 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability Due to Training Order in Split Learning
Paper and Code
Mar 26, 2021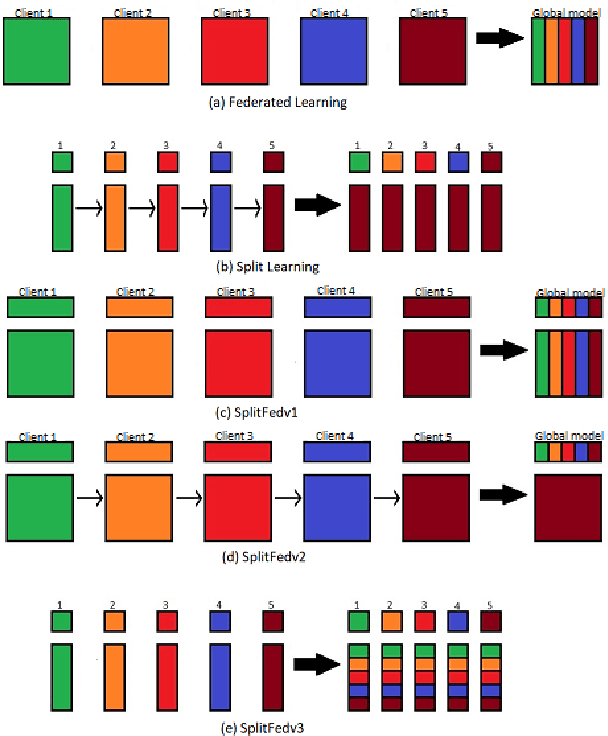
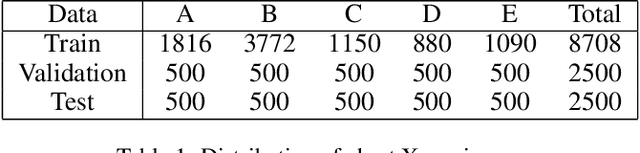
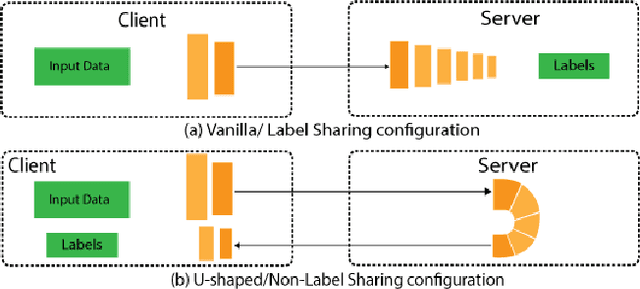
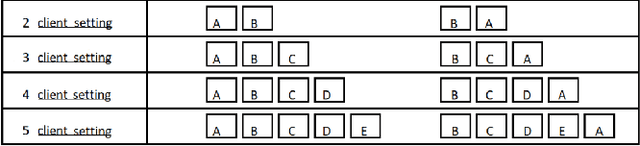
Split learning (SL) is a privacy-preserving distributed deep learning method used to train a collaborative model without the need for sharing of patient's raw data between clients. In split learning, an additional privacy-preserving algorithm called no-peek algorithm can be incorporated, which is robust to adversarial attacks. The privacy benefits offered by split learning make it suitable for practice in the healthcare domain. However, the split learning algorithm is flawed as the collaborative model is trained sequentially, i.e., one client trains after the other. We point out that the model trained using the split learning algorithm gets biased towards the data of the clients used for training towards the end of a round. This makes SL algorithms highly susceptible to the order in which clients are considered for training. We demonstrate that the model trained using the data of all clients does not perform well on the client's data which was considered earliest in a round for training the model. Moreover, we show that this effect becomes more prominent with the increase in the number of clients. We also demonstrate that the SplitFedv3 algorithm mitigates this problem while still leveraging the privacy benefits provided by split learning.