 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAgain: A Trust-Based and Robust Federated Learning Strategy for an Automated Kidney Stone Identification in Ureteroscopy
Mar 19, 2026The reliability of artificial intelligence (AI) in medical imaging critically depends on its robustness to heterogeneous and corrupted images acquired with diverse devices across different hospitals which is highly challenging. Therefore, this paper introduces FedAgain, a trust-based Federated Learning (Federated Learning) strategy designed to enhance robustness and generalization for automated kidney stone identification from endoscopic images. FedAgain integrates a dual trust mechanism that combines benchmark reliability and model divergence to dynamically weight client contributions, mitigating the impact of noisy or adversarial updates during aggregation. The framework enables the training of collaborative models across multiple institutions while preserving data privacy and promoting stable convergence under real-world conditions. Extensive experiments across five datasets, including two canonical benchmarks (MNIST and CIFAR-10), two private multi-institutional kidney stone datasets, and one public dataset (MyStone), demonstrate that FedAgain consistently outperforms standard Federated Learning baselines under non-identically and independently distributed (non-IID) data and corrupted-client scenarios. By maintaining diagnostic accuracy and performance stability under varying conditions, FedAgain represents a practical advance toward reliable, privacy-preserving, and clinically deployable federated AI for medical imaging.
EndoDepth: A Benchmark for Assessing Robustness in Endoscopic Depth Prediction
Sep 30, 2024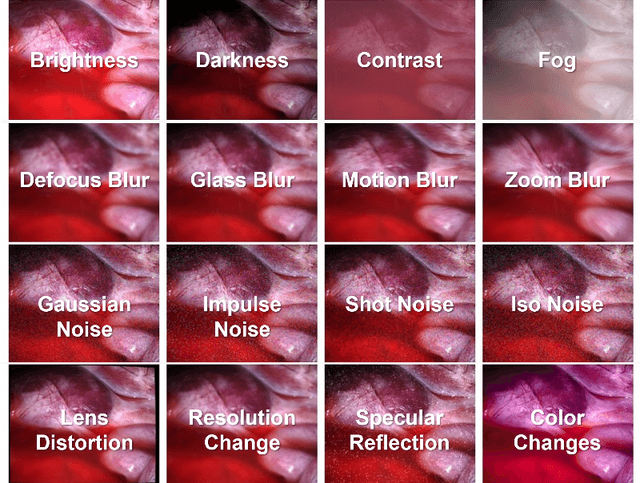
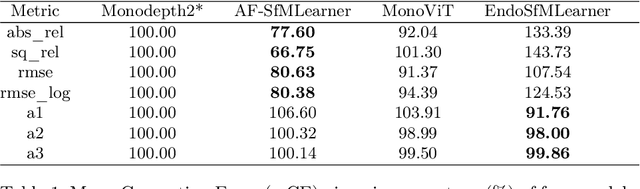

Accurate depth estimation in endoscopy is vital for successfully implementing computer vision pipelines for various medical procedures and CAD tools. In this paper, we present the EndoDepth benchmark, an evaluation framework designed to assess the robustness of monocular depth prediction models in endoscopic scenarios. Unlike traditional datasets, the EndoDepth benchmark incorporates common challenges encountered during endoscopic procedures. We present an evaluation approach that is consistent and specifically designed to evaluate the robustness performance of the model in endoscopic scenarios. Among these is a novel composite metric called the mean Depth Estimation Robustness Score (mDERS), which offers an in-depth evaluation of a model's accuracy against errors brought on by endoscopic image corruptions. Moreover, we present SCARED-C, a new dataset designed specifically to assess endoscopy robustness. Through extensive experimentation, we evaluate state-of-the-art depth prediction architectures on the EndoDepth benchmark, revealing their strengths and weaknesses in handling endoscopic challenging imaging artifacts. Our results demonstrate the importance of specialized techniques for accurate depth estimation in endoscopy and provide valuable insights for future research directions.
