 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability Due to Training Order in Split Learning
Mar 26, 2021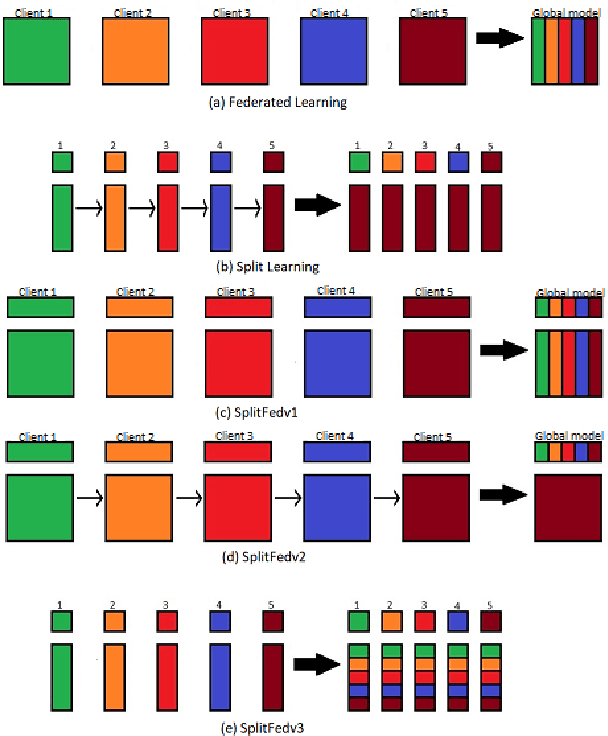
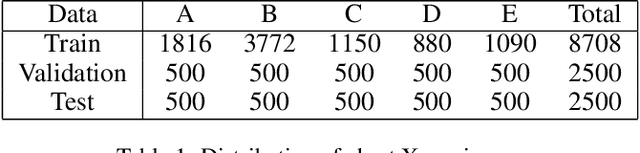
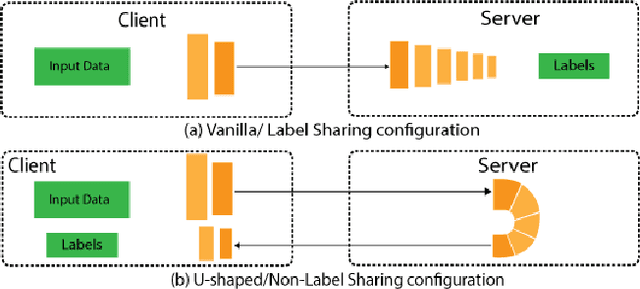
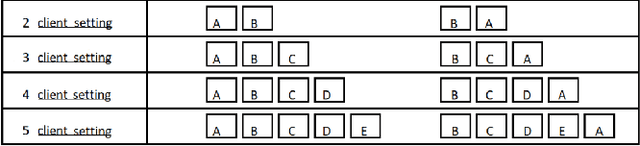
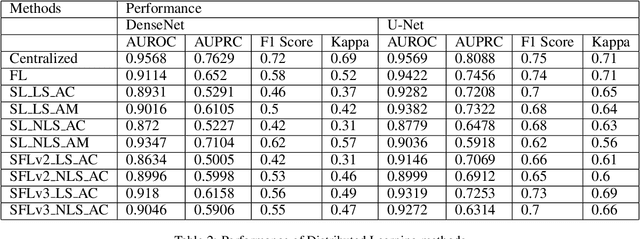
Split learning (SL) is a privacy-preserving distributed deep learning method used to train a collaborative model without the need for sharing of patient's raw data between clients. In split learning, an additional privacy-preserving algorithm called no-peek algorithm can be incorporated, which is robust to adversarial attacks. The privacy benefits offered by split learning make it suitable for practice in the healthcare domain. However, the split learning algorithm is flawed as the collaborative model is trained sequentially, i.e., one client trains after the other. We point out that the model trained using the split learning algorithm gets biased towards the data of the clients used for training towards the end of a round. This makes SL algorithms highly susceptible to the order in which clients are considered for training. We demonstrate that the model trained using the data of all clients does not perform well on the client's data which was considered earliest in a round for training the model. Moreover, we show that this effect becomes more prominent with the increase in the number of clients. We also demonstrate that the SplitFedv3 algorithm mitigates this problem while still leveraging the privacy benefits provided by split learning.
