 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSea Ice Extraction via Remote Sensed Imagery: Algorithms, Datasets, Applications and Challenges
Jun 01, 2023The deep learning, which is a dominating technique in artificial intelligence, has completely changed the image understanding over the past decade. As a consequence, the sea ice extraction (SIE) problem has reached a new era. We present a comprehensive review of four important aspects of SIE, including algorithms, datasets, applications, and the future trends. Our review focuses on researches published from 2016 to the present, with a specific focus on deep learning-based approaches in the last five years. We divided all relegated algorithms into 3 categories, including classical image segmentation approach, machine learning-based approach and deep learning-based methods. We reviewed the accessible ice datasets including SAR-based datasets, the optical-based datasets and others. The applications are presented in 4 aspects including climate research, navigation, geographic information systems (GIS) production and others. It also provides insightful observations and inspiring future research directions.
Integrating Multiple Sources Knowledge for Class Asymmetry Domain Adaptation Segmentation of Remote Sensing Images
May 17, 2023



In the existing unsupervised domain adaptation (UDA) methods for remote sensing images (RSIs) semantic segmentation, class symmetry is an widely followed ideal assumption, where the source and target RSIs have exactly the same class space. In practice, however, it is often very difficult to find a source RSI with exactly the same classes as the target RSI. More commonly, there are multiple source RSIs available. To this end, a novel class asymmetry RSIs domain adaptation method with multiple sources is proposed in this paper, which consists of four key components. Firstly, a multi-branch segmentation network is built to learn an expert for each source RSI. Secondly, a novel collaborative learning method with the cross-domain mixing strategy is proposed, to supplement the class information for each source while achieving the domain adaptation of each source-target pair. Thirdly, a pseudo-label generation strategy is proposed to effectively combine strengths of different experts, which can be flexibly applied to two cases where the source class union is equal to or includes the target class set. Fourthly, a multiview-enhanced knowledge integration module is developed for the high-level knowledge routing and transfer from multiple domains to target predictions.
Semi-supervised Road Updating Network : A Deep Learning Method for Road Updating from Remote Sensing Imagery and Historical Vector Maps
Apr 28, 2023



A road is the skeleton of a city and is a fundamental and important geographical component. Currently, many countries have built geo-information databases and gathered large amounts of geographic data. However, with the extensive construction of infrastructure and rapid expansion of cities, automatic updating of road data is imperative to maintain the high quality of current basic geographic information. However, obtaining bi-phase images for the same area is difficult, and complex post-processing methods are required to update the existing databases.To solve these problems, we proposed a road detection method based on semi-supervised learning (SRUNet) specifically for road-updating applications; in this approach, historical road information was fused with the latest images to directly obtain the latest state of the road.Considering that the texture of a road is complex, a multi-branch network, named the Map Encoding Branch (MEB) was proposed for representation learning, where the Boundary Enhancement Module (BEM) was used to improve the accuracy of boundary prediction, and the Residual Refinement Module (RRM) was used to optimize the prediction results. Further, to fully utilize the limited amount of label information and to enhance the prediction accuracy on unlabeled images, we utilized the mean teacher framework as the basic semi-supervised learning framework and introduced Regional Contrast (ReCo) in our work to improve the model capacity for distinguishing between the characteristics of roads and background elements.We applied our method to two datasets. Our model can effectively improve the performance of a model with fewer labels. Overall, the proposed SRUNet can provide stable, up-to-date, and reliable prediction results for a wide range of road renewal tasks.
Attention Aware Cost Volume Pyramid Based Multi-view Stereo Network for 3D Reconstruction
Nov 25, 2020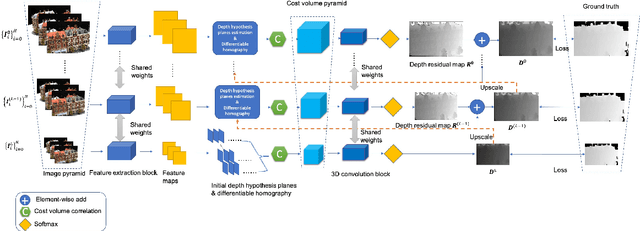
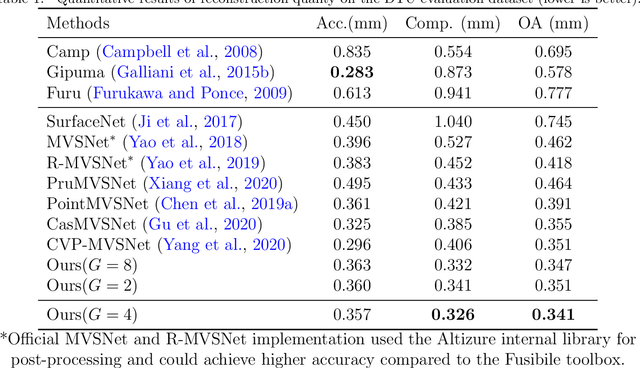
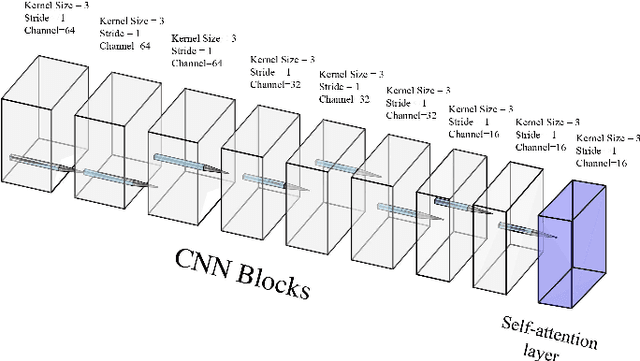