Leveraging Pre-trained Models for Robust Federated Learning for Kidney Stone Type Recognition
Sep 30, 2024
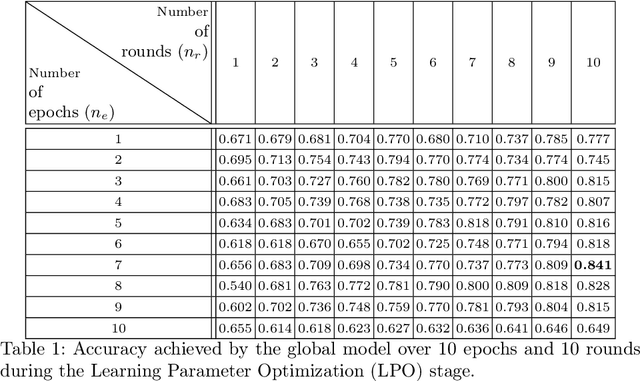
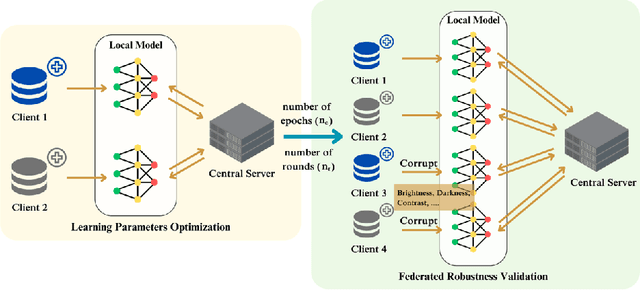

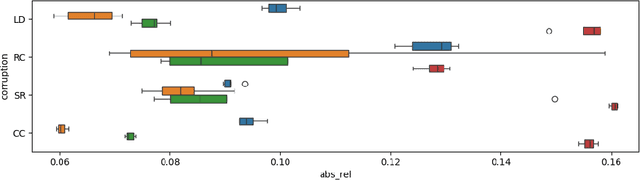
Deep learning developments have improved medical imaging diagnoses dramatically, increasing accuracy in several domains. Nonetheless, obstacles continue to exist because of the requirement for huge datasets and legal limitations on data exchange. A solution is provided by Federated Learning (FL), which permits decentralized model training while maintaining data privacy. However, FL models are susceptible to data corruption, which may result in performance degradation. Using pre-trained models, this research suggests a strong FL framework to improve kidney stone diagnosis. Two different kidney stone datasets, each with six different categories of images, are used in our experimental setting. Our method involves two stages: Learning Parameter Optimization (LPO) and Federated Robustness Validation (FRV). We achieved a peak accuracy of 84.1% with seven epochs and 10 rounds during LPO stage, and 77.2% during FRV stage, showing enhanced diagnostic accuracy and robustness against image corruption. This highlights the potential of merging pre-trained models with FL to address privacy and performance concerns in medical diagnostics, and guarantees improved patient care and enhanced trust in FL-based medical systems.
Configuration Interaction Guided Sampling with Interpretable Restricted Boltzmann Machine
Sep 10, 2024We propose a data-driven approach using a Restricted Boltzmann Machine (RBM) to solve the Schr\"odinger equation in configuration space. Traditional Configuration Interaction (CI) methods, while powerful, are computationally expensive due to the large number of determinants required. Our approach leverages RBMs to efficiently identify and sample the most significant determinants, accelerating convergence and reducing computational cost. This method achieves up to 99.99\% of the correlation energy even by four orders of magnitude less determinants compared to full CI calculations and up to two orders of magnitude less than previous state of the art works. Additionally, our study demonstrate that the RBM can learn the underlying quantum properties, providing more detail insights than other methods . This innovative data-driven approach offers a promising tool for quantum chemistry, enhancing both efficiency and understanding of complex systems.