Reducing Labelled Data Requirement for Pneumonia Segmentation using Image Augmentations
Feb 25, 2021
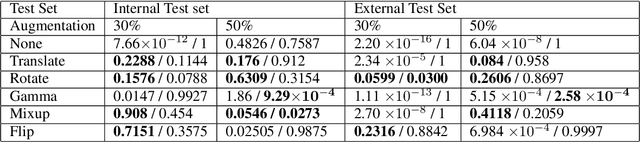
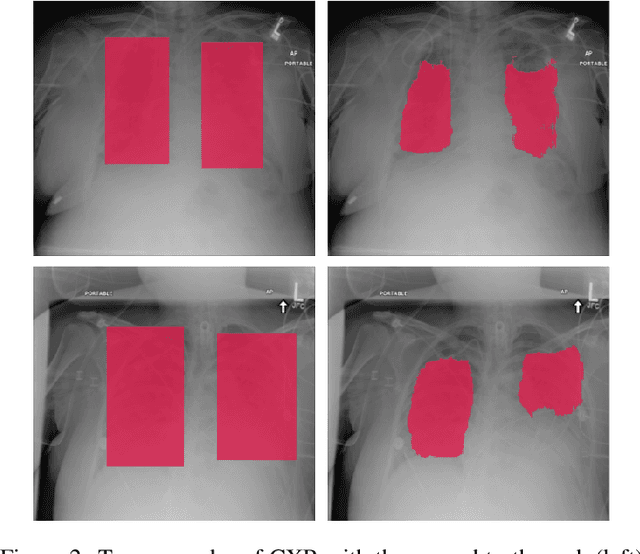
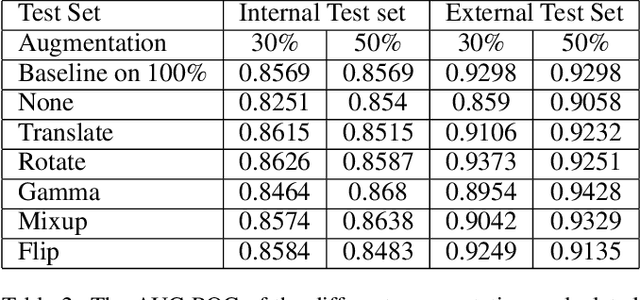
Deep learning semantic segmentation algorithms can localise abnormalities or opacities from chest radiographs. However, the task of collecting and annotating training data is expensive and requires expertise which remains a bottleneck for algorithm performance. We investigate the effect of image augmentations on reducing the requirement of labelled data in the semantic segmentation of chest X-rays for pneumonia detection. We train fully convolutional network models on subsets of different sizes from the total training data. We apply a different image augmentation while training each model and compare it to the baseline trained on the entire dataset without augmentations. We find that rotate and mixup are the best augmentations amongst rotate, mixup, translate, gamma and horizontal flip, wherein they reduce the labelled data requirement by 70% while performing comparably to the baseline in terms of AUC and mean IoU in our experiments.
Comparative Evaluation of 3D and 2D Deep Learning Techniques for Semantic Segmentation in CT Scans
Jan 19, 2021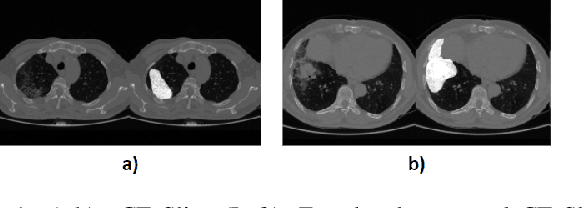

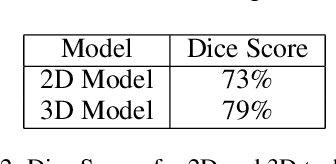
Image segmentation plays a pivotal role in several medical-imaging applications by assisting the segmentation of the regions of interest. Deep learning-based approaches have been widely adopted for semantic segmentation of medical data. In recent years, in addition to 2D deep learning architectures, 3D architectures have been employed as the predictive algorithms for 3D medical image data. In this paper, we propose a 3D stack-based deep learning technique for segmenting manifestations of consolidation and ground-glass opacities in 3D Computed Tomography (CT) scans. We also present a comparison based on the segmentation results, the contextual information retained, and the inference time between this 3D technique and a traditional 2D deep learning technique. We also define the area-plot, which represents the peculiar pattern observed in the slice-wise areas of the pathology regions predicted by these deep learning models. In our exhaustive evaluation, 3D technique performs better than the 2D technique for the segmentation of CT scans. We get dice scores of 79% and 73% for the 3D and the 2D techniques respectively. The 3D technique results in a 5X reduction in the inference time compared to the 2D technique. Results also show that the area-plots predicted by the 3D model are more similar to the ground truth than those predicted by the 2D model. We also show how increasing the amount of contextual information retained during the training can improve the 3D model's performance.
