 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPO: We won't get fooled again
Aug 04, 2022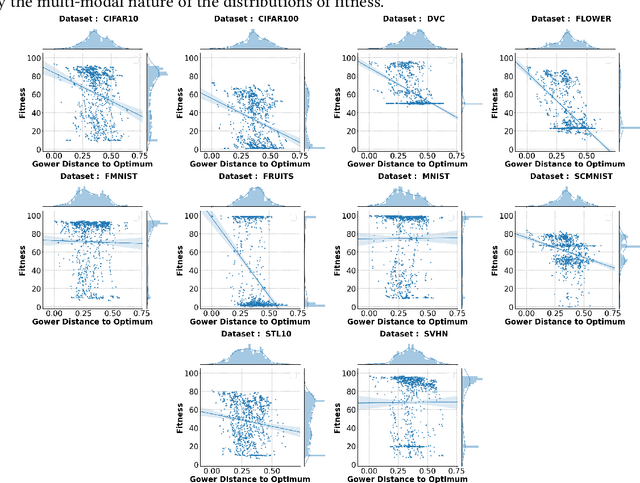
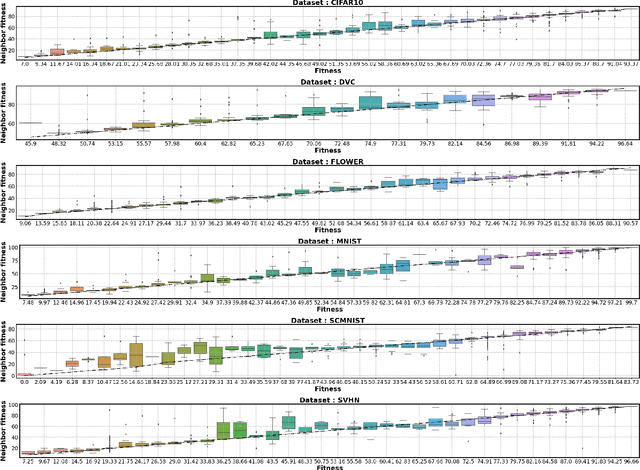
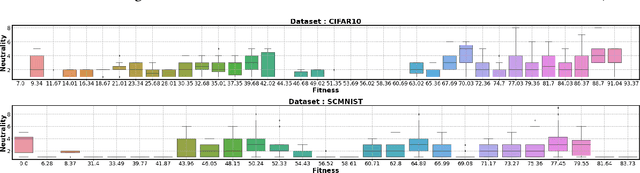
Hyperparameter optimization (HPO) is a well-studied research field. However, the effects and interactions of the components in an HPO pipeline are not yet well investigated. Then, we ask ourselves: can the landscape of HPO be biased by the pipeline used to evaluate individual configurations? To address this question, we proposed to analyze the effect of the HPO pipeline on HPO problems using fitness landscape analysis. Particularly, we studied the DS-2019 HPO benchmark data set, looking for patterns that could indicate evaluation pipeline malfunction, and relate them to HPO performance. Our main findings are: (i) In most instances, large groups of diverse hyperparameters (i.e., multiple configurations) yield the same ill performance, most likely associated with majority class prediction models; (ii) in these cases, a worsened correlation between the observed fitness and average fitness in the neighborhood is observed, potentially making harder the deployment of local-search based HPO strategies. Finally, we concluded that the HPO pipeline definition might negatively affect the HPO landscape.
DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation
Mar 23, 2022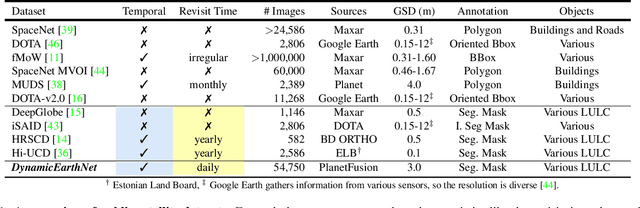
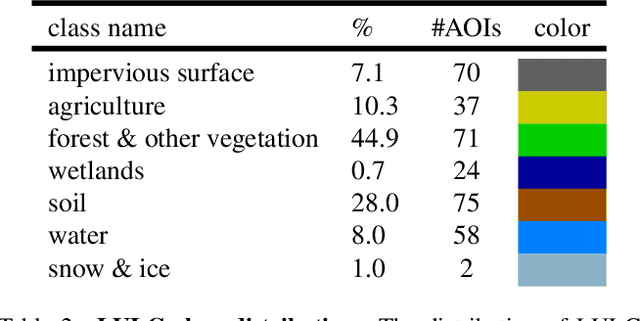

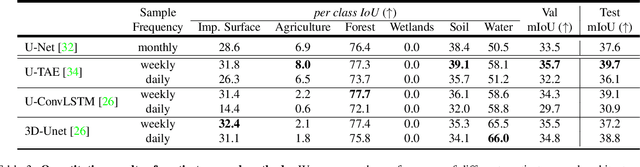
Earth observation is a fundamental tool for monitoring the evolution of land use in specific areas of interest. Observing and precisely defining change, in this context, requires both time-series data and pixel-wise segmentations. To that end, we propose the DynamicEarthNet dataset that consists of daily, multi-spectral satellite observations of 75 selected areas of interest distributed over the globe with imagery from Planet Labs. These observations are paired with pixel-wise monthly semantic segmentation labels of 7 land use and land cover (LULC) classes. DynamicEarthNet is the first dataset that provides this unique combination of daily measurements and high-quality labels. In our experiments, we compare several established baselines that either utilize the daily observations as additional training data (semi-supervised learning) or multiple observations at once (spatio-temporal learning) as a point of reference for future research. Finally, we propose a new evaluation metric SCS that addresses the specific challenges associated with time-series semantic change segmentation. The data is available at: https://mediatum.ub.tum.de/1650201.
Landscape of Neural Architecture Search across sensors: how much do they differ ?
Jan 20, 2022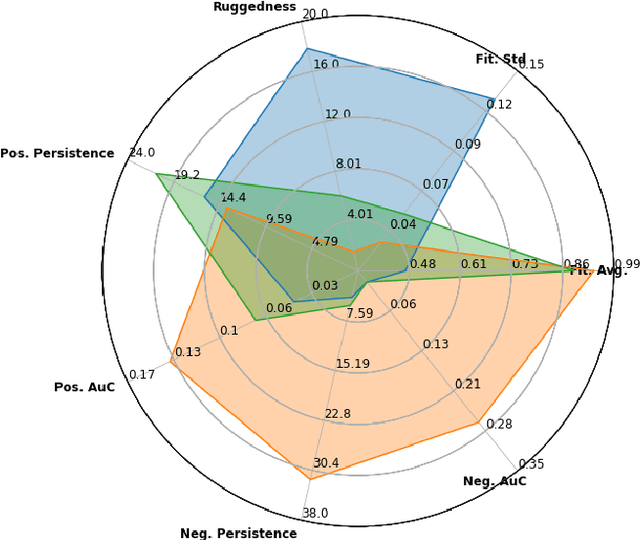
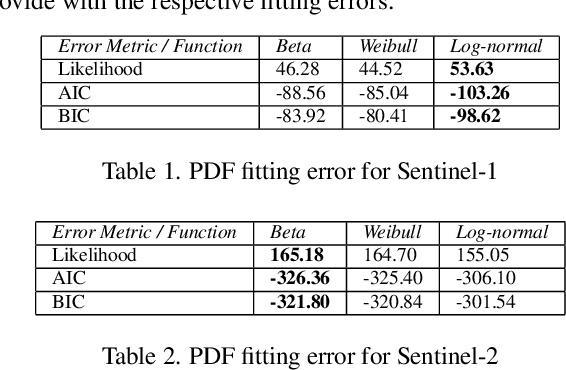

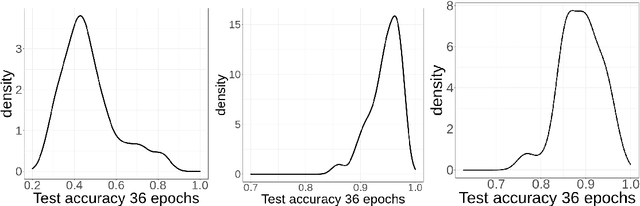
With the rapid rise of neural architecture search, the ability to understand its complexity from the perspective of a search algorithm is desirable. Recently, Traor\'e et al. have proposed the framework of Fitness Landscape Footprint to help describe and compare neural architecture search problems. It attempts at describing why a search strategy might be successful, struggle or fail on a target task. Our study leverages this methodology in the context of searching across sensors, including sensor data fusion. In particular, we apply the Fitness Landscape Footprint to the real-world image classification problem of So2Sat LCZ42, in order to identify the most beneficial sensor to our neural network hyper-parameter optimization problem. From the perspective of distributions of fitness, our findings indicate a similar behaviour of the search space for all sensors: the longer the training time, the larger the overall fitness, and more flatness in the landscapes (less ruggedness and deviation). Regarding sensors, the better the fitness they enable (Sentinel-2), the better the search trajectories (smoother, higher persistence). Results also indicate very similar search behaviour for sensors that can be decently fitted by the search space (Sentinel-2 and fusion).