Fourier Series Guided Design of Quantum Convolutional Neural Networks for Enhanced Time Series Forecasting
Apr 25, 2024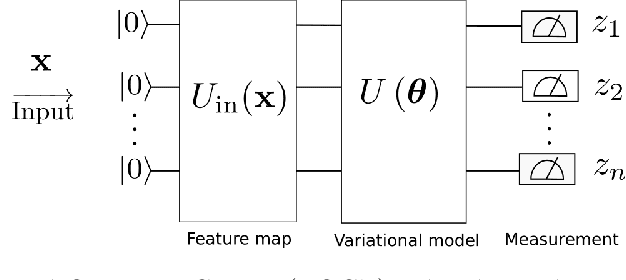
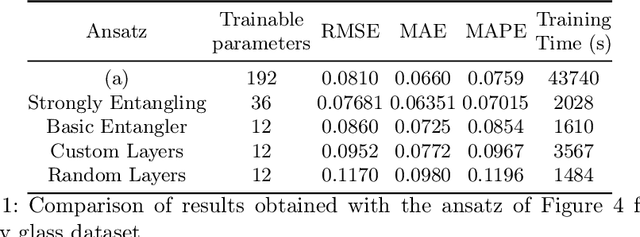
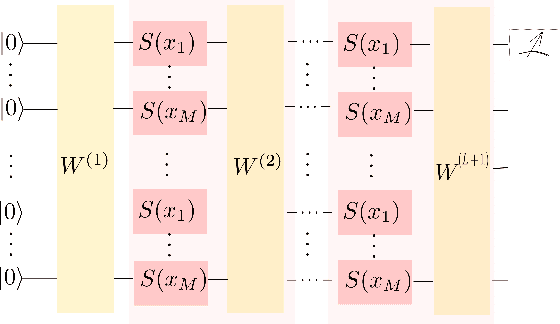
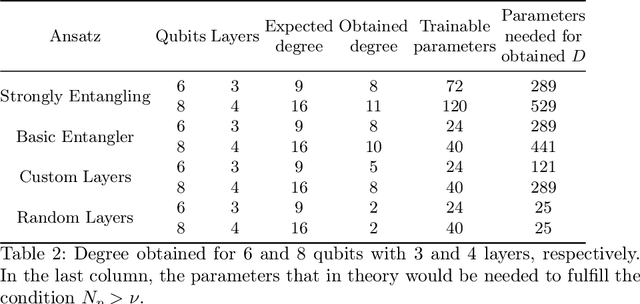
In this study, we apply 1D quantum convolution to address the task of time series forecasting. By encoding multiple points into the quantum circuit to predict subsequent data, each point becomes a feature, transforming the problem into a multidimensional one. Building on theoretical foundations from prior research, which demonstrated that Variational Quantum Circuits (VQCs) can be expressed as multidimensional Fourier series, we explore the capabilities of different architectures and ansatz. This analysis considers the concepts of circuit expressibility and the presence of barren plateaus. Analyzing the problem within the framework of the Fourier series enabled the design of an architecture that incorporates data reuploading, resulting in enhanced performance. Rather than a strict requirement for the number of free parameters to exceed the degrees of freedom of the Fourier series, our findings suggest that even a limited number of parameters can produce Fourier functions of higher degrees. This highlights the remarkable expressive power of quantum circuits. This observation is also significant in reducing training times. The ansatz with greater expressibility and number of non-zero Fourier coefficients consistently delivers favorable results across different scenarios, with performance metrics improving as the number of qubits increases.