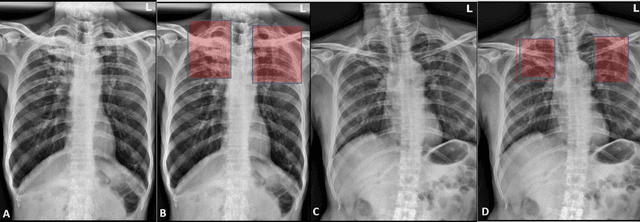
Deep Learning Models for Calculation of Cardiothoracic Ratio from Chest Radiographs for Assisted Diagnosis of Cardiomegaly
Jan 19, 2021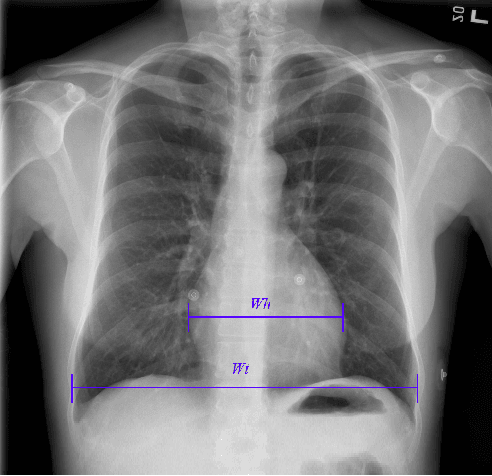
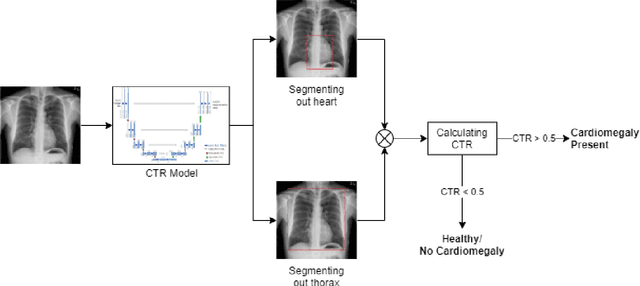
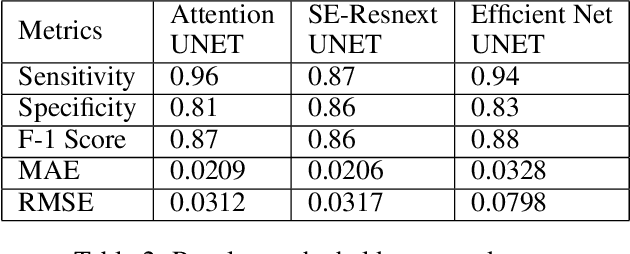
We propose an automated method based on deep learning to compute the cardiothoracic ratio and detect the presence of cardiomegaly from chest radiographs. We develop two separate models to demarcate the heart and chest regions in an X-ray image using bounding boxes and use their outputs to calculate the cardiothoracic ratio. We obtain a sensitivity of 0.96 at a specificity of 0.81 with a mean absolute error of 0.0209 on a held-out test dataset and a sensitivity of 0.84 at a specificity of 0.97 with a mean absolute error of 0.018 on an independent dataset from a different hospital. We also compare three different segmentation model architectures for the proposed method and observe that Attention U-Net yields better results than SE-Resnext U-Net and EfficientNet U-Net. By providing a numeric measurement of the cardiothoracic ratio, we hope to mitigate human subjectivity arising out of visual assessment in the detection of cardiomegaly.
