 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuSana Distancia is all you need: Enforcing class separability in metric learning via two novel distance-based loss functions for few-shot image classification
May 18, 2023Few-shot learning is a challenging area of research that aims to learn new concepts with only a few labeled samples of data. Recent works based on metric-learning approaches leverage the meta-learning approach, which is encompassed by episodic tasks that make use a support (training) and query set (test) with the objective of learning a similarity comparison metric between those sets. Due to the lack of data, the learning process of the embedding network becomes an important part of the few-shot task. Previous works have addressed this problem using metric learning approaches, but the properties of the underlying latent space and the separability of the difference classes on it was not entirely enforced. In this work, we propose two different loss functions which consider the importance of the embedding vectors by looking at the intra-class and inter-class distance between the few data. The first loss function is the Proto-Triplet Loss, which is based on the original triplet loss with the modifications needed to better work on few-shot scenarios. The second loss function, which we dub ICNN loss is based on an inter and intra class nearest neighbors score, which help us to assess the quality of embeddings obtained from the trained network. Our results, obtained from a extensive experimental setup show a significant improvement in accuracy in the miniImagenNet benchmark compared to other metric-based few-shot learning methods by a margin of 2%, demonstrating the capability of these loss functions to allow the network to generalize better to previously unseen classes. In our experiments, we demonstrate competitive generalization capabilities to other domains, such as the Caltech CUB, Dogs and Cars datasets compared with the state of the art.
Guided Deep Metric Learning
Jun 04, 2022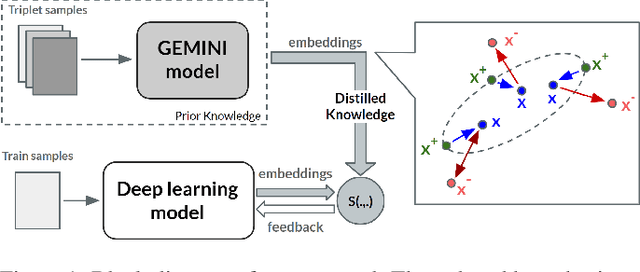
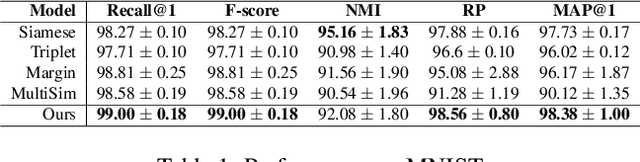
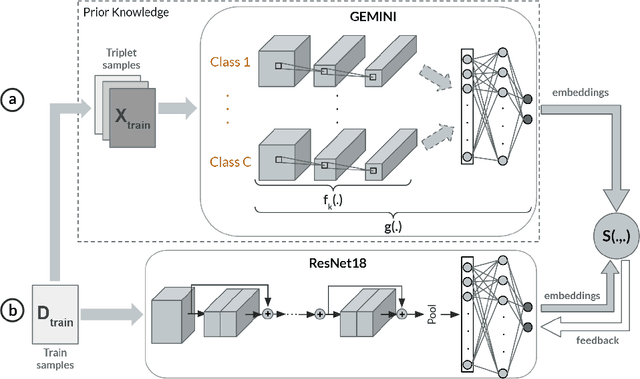

Deep Metric Learning (DML) methods have been proven relevant for visual similarity learning. However, they sometimes lack generalization properties because they are trained often using an inappropriate sample selection strategy or due to the difficulty of the dataset caused by a distributional shift in the data. These represent a significant drawback when attempting to learn the underlying data manifold. Therefore, there is a pressing need to develop better ways of obtaining generalization and representation of the underlying manifold. In this paper, we propose a novel approach to DML that we call Guided Deep Metric Learning, a novel architecture oriented to learning more compact clusters, improving generalization under distributional shifts in DML. This novel architecture consists of two independent models: A multi-branch master model, inspired from a Few-Shot Learning (FSL) perspective, generates a reduced hypothesis space based on prior knowledge from labeled data, which guides or regularizes the decision boundary of a student model during training under an offline knowledge distillation scheme. Experiments have shown that the proposed method is capable of a better manifold generalization and representation to up to 40% improvement (Recall@1, CIFAR10), using guidelines suggested by Musgrave et al. to perform a more fair and realistic comparison, which is currently absent in the literature