A metric learning approach for endoscopic kidney stone identification
Jul 13, 2023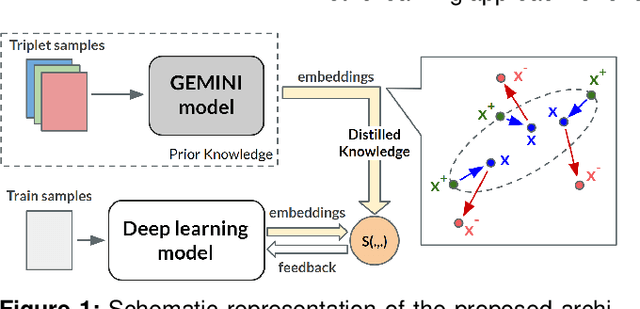
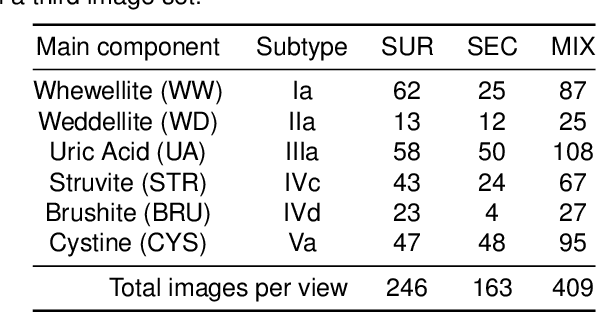
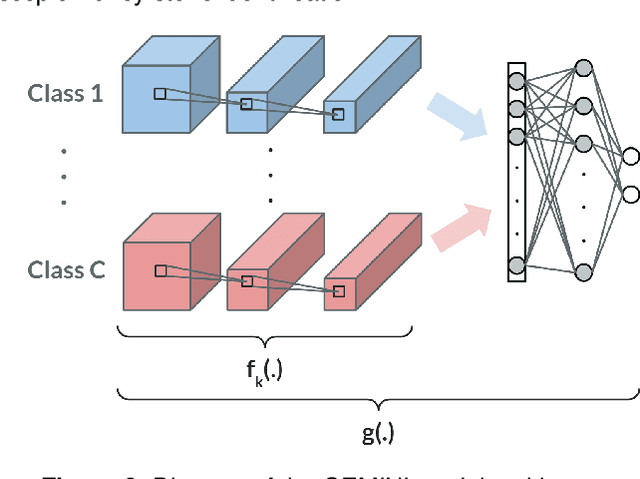
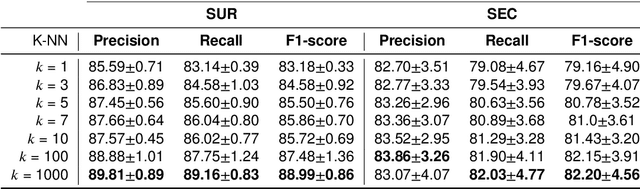
Several Deep Learning (DL) methods have recently been proposed for an automated identification of kidney stones during an ureteroscopy to enable rapid therapeutic decisions. Even if these DL approaches led to promising results, they are mainly appropriate for kidney stone types for which numerous labelled data are available. However, only few labelled images are available for some rare kidney stone types. This contribution exploits Deep Metric Learning (DML) methods i) to handle such classes with few samples, ii) to generalize well to out of distribution samples, and iii) to cope better with new classes which are added to the database. The proposed Guided Deep Metric Learning approach is based on a novel architecture which was designed to learn data representations in an improved way. The solution was inspired by Few-Shot Learning (FSL) and makes use of a teacher-student approach. The teacher model (GEMINI) generates a reduced hypothesis space based on prior knowledge from the labeled data, and is used it as a guide to a student model (i.e., ResNet50) through a Knowledge Distillation scheme. Extensive tests were first performed on two datasets separately used for the recognition, namely a set of images acquired for the surfaces of the kidney stone fragments, and a set of images of the fragment sections. The proposed DML-approach improved the identification accuracy by 10% and 12% in comparison to DL-methods and other DML-approaches, respectively. Moreover, model embeddings from the two dataset types were merged in an organized way through a multi-view scheme to simultaneously exploit the information of surface and section fragments. Test with the resulting mixed model improves the identification accuracy by at least 3% and up to 30% with respect to DL-models and shallow machine learning methods, respectively.
SuSana Distancia is all you need: Enforcing class separability in metric learning via two novel distance-based loss functions for few-shot image classification
May 18, 2023Few-shot learning is a challenging area of research that aims to learn new concepts with only a few labeled samples of data. Recent works based on metric-learning approaches leverage the meta-learning approach, which is encompassed by episodic tasks that make use a support (training) and query set (test) with the objective of learning a similarity comparison metric between those sets. Due to the lack of data, the learning process of the embedding network becomes an important part of the few-shot task. Previous works have addressed this problem using metric learning approaches, but the properties of the underlying latent space and the separability of the difference classes on it was not entirely enforced. In this work, we propose two different loss functions which consider the importance of the embedding vectors by looking at the intra-class and inter-class distance between the few data. The first loss function is the Proto-Triplet Loss, which is based on the original triplet loss with the modifications needed to better work on few-shot scenarios. The second loss function, which we dub ICNN loss is based on an inter and intra class nearest neighbors score, which help us to assess the quality of embeddings obtained from the trained network. Our results, obtained from a extensive experimental setup show a significant improvement in accuracy in the miniImagenNet benchmark compared to other metric-based few-shot learning methods by a margin of 2%, demonstrating the capability of these loss functions to allow the network to generalize better to previously unseen classes. In our experiments, we demonstrate competitive generalization capabilities to other domains, such as the Caltech CUB, Dogs and Cars datasets compared with the state of the art.