A Data-driven Approach to Neural Architecture Search Initialization
Nov 05, 2021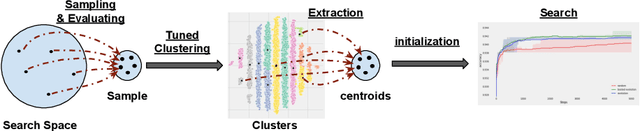

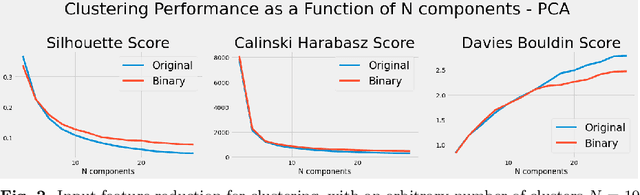
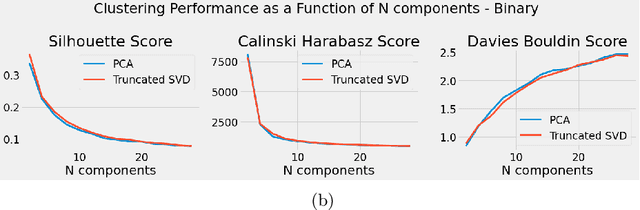
Algorithmic design in neural architecture search (NAS) has received a lot of attention, aiming to improve performance and reduce computational cost. Despite the great advances made, few authors have proposed to tailor initialization techniques for NAS. However, literature shows that a good initial set of solutions facilitate finding the optima. Therefore, in this study, we propose a data-driven technique to initialize a population-based NAS algorithm. Particularly, we proposed a two-step methodology. First, we perform a calibrated clustering analysis of the search space, and second, we extract the centroids and use them to initialize a NAS algorithm. We benchmark our proposed approach against random and Latin hypercube sampling initialization using three population-based algorithms, namely a genetic algorithm, evolutionary algorithm, and aging evolution, on CIFAR-10. More specifically, we use NAS-Bench-101 to leverage the availability of NAS benchmarks. The results show that compared to random and Latin hypercube sampling, the proposed initialization technique enables achieving significant long-term improvements for two of the search baselines, and sometimes in various search scenarios (various training budgets). Moreover, we analyze the distributions of solutions obtained and find that that the population provided by the data-driven initialization technique enables retrieving local optima (maxima) of high fitness and similar configurations.
Fitness Landscape Footprint: A Framework to Compare Neural Architecture Search Problems
Nov 02, 2021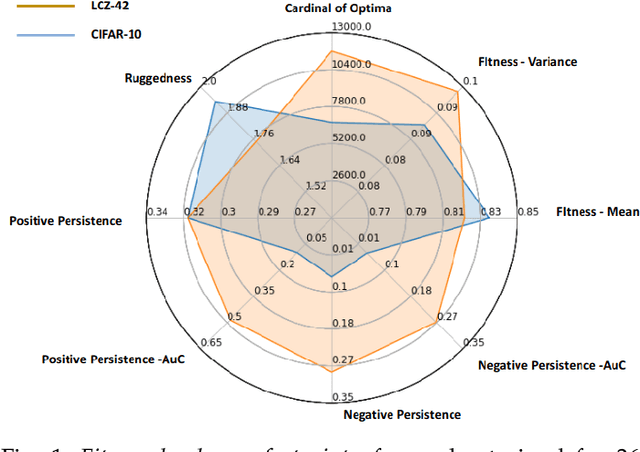
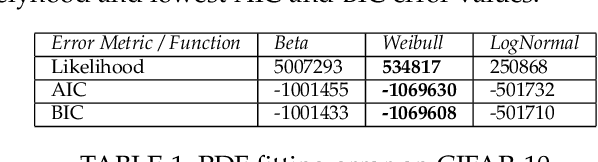

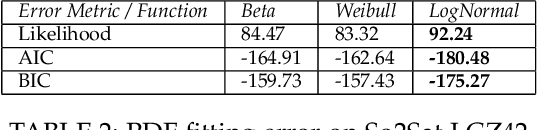
Neural architecture search is a promising area of research dedicated to automating the design of neural network models. This field is rapidly growing, with a surge of methodologies ranging from Bayesian optimization,neuroevoltion, to differentiable search, and applications in various contexts. However, despite all great advances, few studies have presented insights on the difficulty of the problem itself, thus the success (or fail) of these methodologies remains unexplained. In this sense, the field of optimization has developed methods that highlight key aspects to describe optimization problems. The fitness landscape analysis stands out when it comes to characterize reliably and quantitatively search algorithms. In this paper, we propose to use fitness landscape analysis to study a neural architecture search problem. Particularly, we introduce the fitness landscape footprint, an aggregation of eight (8)general-purpose metrics to synthesize the landscape of an architecture search problem. We studied two problems, the classical image classification benchmark CIFAR-10, and the Remote-Sensing problem So2Sat LCZ42. The results present a quantitative appraisal of the problems, allowing to characterize the relative difficulty and other characteristics, such as the ruggedness or the persistence, that helps to tailor a search strategy to the problem. Also, the footprint is a tool that enables the comparison of multiple problems.
