 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Federated Learning in Building a Robust COVID-19 Chest X-ray Classification Model
Apr 22, 2022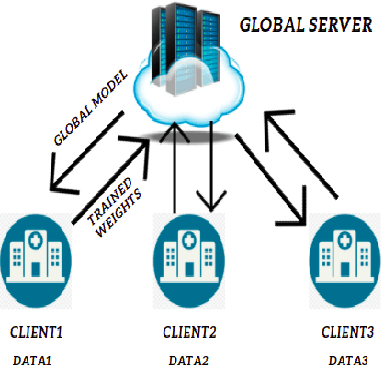
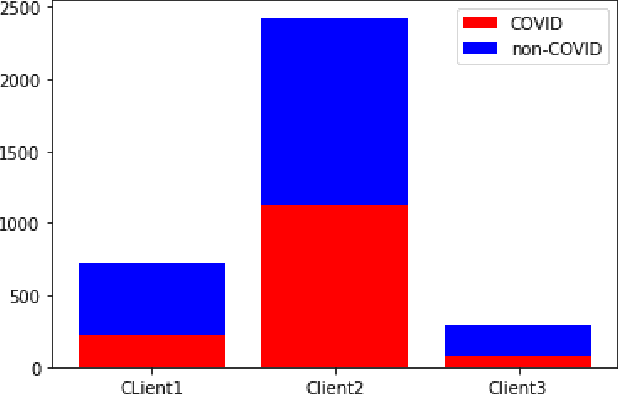
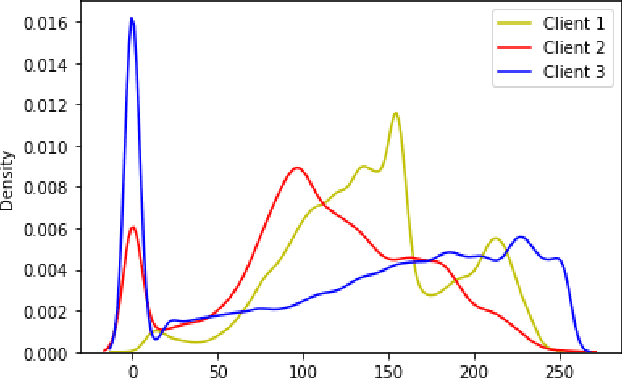
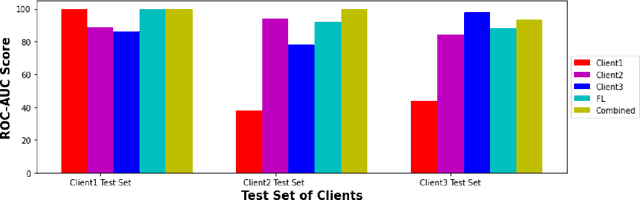
While developing artificial intelligence (AI)-based algorithms to solve problems, the amount of data plays a pivotal role - large amount of data helps the researchers and engineers to develop robust AI algorithms. In the case of building AI-based models for problems related to medical imaging, these data need to be transferred from the medical institutions where they were acquired to the organizations developing the algorithms. This movement of data involves time-consuming formalities like complying with HIPAA, GDPR, etc.There is also a risk of patients' private data getting leaked, compromising their confidentiality. One solution to these problems is using the Federated Learning framework. Federated Learning (FL) helps AI models to generalize better and create a robust AI model by using data from different sources having different distributions and data characteristics without moving all the data to a central server. In our paper, we apply the FL framework for training a deep learning model to solve a binary classification problem of predicting the presence or absence of COVID-19. We took three different sources of data and trained individual models on each source. Then we trained an FL model on the complete data and compared all the model performances. We demonstrated that the FL model performs better than the individual models. Moreover, the FL model performed at par with the model trained on all the data combined at a central server. Thus Federated Learning leads to generalized AI models without the cost of data transfer and regulatory overhead.
Reducing Labelled Data Requirement for Pneumonia Segmentation using Image Augmentations
Feb 25, 2021
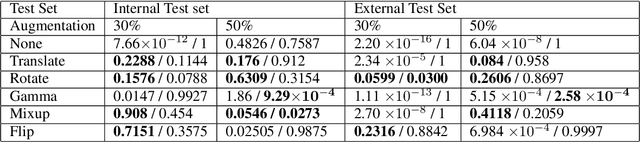
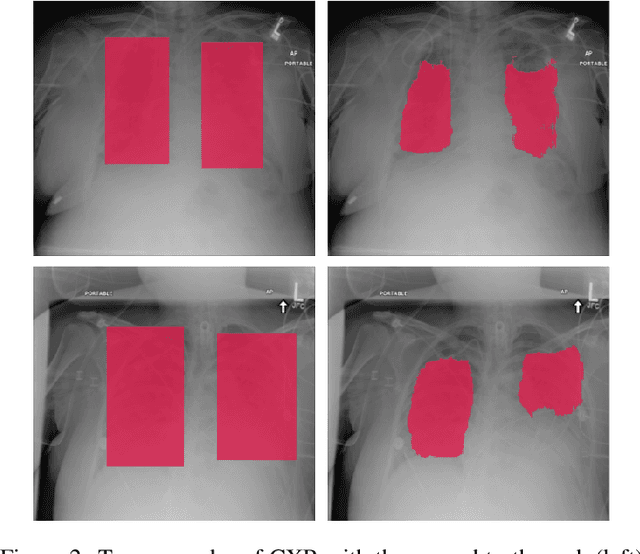
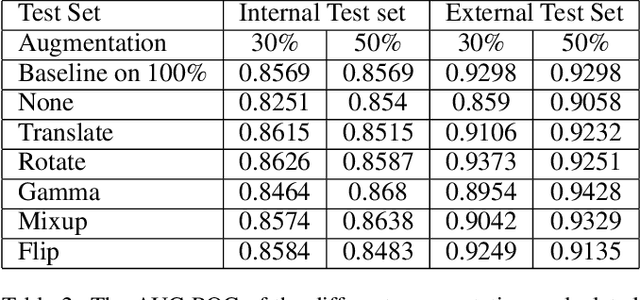
Deep learning semantic segmentation algorithms can localise abnormalities or opacities from chest radiographs. However, the task of collecting and annotating training data is expensive and requires expertise which remains a bottleneck for algorithm performance. We investigate the effect of image augmentations on reducing the requirement of labelled data in the semantic segmentation of chest X-rays for pneumonia detection. We train fully convolutional network models on subsets of different sizes from the total training data. We apply a different image augmentation while training each model and compare it to the baseline trained on the entire dataset without augmentations. We find that rotate and mixup are the best augmentations amongst rotate, mixup, translate, gamma and horizontal flip, wherein they reduce the labelled data requirement by 70% while performing comparably to the baseline in terms of AUC and mean IoU in our experiments.