Comparison of Privacy-Preserving Distributed Deep Learning Methods in Healthcare
Dec 23, 2020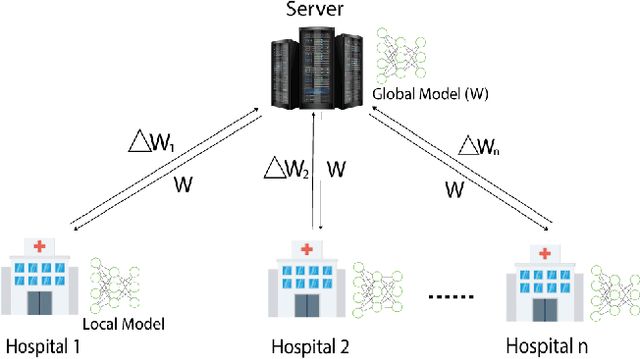
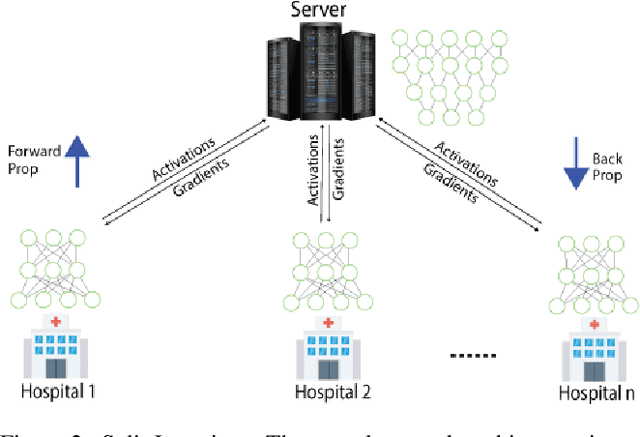
In this paper, we compare three privacy-preserving distributed learning techniques: federated learning, split learning, and SplitFed. We use these techniques to develop binary classification models for detecting tuberculosis from chest X-rays and compare them in terms of classification performance, communication and computational costs, and training time. We propose a novel distributed learning architecture called SplitFedv3, which performs better than split learning and SplitFedv2 in our experiments. We also propose alternate mini-batch training, a new training technique for split learning, that performs better than alternate client training, where clients take turns to train a model.
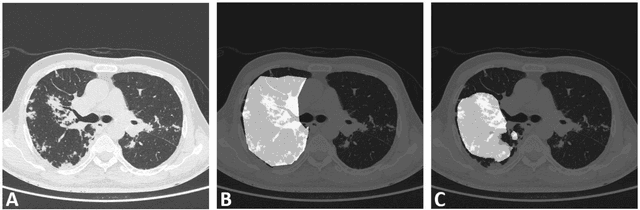
Automated Detection of COVID-19 from CT Scans Using Convolutional Neural Networks
Jun 23, 2020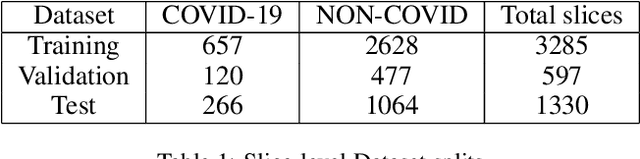
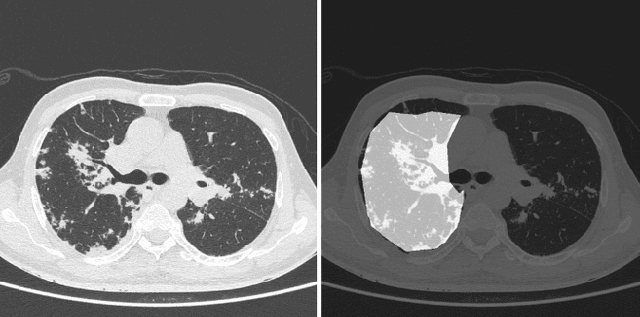
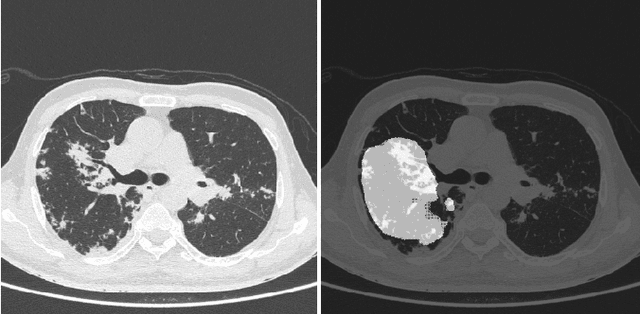
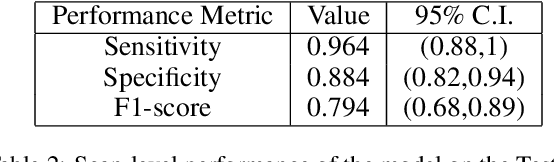
COVID-19 is an infectious disease that causes respiratory problems similar to those caused by SARS-CoV (2003). Currently, swab samples are being used for its diagnosis. The most common testing method used is the RT-PCR method, which has high specificity but variable sensitivity. AI-based detection has the capability to overcome this drawback. In this paper, we propose a prospective method wherein we use chest CT scans to diagnose the patients for COVID-19 pneumonia. We use a set of open-source images, available as individual CT slices, and full CT scans from a private Indian Hospital to train our model. We build a 2D segmentation model using the U-Net architecture, which gives the output by marking out the region of infection. Our model achieves a sensitivity of 96.428% (95% CI: 88%-100%) and a specificity of 88.39% (95% CI: 82%-94%). Additionally, we derive a logic for converting our slice-level predictions to scan-level, which helps us reduce the false positives.
Quantum Computing Methods for Supervised Learning
Jun 22, 2020