On the generalization capabilities of FSL methods through domain adaptation: a case study in endoscopic kidney stone image classification
May 02, 2022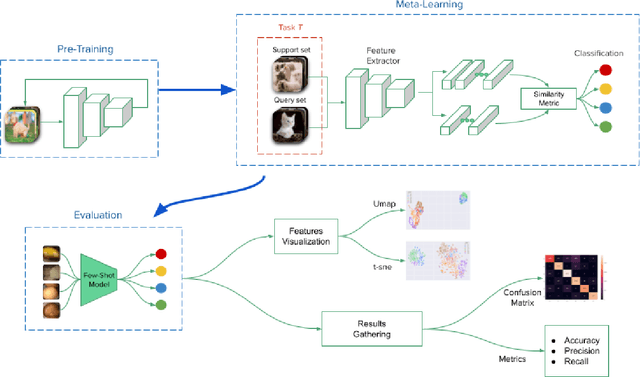
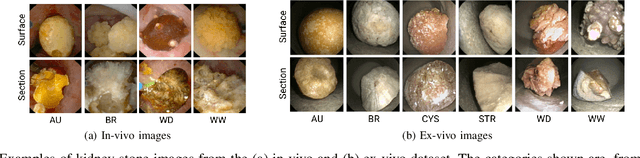
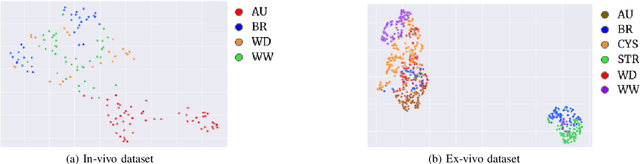
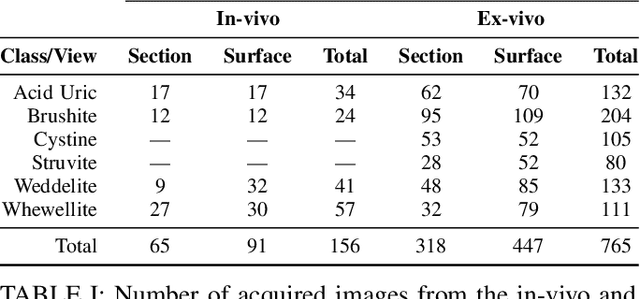
Deep learning has shown great promise in diverse areas of computer vision, such as image classification, object detection and semantic segmentation, among many others. However, as it has been repeatedly demonstrated, deep learning methods trained on a dataset do not generalize well to datasets from other domains or even to similar datasets, due to data distribution shifts. In this work, we propose the use of a meta-learning based few-shot learning approach to alleviate these problems. In order to demonstrate its efficacy, we use two datasets of kidney stones samples acquired with different endoscopes and different acquisition conditions. The results show how such methods are indeed capable of handling domain-shifts by attaining an accuracy of 74.38% and 88.52% in the 5-way 5-shot and 5-way 20-shot settings respectively. Instead, in the same dataset, traditional Deep Learning (DL) methods attain only an accuracy of 45%.
Finding Significant Features for Few-Shot Learning using Dimensionality Reduction
Jul 06, 2021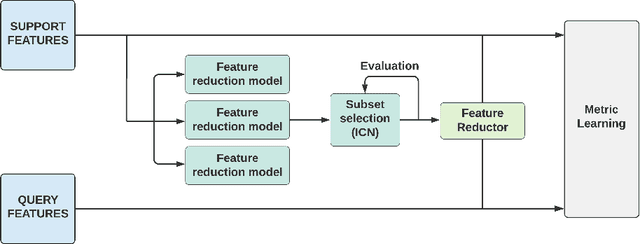
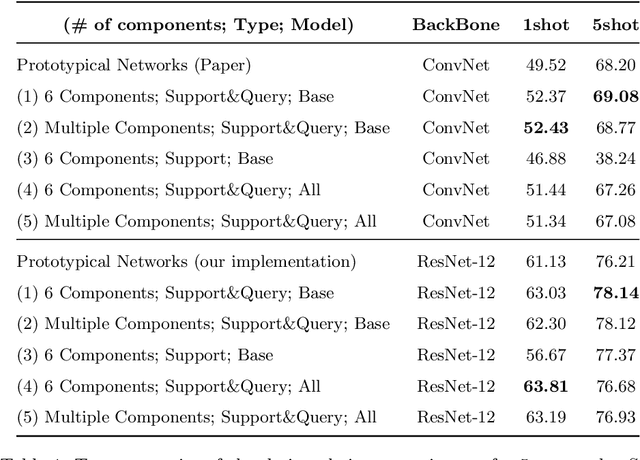
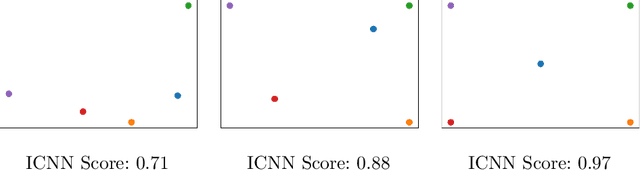
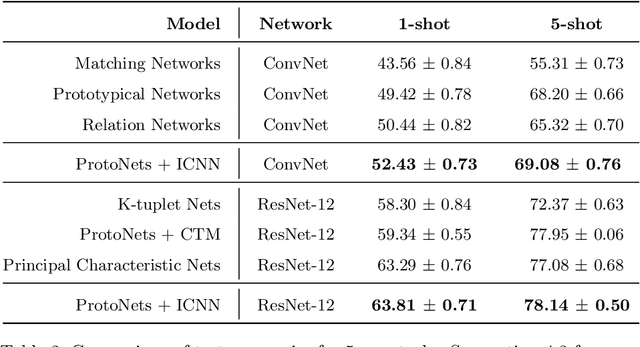
Few-shot learning is a relatively new technique that specializes in problems where we have little amounts of data. The goal of these methods is to classify categories that have not been seen before with just a handful of samples. Recent approaches, such as metric learning, adopt the meta-learning strategy in which we have episodic tasks conformed by support (training) data and query (test) data. Metric learning methods have demonstrated that simple models can achieve good performance by learning a similarity function to compare the support and the query data. However, the feature space learned by a given metric learning approach may not exploit the information given by a specific few-shot task. In this work, we explore the use of dimension reduction techniques as a way to find task-significant features helping to make better predictions. We measure the performance of the reduced features by assigning a score based on the intra-class and inter-class distance, and selecting a feature reduction method in which instances of different classes are far away and instances of the same class are close. This module helps to improve the accuracy performance by allowing the similarity function, given by the metric learning method, to have more discriminative features for the classification. Our method outperforms the metric learning baselines in the miniImageNet dataset by around 2% in accuracy performance.