CoShNet: A Hybird Complex Valued Neural Network using Shearlets
Aug 14, 2022

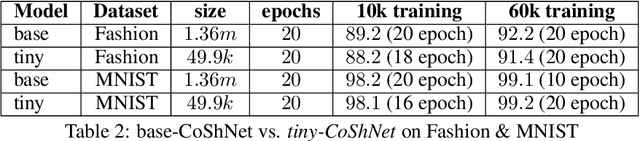
In a hybrid neural network, the expensive convolutional layers are replaced by a non-trainable fixed transform with a great reduction in parameters. In previous works, good results were obtained by replacing the convolutions with wavelets. However, wavelet based hybrid network inherited wavelet's lack of vanishing moments along curves and its axis-bias. We propose to use Shearlets with its robust support for important image features like edges, ridges and blobs. The resulting network is called Complex Shearlets Network (CoShNet). It was tested on Fashion-MNIST against ResNet-50 and Resnet-18, obtaining 92.2% versus 90.7% and 91.8% respectively. The proposed network has 49.9k parameters versus ResNet-18 with 11.18m and use 52 times fewer FLOPs. Finally, we trained in under 20 epochs versus 200 epochs required by ResNet and do not need any hyperparameter tuning nor regularization. Code: https://github.com/Ujjawal-K-Panchal/coshnet
MACFE: A Meta-learning and Causality Based Feature Engineering Framework
Jul 08, 2022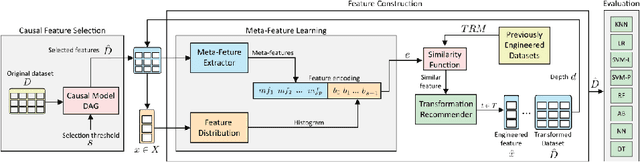
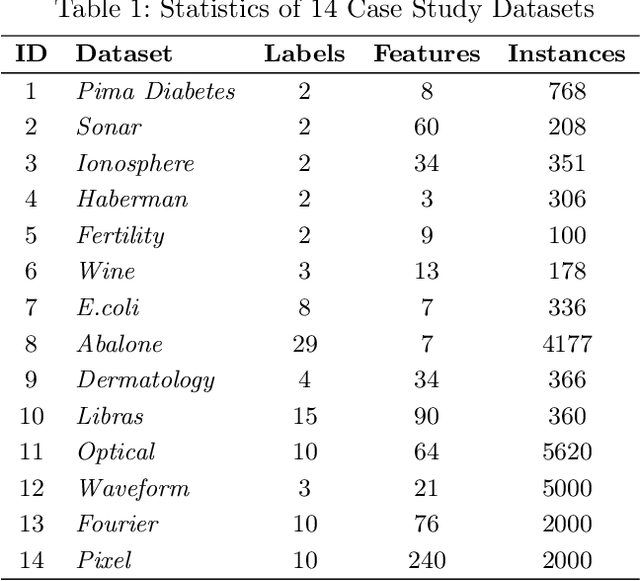

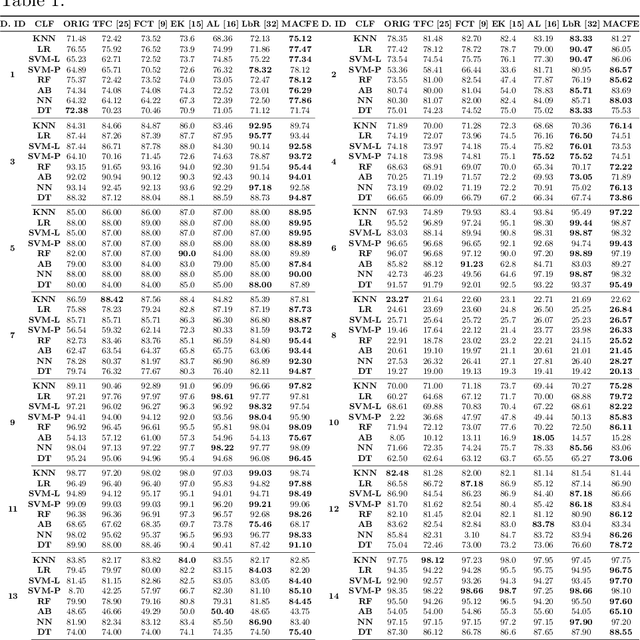
Feature engineering has become one of the most important steps to improve model prediction performance, and to produce quality datasets. However, this process requires non-trivial domain-knowledge which involves a time-consuming process. Thereby, automating such process has become an active area of research and of interest in industrial applications. In this paper, a novel method, called Meta-learning and Causality Based Feature Engineering (MACFE), is proposed; our method is based on the use of meta-learning, feature distribution encoding, and causality feature selection. In MACFE, meta-learning is used to find the best transformations, then the search is