The last two decades have seen an explosive growth in the theory and practice of both quantum computing and machine learning. Modern machine learning systems process huge volumes of data and demand massive computational power. As silicon semiconductor miniaturization approaches its physics limits, quantum computing is increasingly being considered to cater to these computational needs in the future. Small-scale quantum computers and quantum annealers have been built and are already being sold commercially. Quantum computers can benefit machine learning research and application across all science and engineering domains. However, owing to its roots in quantum mechanics, research in this field has so far been confined within the purview of the physics community, and most work is not easily accessible to researchers from other disciplines. In this paper, we provide a background and summarize key results of quantum computing before exploring its application to supervised machine learning problems. By eschewing results from physics that have little bearing on quantum computation, we hope to make this introduction accessible to data scientists, machine learning practitioners, and researchers from across disciplines.
Role of Edge Device and Cloud Machine Learning in Point-of-Care Solutions Using Imaging Diagnostics for Population Screening
Jun 18, 2020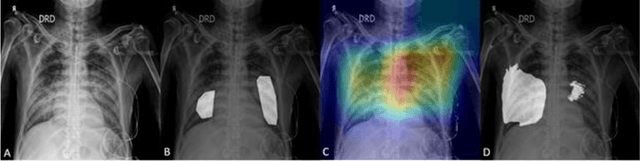
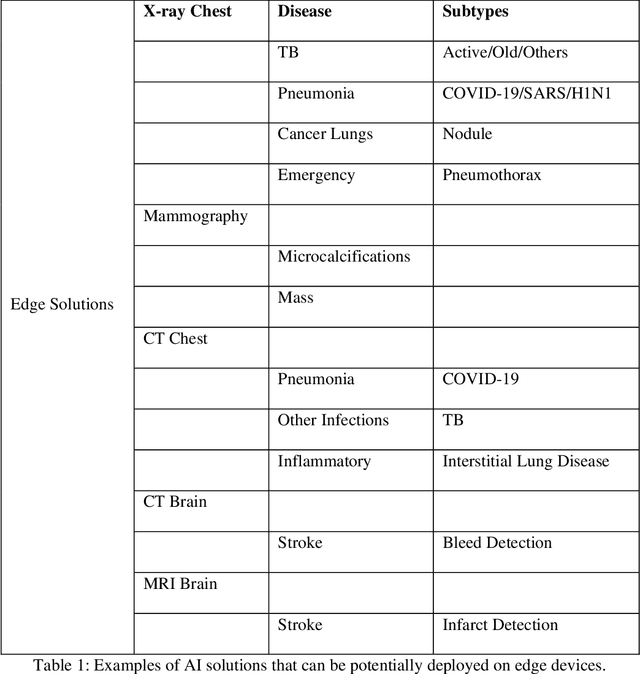
Edge devices are revolutionizing diagnostics. Edge devices can reside within or adjacent to imaging tools such as digital Xray, CT, MRI, or ultrasound equipment. These devices are either CPUs or GPUs with advanced processing deep and machine learning (artificial intelligence) algorithms that assist in classification and triage solutions to flag studies as either normal or abnormal, TB or healthy (in case of TB screening), suspected COVID-19/other pneumonia or unremarkable (in hospital or hotspot settings). These can be deployed as screening point-of-care (PoC) solutions; this is particularly true for digital and portable X-ray devices. Edge device learning can also be used for mammography and CT studies where it can identify microcalcification and stroke, respectively. These solutions can be considered the first line of pre-screening before the imaging specialist actually reviews scans and makes a final diagnosis. The key advantage of these tools is that they are instant, can be deployed remotely where experts are not available to perform pre-screening before the experts actually review, and are not limited by internet bandwidth as the nano learning data centers are placed next to the device.