Lessons from the Clustering Analysis of a Search Space: A Centroid-based Approach to Initializing NAS
Aug 20, 2021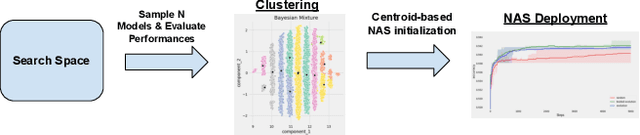

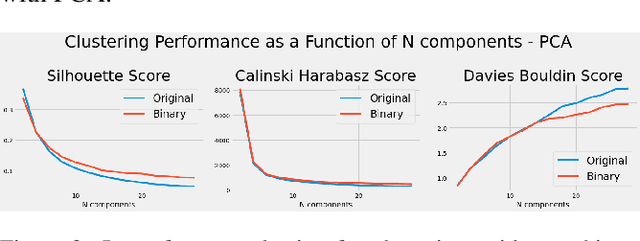
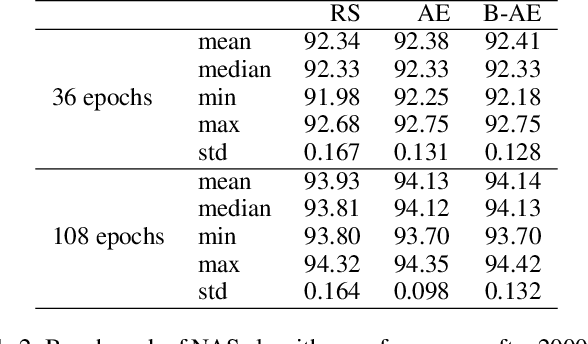
Lots of effort in neural architecture search (NAS) research has been dedicated to algorithmic development, aiming at designing more efficient and less costly methods. Nonetheless, the investigation of the initialization of these techniques remain scare, and currently most NAS methodologies rely on stochastic initialization procedures, because acquiring information prior to search is costly. However, the recent availability of NAS benchmarks have enabled low computational resources prototyping. In this study, we propose to accelerate a NAS algorithm using a data-driven initialization technique, leveraging the availability of NAS benchmarks. Particularly, we proposed a two-step methodology. First, a calibrated clustering analysis of the search space is performed. Second, the centroids are extracted and used to initialize a NAS algorithm. We tested our proposal using Aging Evolution, an evolutionary algorithm, on NAS-bench-101. The results show that, compared to a random initialization, a faster convergence and a better performance of the final solution is achieved.
