitoring flares' history. Temporal coherence, as we call this phenomenon, invalidates the randomness assumption, thus impacting all sampling practices including different cross-validation techniques. We illustrate how failing to notice this concept could give an artificial boost in the forecast performance and result in misleading findings. Throughout this study we utilized Support Vector Machine as a classifier, and True Skill Statistics as a verification metric for comparison of experiments. We conclude our work by specifying the correct practice in each case, and we hope that this study could benefit researchers in other domains where time series of rare events are of interest.
Toward Filament Segmentation Using Deep Neural Networks
Nov 20, 2019



We use a well-known deep neural network framework, called Mask R-CNN, for identification of solar filaments in full-disk H-alpha images from Big Bear Solar Observatory (BBSO). The image data, collected from BBSO's archive, are integrated with the spatiotemporal metadata of filaments retrieved from the Heliophysics Events Knowledgebase (HEK) system. This integrated data is then treated as the ground-truth in the training process of the model. The available spatial metadata are the output of a currently running filament-detection module developed and maintained by the Feature Finding Team; an international consortium selected by NASA. Despite the known challenges in the identification and characterization of filaments by the existing module, which in turn are inherited into any other module that intends to learn from such outputs, Mask R-CNN shows promising results. Trained and validated on two years worth of BBSO data, this model is then tested on the three following years. Our case-by-case and overall analyses show that Mask R-CNN can clearly compete with the existing module and in some cases even perform better. Several cases of false positives and false negatives, that are correctly segmented by this model are also shown. The overall advantages of using the proposed model are two-fold: First, deep neural networks' performance generally improves as more annotated data, or better annotations are provided. Second, such a model can be scaled up to detect other solar events, as well as a single multi-purpose module. The results presented in this study introduce a proof of concept in benefits of employing deep neural networks for detection of solar events, and in particular, filaments.
A Curated Image Parameter Dataset from Solar Dynamics Observatory Mission
Jun 03, 2019


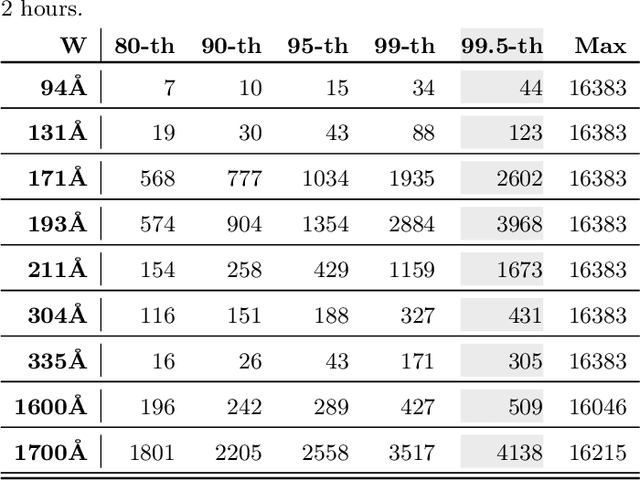
We provide a large image parameter dataset extracted from the Solar Dynamics Observatory (SDO) mission's AIA instrument, for the period of January 2011 through the current date, with the cadence of six minutes, for nine wavelength channels. The volume of the dataset for each year is just short of 1 TiB. Towards achieving better results in the region classification of active regions and coronal holes, we improve upon the performance of a set of ten image parameters, through an in depth evaluation of various assumptions that are necessary for calculation of these image parameters. Then, where possible, a method for finding an appropriate settings for the parameter calculations was devised, as well as a validation task to show our improved results. In addition, we include comparisons of JP2 and FITS image formats using supervised classification models, by tuning the parameters specific to the format of the images from which they are extracted, and specific to each wavelength. The results of these comparisons show that utilizing JP2 images, which are significantly smaller files, is not detrimental to the region classification task that these parameters were originally intended for. Finally, we compute the tuned parameters on the AIA images and provide a public API (http://dmlab.cs.gsu.edu/dmlabapi) to access the dataset. This dataset can be used in a range of studies on AIA images, such as content-based image retrieval or tracking of solar events, where dimensionality reduction on the images is necessary for feasibility of the tasks.