Automatic Grading of Knee Osteoarthritis on the Kellgren-Lawrence Scale from Radiographs Using Convolutional Neural Networks
Apr 18, 2020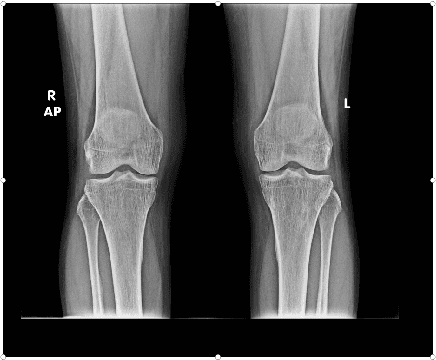

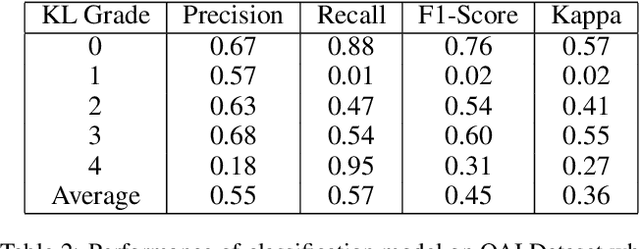
The severity of knee osteoarthritis is graded using the 5-point Kellgren-Lawrence (KL) scale where healthy knees are assigned grade 0, and the subsequent grades 1-4 represent increasing severity of the affliction. Although several methods have been proposed in recent years to develop models that can automatically predict the KL grade from a given radiograph, most models have been developed and evaluated on datasets not sourced from India. These models fail to perform well on the radiographs of Indian patients. In this paper, we propose a novel method using convolutional neural networks to automatically grade knee radiographs on the KL scale. Our method works in two connected stages: in the first stage, an object detection model segments individual knees from the rest of the image; in the second stage, a regression model automatically grades each knee separately on the KL scale. We train our model using the publicly available Osteoarthritis Initiative (OAI) dataset and demonstrate that fine-tuning the model before evaluating it on a dataset from a private hospital significantly improves the mean absolute error from 1.09 (95% CI: 1.03-1.15) to 0.28 (95% CI: 0.25-0.32). Additionally, we compare classification and regression models built for the same task and demonstrate that regression outperforms classification.
Survey of Personalization Techniques for Federated Learning
Mar 19, 2020Federated learning enables machine learning models to learn from private decentralized data without compromising privacy. The standard formulation of federated learning produces one shared model for all clients. Statistical heterogeneity due to non-IID distribution of data across devices often leads to scenarios where, for some clients, the local models trained solely on their private data perform better than the global shared model thus taking away their incentive to participate in the process. Several techniques have been proposed to personalize global models to work better for individual clients. This paper highlights the need for personalization and surveys recent research on this topic.