We present an efficient multi-view stereo (MVS) network for 3D reconstruction from multiview images. While previous learning based reconstruction approaches performed quite well, most of them estimate depth maps at a fixed resolution using plane sweep volumes with a fixed depth hypothesis at each plane, which requires densely sampled planes for desired accuracy and therefore is difficult to achieve high resolution depth maps. In this paper we introduce a coarseto-fine depth inference strategy to achieve high resolution depth. This strategy estimates the depth map at coarsest level, while the depth maps at finer levels are considered as the upsampled depth map from previous level with pixel-wise depth residual. Thus, we narrow the depth searching range with priori information from previous level and construct new cost volumes from the pixel-wise depth residual to perform depth map refinement. Then the final depth map could be achieved iteratively since all the parameters are shared between different levels. At each level, the self-attention layer is introduced to the feature extraction block for capturing the long range dependencies for depth inference task, and the cost volume is generated using similarity measurement instead of the variance based methods used in previous work. Experiments were conducted on both the DTU benchmark dataset and recently released BlendedMVS dataset. The results demonstrated that our model could outperform most state-of-the-arts (SOTA) methods. The codebase of this project is at https://github.com/ArthasMil/AACVP-MVSNet.
Active Deep Densely Connected Convolutional Network for Hyperspectral Image Classification
Sep 01, 2020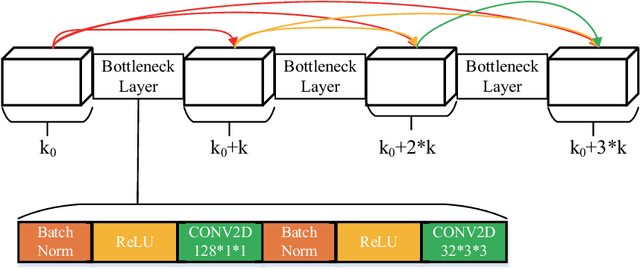

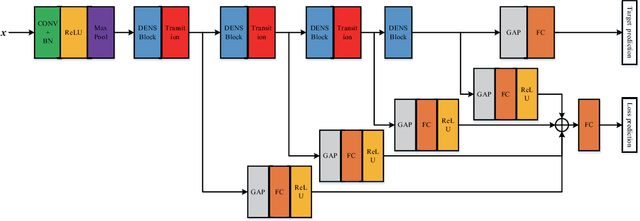
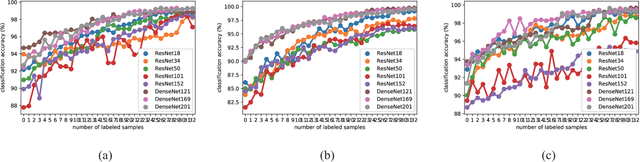
Deep learning based methods have seen a massive rise in popularity for hyperspectral image classification over the past few years. However, the success of deep learning is attributed greatly to numerous labeled samples. It is still very challenging to use only a few labeled samples to train deep learning models to reach a high classification accuracy. An active deep-learning framework trained by an end-to-end manner is, therefore, proposed by this paper in order to minimize the hyperspectral image classification costs. First, a deep densely connected convolutional network is considered for hyperspectral image classification. Different from the traditional active learning methods, an additional network is added to the designed deep densely connected convolutional network to predict the loss of input samples. Then, the additional network could be used to suggest unlabeled samples that the deep densely connected convolutional network is more likely to produce a wrong label. Note that the additional network uses the intermediate features of the deep densely connected convolutional network as input. Therefore, the proposed method is an end-to-end framework. Subsequently, a few of the selected samples are labelled manually and added to the training samples. The deep densely connected convolutional network is therefore trained using the new training set. Finally, the steps above are repeated to train the whole framework iteratively. Extensive experiments illustrates that the method proposed could reach a high accuracy in classification after selecting just a few samples.