 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Multiple Sources Knowledge for Class Asymmetry Domain Adaptation Segmentation of Remote Sensing Images
May 17, 2023



In the existing unsupervised domain adaptation (UDA) methods for remote sensing images (RSIs) semantic segmentation, class symmetry is an widely followed ideal assumption, where the source and target RSIs have exactly the same class space. In practice, however, it is often very difficult to find a source RSI with exactly the same classes as the target RSI. More commonly, there are multiple source RSIs available. To this end, a novel class asymmetry RSIs domain adaptation method with multiple sources is proposed in this paper, which consists of four key components. Firstly, a multi-branch segmentation network is built to learn an expert for each source RSI. Secondly, a novel collaborative learning method with the cross-domain mixing strategy is proposed, to supplement the class information for each source while achieving the domain adaptation of each source-target pair. Thirdly, a pseudo-label generation strategy is proposed to effectively combine strengths of different experts, which can be flexibly applied to two cases where the source class union is equal to or includes the target class set. Fourthly, a multiview-enhanced knowledge integration module is developed for the high-level knowledge routing and transfer from multiple domains to target predictions.
Active Deep Densely Connected Convolutional Network for Hyperspectral Image Classification
Sep 01, 2020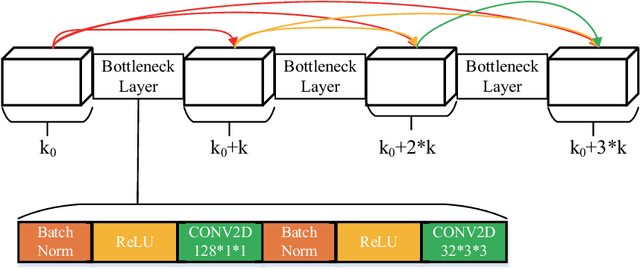

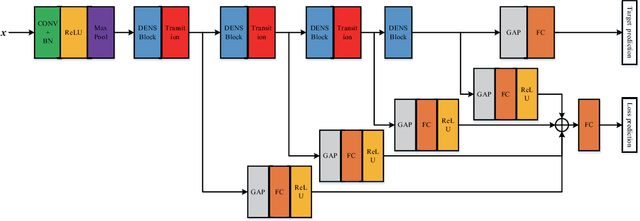
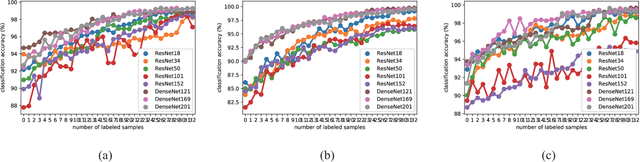
Deep learning based methods have seen a massive rise in popularity for hyperspectral image classification over the past few years. However, the success of deep learning is attributed greatly to numerous labeled samples. It is still very challenging to use only a few labeled samples to train deep learning models to reach a high classification accuracy. An active deep-learning framework trained by an end-to-end manner is, therefore, proposed by this paper in order to minimize the hyperspectral image classification costs. First, a deep densely connected convolutional network is considered for hyperspectral image classification. Different from the traditional active learning methods, an additional network is added to the designed deep densely connected convolutional network to predict the loss of input samples. Then, the additional network could be used to suggest unlabeled samples that the deep densely connected convolutional network is more likely to produce a wrong label. Note that the additional network uses the intermediate features of the deep densely connected convolutional network as input. Therefore, the proposed method is an end-to-end framework. Subsequently, a few of the selected samples are labelled manually and added to the training samples. The deep densely connected convolutional network is therefore trained using the new training set. Finally, the steps above are repeated to train the whole framework iteratively. Extensive experiments illustrates that the method proposed could reach a high accuracy in classification after selecting just a few samples.