Reliable and Fast Recurrent Neural Network Architecture Optimization
Jun 29, 2021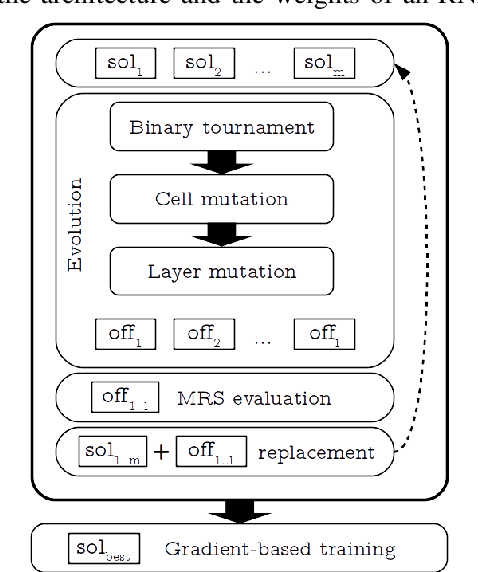
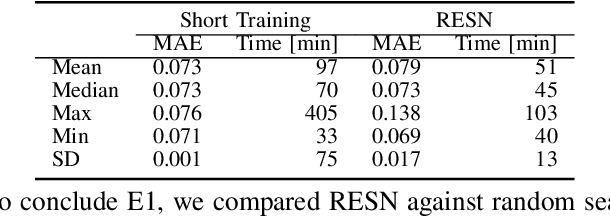
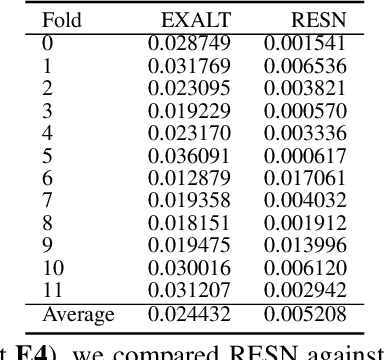

This article introduces Random Error Sampling-based Neuroevolution (RESN), a novel automatic method to optimize recurrent neural network architectures. RESN combines an evolutionary algorithm with a training-free evaluation approach. The results show that RESN achieves state-of-the-art error performance while reducing by half the computational time.
Bayesian Neural Architecture Search using A Training-Free Performance Metric
Jan 29, 2020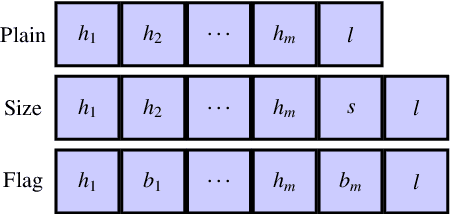


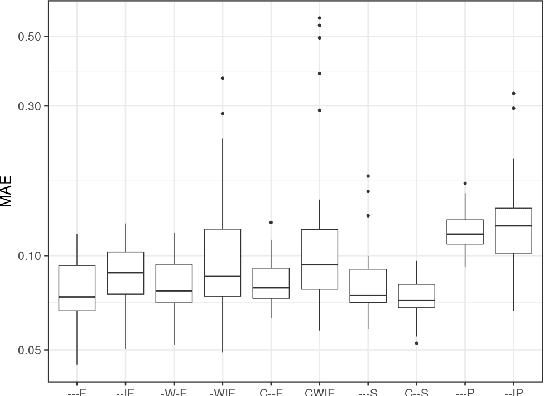
Recurrent neural networks (RNNs) are a powerful approach for time series prediction. However, their performance is strongly affected by their architecture and hyperparameter settings. The architecture optimization of RNNs is a time-consuming task, where the search space is typically a mixture of real, integer and categorical values. To allow for shrinking and expanding the size of the network, the representation of architectures often has a variable length. In this paper, we propose to tackle the architecture optimization problem with a variant of the Bayesian Optimization (BO) algorithm. To reduce the evaluation time of candidate architectures the Mean Absolute Error Random Sampling (MRS), a training-free method to estimate the network performance, is adopted as the objective function for BO. Also, we propose three fixed-length encoding schemes to cope with the variable-length architecture representation. The result is a new perspective on accurate and efficient design of RNNs, that we validate on three problems. Our findings show that 1) the BO algorithm can explore different network architectures using the proposed encoding schemes and successfully designs well-performing architectures, and 2) the optimization time is significantly reduced by using MRS, without compromising the performance as compared to the architectures obtained from the actual training procedure.