accelerated by pre-selecting "original" features given their causal relevance. Experimental evaluations on popular classification datasets show that MACFE can improve the prediction performance across eight classifiers, outperforms the current state-of-the-art methods in average by at least 6.54%, and obtains an improvement of 2.71% over the best previous works.
Guided Deep Metric Learning
Jun 04, 2022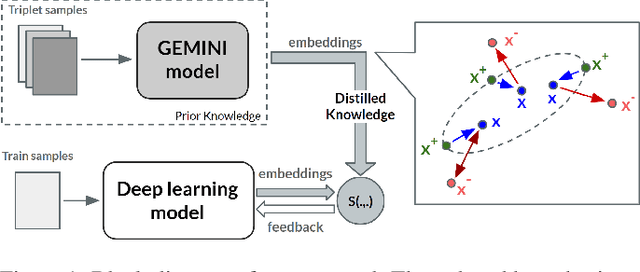
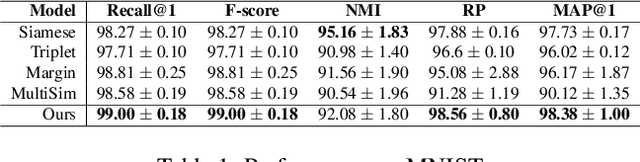
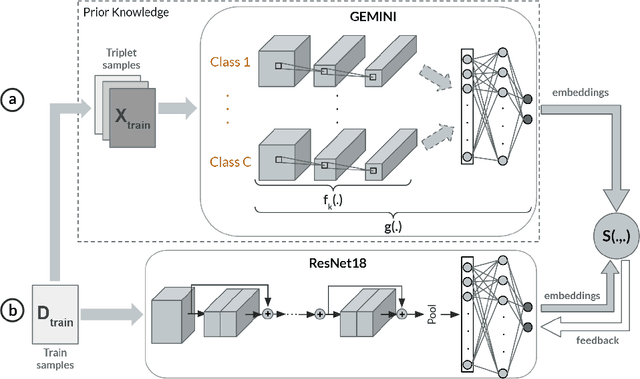

Deep Metric Learning (DML) methods have been proven relevant for visual similarity learning. However, they sometimes lack generalization properties because they are trained often using an inappropriate sample selection strategy or due to the difficulty of the dataset caused by a distributional shift in the data. These represent a significant drawback when attempting to learn the underlying data manifold. Therefore, there is a pressing need to develop better ways of obtaining generalization and representation of the underlying manifold. In this paper, we propose a novel approach to DML that we call Guided Deep Metric Learning, a novel architecture oriented to learning more compact clusters, improving generalization under distributional shifts in DML. This novel architecture consists of two independent models: A multi-branch master model, inspired from a Few-Shot Learning (FSL) perspective, generates a reduced hypothesis space based on prior knowledge from labeled data, which guides or regularizes the decision boundary of a student model during training under an offline knowledge distillation scheme. Experiments have shown that the proposed method is capable of a better manifold generalization and representation to up to 40% improvement (Recall@1, CIFAR10), using guidelines suggested by Musgrave et al. to perform a more fair and realistic comparison, which is currently absent in the literature