 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Aware Cost Volume Pyramid Based Multi-view Stereo Network for 3D Reconstruction
Paper and Code
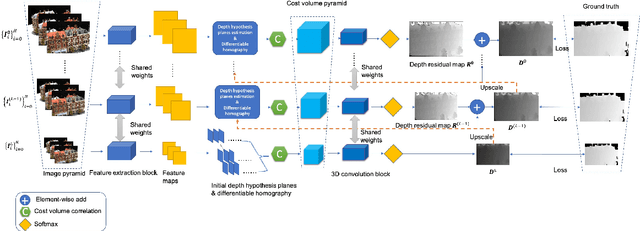
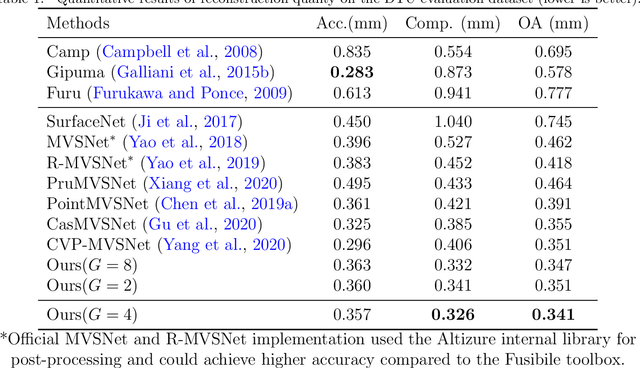
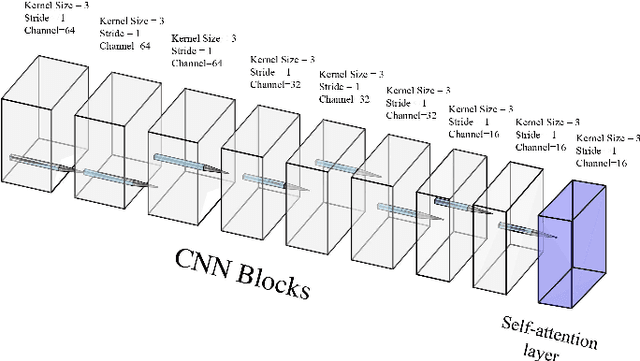

We present an efficient multi-view stereo (MVS) network for 3D reconstruction from multiview images. While previous learning based reconstruction approaches performed quite well, most of them estimate depth maps at a fixed resolution using plane sweep volumes with a fixed depth hypothesis at each plane, which requires densely sampled planes for desired accuracy and therefore is difficult to achieve high resolution depth maps. In this paper we introduce a coarseto-fine depth inference strategy to achieve high resolution depth. This strategy estimates the depth map at coarsest level, while the depth maps at finer levels are considered as the upsampled depth map from previous level with pixel-wise depth residual. Thus, we narrow the depth searching range with priori information from previous level and construct new cost volumes from the pixel-wise depth residual to perform depth map refinement. Then the final depth map could be achieved iteratively since all the parameters are shared between different levels. At each level, the self-attention layer is introduced to the feature extraction block for capturing the long range dependencies for depth inference task, and the cost volume is generated using similarity measurement instead of the variance based methods used in previous work. Experiments were conducted on both the DTU benchmark dataset and recently released BlendedMVS dataset. The results demonstrated that our model could outperform most state-of-the-arts (SOTA) methods. The codebase of this project is at https://github.com/ArthasMil/AACVP-MVSNet.