JSDoop and TensorFlow.js: Volunteer Distributed Web Browser-Based Neural Network Training
Oct 12, 2019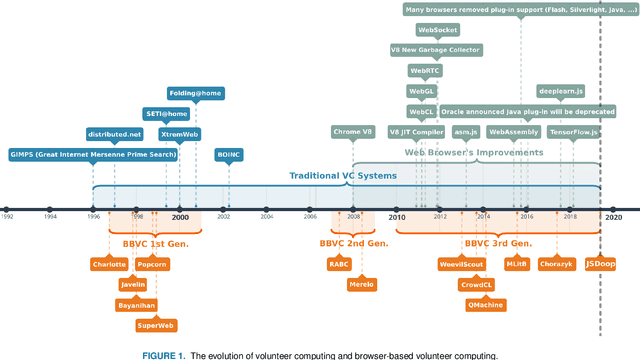
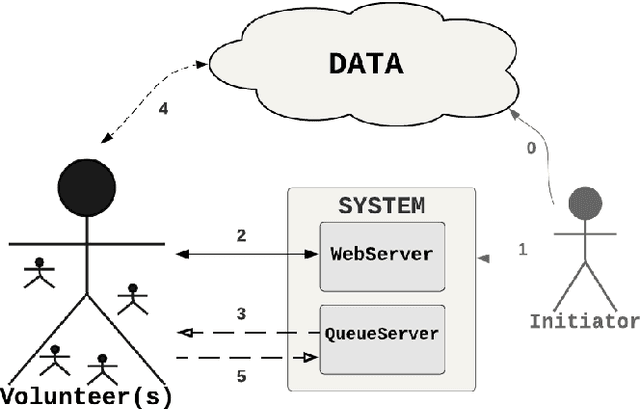

In 2019, around 57\% of the population of the world has broadband access to the Internet. Moreover, there are 5.9 billion mobile broadband subscriptions, i.e., 1.3 subscriptions per user. So there is an enormous interconnected computational power held by users all around the world. Also, it is estimated that Internet users spend more than six and a half hours online every day. But in spite of being a great amount of time, those resources are idle most of the day. Therefore, taking advantage of them presents an interesting opportunity. In this study, we introduce JSDoop, a prototype implementation to profit from this opportunity. In particular, we propose a volunteer web browser-based high-performance computing library. JSdoop divides a problem into tasks and uses different queues to distribute the computation. Then, volunteers access the web page of the problem and start processing the tasks in their web browsers. We conducted a proof-of-concept using our proposal and TensorFlow.js to train a recurrent neural network that predicts text. We tested it in a computer cluster and with up to 32 volunteers. The experimental results show that training a neural network in distributed web browsers is feasible and accurate, has a high scalability, and it is an interesting area for research.
A Specialized Evolutionary Strategy Using Mean Absolute Error Random Sampling to Design Recurrent Neural Networks
Sep 04, 2019
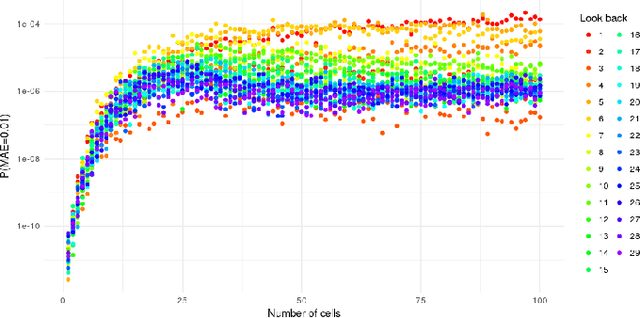
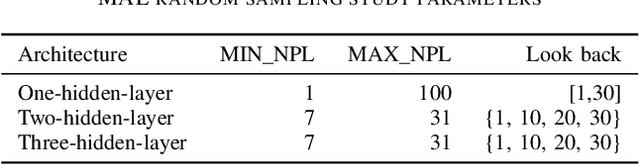
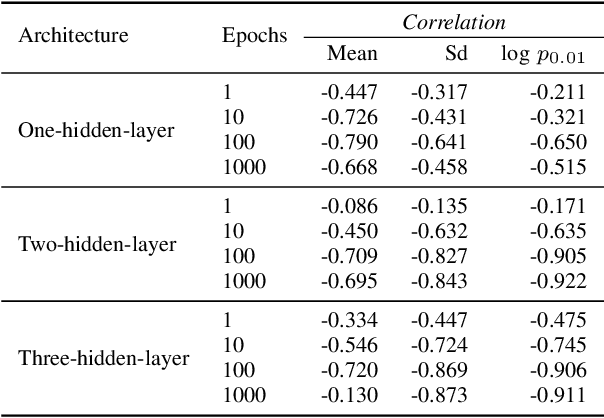
Recurrent neural networks have demonstrated to be good at solving prediction problems. However, finding a network that suits a problem is quite hard because of their high sensitivity to the hyperparameter configuration. Automatic hyperparameter optimization methods help to find the most suitable configuration, but they are not extensively adopted because of their high computational cost. In this work, we study the use of the mean absolute error random sampling to compare multiple-hidden-layer architectures and propose an evolutionary strategy-based algorithm that uses its results to optimize the configuration of a recurrent network. We empirically validate our proposal and show that it is possible to predict and compare the expected performance of a hyperparameter configuration in a low-cost way, as well as use these predictions to optimize the configuration of a recurrent network.